딥러닝
1.[딥러닝] 손실함수 : Smooth L1 Loss
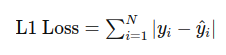
📌 객체 탐지 모델을 공부하다 논문에 Smooth L1 Loss가 자주 나와서 정리해보려 합니다. 하는 김에 L1 loss와 L2 loss도 같이 정리해보겠습니다. 이 손실 함수는 예측값과 실제값 간의 절대적 차이를 계산합니다. L1 Loss는 각 샘플의 예측값과 실
2024년 8월 19일
2.[딥러닝] k-Fold Cross-Validation

📌 최근에 파이토치를 사용하여 논문 리뷰에서 배운 내용을 구현해보았습니다. MNIST나 CIFAR-10 등 파이토치에서 제공하는 데이터셋은 이미 훈련 데이터와 테스트 데이터로 나누어져 있어 따로 분리할 필요가 없었습니다. 그러나 대부분의 경우, 데이터셋을 직접 수집하
2024년 8월 19일
3.[딥러닝] 지식증류(Knowledge Distilation)
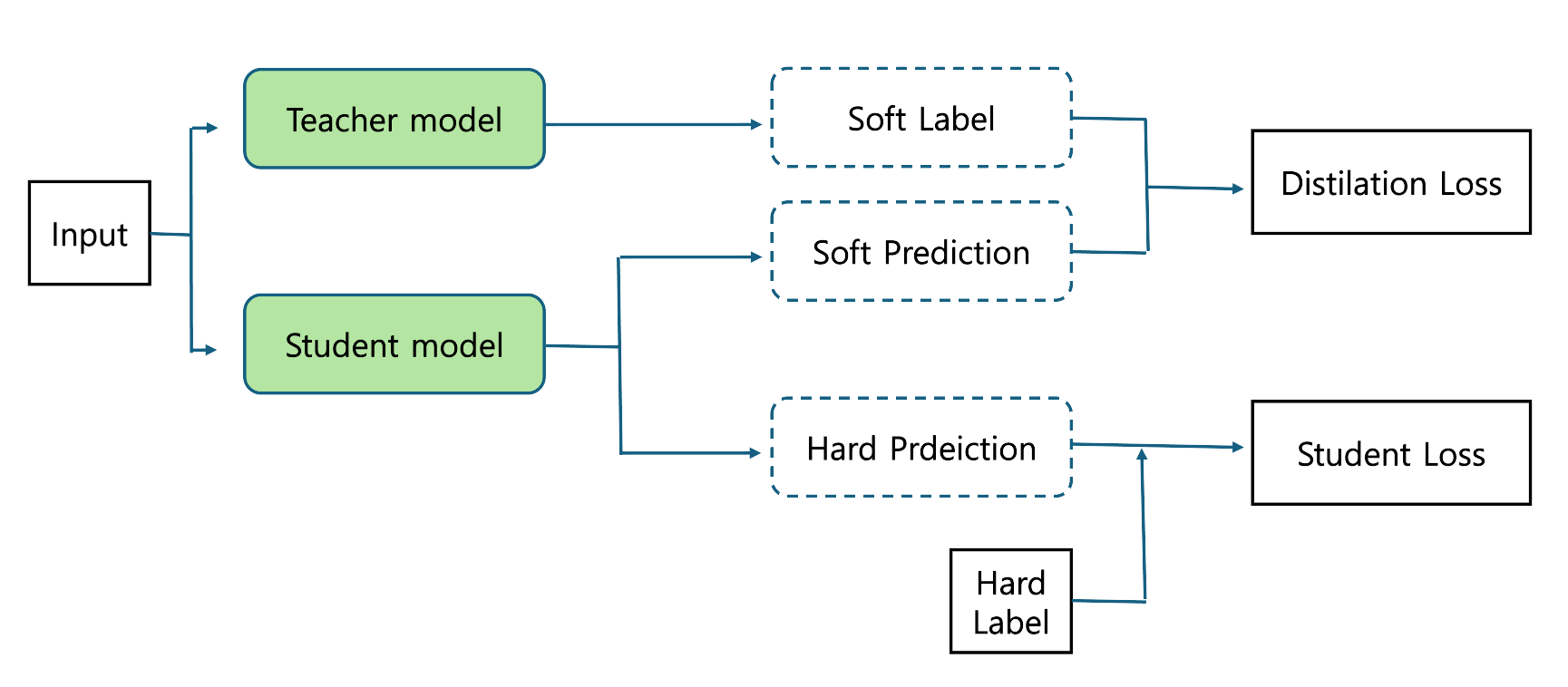
최근 딥러닝 모델은 극도로 복잡하고 거대한 파라미터를 갖는 경향이 있습니다. 이러한 대규모 모델(예: 수십, 수백 개의 레이어를 갖는 DNN, 초거대 언어모델 등)은 뛰어난 성능을 보여주지만, 실제 서비스 환경에서 바로 적용하기 어렵습니다. 서비스 환경에서는 추론
2024년 12월 20일