📌 컴퓨터 비전 분야의 시초라고 할 수 있는 AlexNet에 대해 리뷰해 보려고 합니다. 이 논문을 읽으시는 분들은 아마 딥러닝에 대해 논문을 읽는 첫 단계일 겁니다. 그렇기에 기본적인 용어에 대해서 자세히 설명하도록 노력해보겠습니다.
2012년 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 에서 최초로 CNN을 베이스로 우승을 한 AlexNet은 딥러닝 발전에 아주 큰 영향을 주었다고 해도 과언이 아닙니다.
ILSVRC 대회는 1000개의 클래스를 가진 이미지를 분류하는 대회입니다. 매우 큰 데이터셋을 가지고 모델을 학습 시키는데 CNN이 아주 효과적이다는 걸 증명해낸 것이죠. 특히 Gpu를 사용했다는 점이 주목할 만 합니다.
💡Abstract
2010년 ILSVRC 대회의 1.2 millon의 아주 큰 이미지 데이터를 학습 시키기 위한 deep-convoultion-neural-network를 설계했다. 1000개의 클래스를 가지고 있으며, top-1 and top5 error rate에서 각각 37.5%, 17.0%를 달성했다. 이는 이전 모델들보다 훨씬 좋은 성능을 가지고 있다.
60 million개의 파라미터와 650,000개의 뉴런, 5개의 Convolution layer로 구성되어 있다. 각 Conv layer의 뒤에는 max-pooling 레이어를 가지며 최종적으로 3개의 fc layer와 softmax로 구성된다. non-saturaing을 사용했으며, 빠른 학습을 위해 Gpu를 사용했다. fc layer에서 과적합(overfitting)를 피하기 위해 최근 개발된 dropout 기법을 사용했다.
1000개의 클래스라는 건 분류할 카테고리의 개수를 의미입니다. 개, 고양이, 자동차 이런 카테고리가 1000개 라는 뜻 입니다.
top-1 and top5 error rate 라고 평가 기준이 2가지가 있습니다.
모델에 이미지를 넣으면 각 카테고리가 정답일 확률이 출력으로 나오게 됩니다. 예를 들어 카테고리가 3개라면 (개:15%, 고양이:35%, 자동차:50%) 이런 식으로 나오죠. ILSVRC의 경우 1000개의 확률이 나오겠네요.
top-1은 그 중에서 가장 높은 확률을 가진 카테고리가 정답일 경우를 말하며, top-5는 가장 높은 확률을 가진 5개의 카테고리를 뽑고 그 안에 정답이 있을 확률을 의미한답니다.5개의 conv layer 뒤에 각각 max-pooling layer가 있다면, 구조는 아래와 같다고 할 수 있겠죠?
- conv1 - max1 - conv2 -max2 .... conv5 - max5 - fc1 - fc2 - fc3 - softmax*
파라미터는 가중치와 편향, 뉴런은 입력 이미지의 개수를 각각 나타내는 것 입니다.
논문에서 non-saturaing을 사용했다고 하는데, 이는 아마도 활성화 함수로 Relu를 사용했다는 걸 의미하는 거라 생각합니다. 기존 활성화 함수인 sigmoid의 경우, 값이 1이나 0으로 수렴하도록 되어있는데, Relu는 0보다 크면 입력 값을 그대로 출력하기 때문에 saturaning이 되지 않는 의미로 사용한 문장 같네요.
-> 해당 내용은 밑에 더 자세히 나오니 그때 알아보도록 하죠.dropout : 모델은 훈련데이터를 학습합니다. 그런데 너무 훈련데이터에 적응한 결과 새로운 이미지에 대해서는 좋은 결과를 내지 못하는 경우가 있습니다. 이를 과적합(overfitting)이라고 하죠. 이런 경우를 해결하기 위해 dropout이라는 기법을 이용합니다. 임의로 훈련한 데이터들을 랜덤하게 없애버리는 거죠. 훈련 데이터를 없앴는데 오히려 정확도가 올라가는 결과가 나온답니다.
💡1. Introduction
모델의 성능을 향상시키기 위해 가능한 많은 데이터셋과 강력한 모델을 사용하며, 과적합을 방지하기 위한 여러 기법들이 사용된다. 최근까지 라벨링이 된 데이터셋의 수는 상대적으로 적었다. 이런 작은 데이터셋은 매우 높은 정확도를 보이는데, Mnist 데이터셋의 경우, 실제 사람이 눈으로 보고 판단한 것과 비슷한 결과를 낼 정도다.
하지만 현실에는 다양한 데이터가 존재하며, 이를 학습하기 위해서는 매우 큰 데이터셋이 필요하다. ImageNet과 같은 커다란 데이터셋이 등장하며 불가능할 것 같던 학습이 가능해졌다.
그러나 ImageNet처럼 큰 데이터셋을 학습시키기 위해서는 그만큼 큰 용량의 모델이 필요하다.
CNN모델은 이런 큰 모델의 학습에서 유용하게 사용될 수 있다. 더 적은 파리미터와 연결로 학습하여 좋은 성능을 낼 수 있다.
상대적으로 효율적인 CNN모델 조차 큰 데이터셋을 학습하기에는 힘든데, 다행히도 GPU가 2D Convolution 연산에 있어 성능이 뛰어나다. 이를 이용해 학습시간을 단축 시켰다.

#위 사진은 Fc layer의 연결을 보여 줍니다. 입력 뉴런이 4개인데 하나의 입력 뉴런마다 출력과 모두 연결이 된 모습이 보이시나요? ImageNet의 경우 1400만개의 이미지가 존재하는데, 그중 하나의 이미지만 해도 몇만개의 뉴런을 가지고 있죠. 그게 저렇게 연결된다고 생각해보세요. 계산 비용이 엄청나게 들 겁니다.
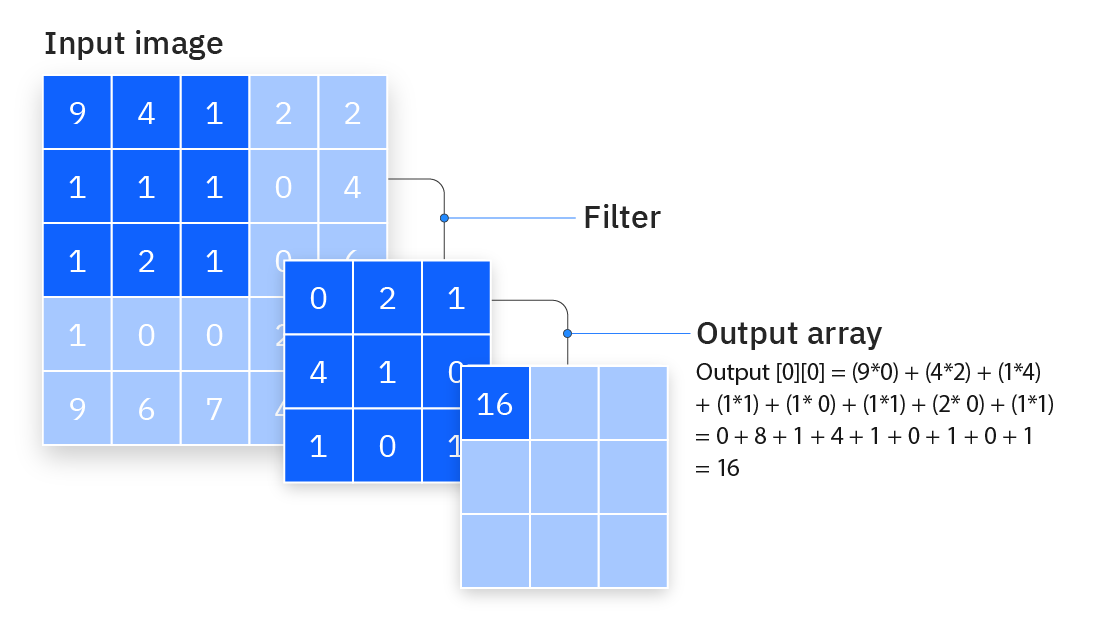
#반면에 convolution layer는 filter가 움직이면서 합성곱을 수행합니다. 따라서 Fc layer처럼 입력 뉴런이 모든 출력에 연결되지 않죠. 이를 통해 파라미터와 계산시간을 절약할 수 있습니다.
💡2. The Dataset
ImageNet은 22,000개의 카테고리가 있다. 사람에 의해 라벨링 되었으며, 그중 ILSVRC는 1000개의 클래스를 사용한다. 훈련데이터 120만개, 검증데이터 50,000개, 테스트 이미지 150,000개로 이루어져있다.
ISLVRC는 테스트 이미지에도 라벨링이 된 유일한 대회이다. ImageNet은 다양한 해상도를 가진 이미지로 구성된 반면, 우리는 고정된 해상도를 필요로 한다. 따라서 ImageNet의 이미지를 256x256의 크기로 다운 샘플링한다. 전처리 과정을 거치지 않으고 트레이닝 데이터셋의 평균을 빼기만 한다. RGB 픽셀 값들로 훈련을 진행했다.
아까 Convoutiol layer 그림을 기억하시나요? 합성곱을 하면 입력 이미지 크기에 따라 출력 이미지의 크기가 다르게 나옵니다. 이를 방지하기 위해 입력 이미지의 크기를 256x256으로 통일 시켜주는 거죠.
입력 이미지 크기가 다양하면 코드로 구현했을 때, 크기마다 코드를 다르게 작성해야 하는 불편함이 있겠죠?
💡3. The Architecture
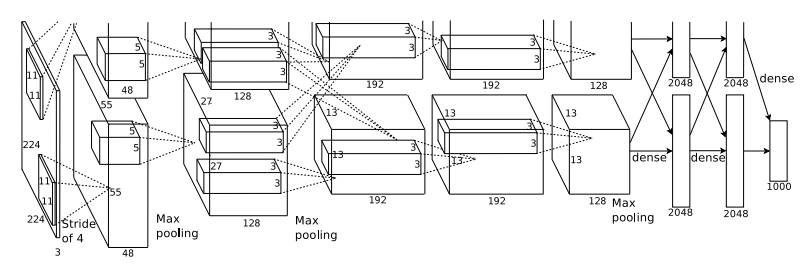
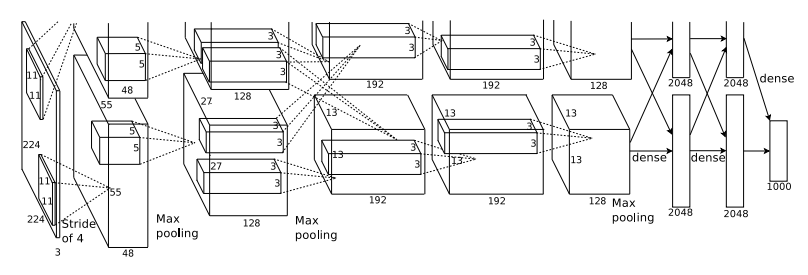
구조를 보면 입력이미지가 필터를 거친 뒤 위 아래로 나눠지는데, 이는 GPU를 2개 사용해서 그렇게 표현한 겁니다.
또한 오른쪽에 표기된 dense는 Fully connected layer와 동일한 뜻 입니다.
3.1 ReLU Nonlinearity
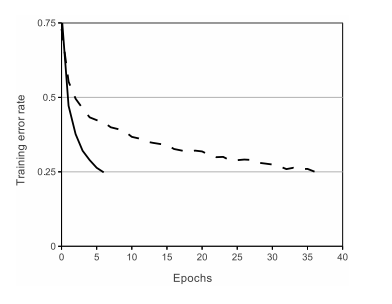
input x를 넣었을 때 f(x) = tanh(x)보다 f(x) = ReLU일 때 더 빠르게 학습을 한다.
3.2 Training on Multiple GPUs
GPU 하나로 학습을 시키기에는 용량이 부족하여 2개의 GPU를 사용했다. 커널을 절반으로 나눠 각각의 GPU에 할당하였다. 따라서 한쪽 GPU에 이미지가 들어가 커널과 연산을 할 수 있지만, 반대쪽 GPU의 커널과는 연산이 불가능하다는 문제점이 있다. 그러나 오히려 이런 구조가 error rate를 낮췄고, 훈련속도도 크게 단축 시킬 수 있었다.
3.3 Local Response Normalization
ReLU는 saturating을 막기 위해 정규화 할 필요가 없다. 그러나 일반화 효과가 된다.
이를 통해 error rate를 각각 1.4%, 1.2% 낮출 수 있었다.
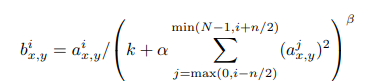
식이 매우 어렵지만, 각 뉴런의 활성화 값이 그 주변 뉴런들과 비교하여 정규화된다는 것 입니다. 위 문장에서 말하는 "일반화 효과"는 LRN이나 다른 정규화 기법이 모델의 일반화 능력을 향상시킬 수 있다는 의미입니다. 모델이 훈련 데이터뿐만 아니라 새로운 데이터에서도 잘 동작하게 만들 수 있다는 거죠.
코드로 작성할 때 저 복잡한 식을 쓸 필요는 없습니다. 파이토치 기준으로
nn.LocalResponseNorm() 위 코드 하나면 충분하거든요. 물론 k값이나 알파, 베타 값을 인수로 넣어주어야 합니다.
사실 요즘은 저 기법을 잘 쓰지 않습니다. Batch normalization이 많이 쓰이고 있죠. 이에 대한 논문도 나중에 기회가 된다면 리뷰해보도록 하겠습니다.
3.4 Overlapping Pooling
CNN에서 풀링은 주변 뉴런의 값을 압축한다. 전통적인 방식은 주변 뉴런들이 겹치지 않도록 풀링을 실행하는데,
우리는 s = 2, z = 3을 오버랩핑 풀링을 한다. 전통적인 s =2, z=2 보다 error rate를 낮출 수 있으며 과적합을 방지한다는 것을 발견했다.
s는 stride, z는 커널 사이즈를 말하는 것 같습니다. stride는 이동하는 거리를 나타내죠.
전통적인 모델들은 커널사이즈와 stride를 2로 둡니다. 이럴경우 입력이미지의 사이즈가 딱 절반이 되거든요.예를 들어 입력이미지가 8x8 사이즈라고 해봅시다.
커널 사이즈는 2x2 입니다. 가로 세로 길이가 2인 정사각형이 2칸씩(stride=2)씩 움직이죠. 이럴 경우 겹치는 면적이 없으며 출력으로 4x4 이미지가 나올겁니다.
하지만 커널 사이즈가 3x3인 정사각형이 2칸씩 움직인다면 겹치게 될 겁니다.논문 저자는 이렇게 겹치는 방식을 사용했다고 하네요.
3.5 Overall Architecture
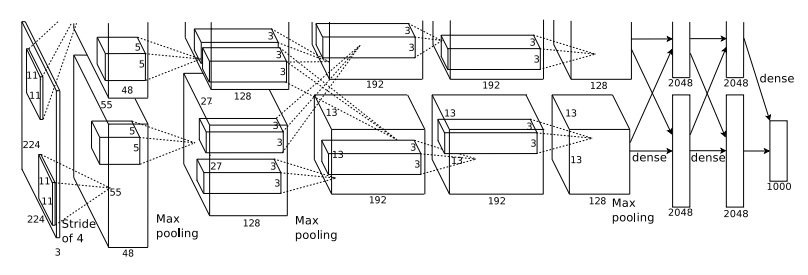
구조는 위에서 이미 다 설명했습니다. 따라서 이미지 사이즈가 어떻게 변하는지 계산하는 과정을 보여드리려고 합니다. 다만 3번째와 4번째 Convolution layer를 지난 뒤에는 Max-Pooling을 하지 않는 점 유의하세요.
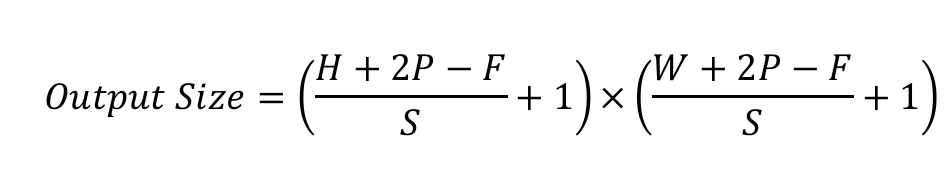
식은 위와 같습니다.
입력 이미지가 224x224 입니다. 필터 사이즈가 11x11이고 스트라이드는 4라고 그림에 나와있네요. 패딩은 없는 것 같습니다. 계산을 해봅시다.
( 224 - 11 ) / 4 + 1 = 54.25 -> 소숫점은 버립니다. 즉, 54x54 feature map이 출력으로 나오네요.🤔 이상합니다. 그림으로 보면 55x55 사이즈의 feature map이 96개(위 아래 48개씩)로 나와야 하는데....
따로 조사해봤는데 사실 입력이미지가 224가 아니라 227이라고 하네요. 논문에 있는 그림이 잘못되었다고 합니다. 논문 저자가 틀렸고 이후 수정되었다네요.
( 227 - 11 ) / 4 + 1 = 55 로 맞게 나오네요.
💡4. Reducing Overfitting
우리의 네트워크 구조는 60 million개의 파라미터를 가지고 있다. 과적합 없이 학습시키는 것은 어렵기에 적절한 조치가 필요하다.
4.1 Data Augmentation
가장 쉽고 흔한 방법은 인공적으로 데이터 셋을 확장하는 것이다. 원본 이미지에서 약간의 변형을 주어 데이터셋을 늘려준다.
첫번째 방법은 256x256에서 랜덤한 영역의 224x224 크기로 추출한다. 또한 이미지를 좌우반전 시켜주는 방식으로 데이터를 증강하였다.
두번째 방법은 RGB 채널 값의 비율을 바꿔주는 것이다.
이미지를 256x256로 바꿔줍니다. 그리고 그 안에서 224x224 크기의 이미지를 랜덤한 위치에서 가져오는거죠. 한 이미지 안에서 여러 위치를 가져올 수 있으니 데이터셋을 크게 증가 시킬 수 있겠네요.
논문에서 RGB 값의 비율을 바꿔주는 식이 아주 복잡하게 되어 있는데, 가우시안 값에 비례해서 뽑는다고 이해하면 될 것 같습니다.
4.2 Dropout
테스트 에러를 효과적으로 줄일 수 있는 드롭아웃은 0.5의 확률로 뉴런의 값을 0으로 만든다. 드롭아웃을 하는 과정에서 순전파와 역전파에 관여하지 않기 때문에 계산 비용이 필요 없다.
💡5. Details of learning
batch size : 128
momentum : 0.9
weight decay : 0.00005
가중치 초기값 : 평균 0, 표준편차 0.01인 가우시안 분포
편향 : 2, 4, 5번째 convolution layer와 fully connected layer의 바이어스는 1로 설정하고 나머지 레이어는 0
learning rate : 0.01로 하되 학습동안 val_error가 변하지 않으면 0.1씩 곱함.
학습 동안 총 3번 곱해졌다.
이 뒤 내용은 논문 저자가 대회에서 어떤 결과가 나왔는지에 대한 내용들 이므로 생략하도록 하겠습니다.
📌 finish
CNN 레이어 5개와 FC 레이어 3개만으로 이미지를 분류해냈습니다. 이후 나오는 거의 모든 모델들이 CNN을 사용한다는 점에서 아주 중요한 논문이라고 할 수 있겠네요.
사실 CNN으로 학습한다는 생각은 AlexNet이 발표되기 훨씬 이전에 나왔답니다. 제가 알기로는 1900년대 후반인걸로 알고 있어요.
AlexNet이 2012년에 CNN을 사용해 대회에서 처음으로 우승한걸 보면 왜 이제서야 CNN을 사용했나 하는 생각이 드실 겁니다.
그 이유는 컴퓨터의 성능 때문입니다. CNN을 계산할 수 있는 성능이 나오질 못해서 기술적 제약이 있었죠.
하지만 기술이 발전하면서 GPU 같은 가속기를 사용하여 병렬처리를 할 수 있게 되었죠.
제가 이 분야를 공부하고 처음으로 논문을 코드로 구현했을 때, 코드가 잘못되어 GPU가 아닌 CPU로 돌아간적이 있는데, 학습속도가 정말 느립니다. 그런점에서 GPU의 성능이 얼마나 대단한지 느낄 수 있었죠.
위 링크는 제 깃허브 링크입니다. AlexNet 모델을 파이토치로 구현했습니다. 모델을 정의한 파일과 훈련 코드를 분리하여 작성하였기 때문에 모델 구조를 공부하기 편하실 겁니다. AlexNet 이외에도 유명한 논문들을 계속 구현해보고 있으니 다른 것들도 이용해보시면 좋을 듯 합니다.
- README.md 파일을 읽고 적혀있는데로 실행해주시면 훈련을 하고 결과를 저장할 수 있습니다.
