📌 VIT의 경우 CNN의 성능을 뛰어넘기 위해서는 많은 데이터셋으로 학습을 시켜야 한다는 단점이 있습니다. 그렇다면 자가지도 학습을 VIT에 적용한다면, 이런 문제를 해결할 수 있지 않을까요?
💡Abstract
본 논문에서는 자기지도 학습(self-supervised learning)이 Vision Transformer(ViT)에 합성곱 신경망과 비교했을 때 어떤 새로운 특성을 부여하는지에 대해 고찰합니다.
자기지도 학습 방법을 ViT 아키텍처에 적용하는 것이 특히 효과적이라는 점을 넘어서, 다음과 같은 두 가지 주요 관찰을 제시합니다.
-
첫째, 자기지도 학습을 통해 얻은 ViT의 특징은 이미지의 의미적 분할(semantic segmentation)에 대한 명확한 정보를 포함하고 있으며, 이는 지도 학습된 ViT나 convnets에서는 뚜렷하게 나타나지 않습니다.
-
둘째, 이러한 특징은 소형 ViT에서도 ImageNet 데이터셋에서 78.3%의 top-1 정확도를 달성하는 뛰어난 k-NN 분류기로 작용합니다.
또한 본 연구는 모멘텀 인코더, 멀티 크롭 학습, 그리고 ViT와 함께 사용하는 작은 패치의 중요성을 강조합니다. 이러한 발견을 바탕으로, 우리는 DINO라는 간단한 자기지도 학습 방법을 구현하였으며, 이를 레이블 없이 수행되는 자기 증류(self-distillation)의 한 형태로 해석합니다.
DINO와 ViT의 시너지를 입증하기 위해, ViT-Base를 사용한 선형 평가에서 ImageNet 데이터셋에서 80.1%의 top-1 정확도를 달성하였습니다.
💡1. Introduction
최근 Transformers 모델이 시각 인식 분야에서 기존의 CNN의 대안으로 떠오르고 있습니다. 트랜스포머는 자연어 처리(NLP)에서 영감을 받은 학습 전략을 사용하여 대량의 데이터를 먼저 학습(pretraining)하고, 그 후에 특정 작업을 위해 미세 조정(finetuning)합니다.
이를 통해 생성된 Vision Transformers는 CNN와 경쟁력 있는 성능을 보이지만, 아직까지는 몇 가지 면에서 convnets보다 뚜렷한 장점을 제공하지 못하고 있습니다.
예를 들어, 트랜스포머는 계산 비용이 더 많이 들고, 더 많은 학습 데이터가 필요하며, 그들이 추출한 특징이 특별한 속성을 가지지 않습니다.
본 논문에서는 트랜스포머가 시각 분야에서 충분히 성공하지 못한 이유가 사전 학습 시 감독(supervision)을 사용한 것 때문인지에 대해 의문을 제기합니다.
NLP에서 트랜스포머가 성공할 수 있었던 주요 이유 중 하나는 BERT의 마스크 예측 방식이나 GPT의 언어 모델링과 같은 자기지도 학습(self-supervised pretraining)을 사용했기 때문입니다. 자기지도 학습 방법은 문장의 단어들을 활용하여 더 풍부한 학습 신호를 제공하는 과제를 생성함으로써, 문장당 단일 레이블을 예측하는 감독 학습보다 더 효과적입니다.
마찬가지로, 이미지에서도 이미지 전체를 하나의 개념으로 축소하는 감독 학습은 이미지에 담긴 풍부한 시각 정보를 충분히 활용하지 못할 수 있습니다.
본 연구에서는 자기지도 학습이 Vision Transformer(ViT)의 특징에 어떤 영향을 미치는지 조사합니다. 특히, 우리는 지도 학습된 ViT나 convnets에서는 나타나지 않는 몇 가지 흥미로운 특성을 발견했습니다.

-
장면 레이아웃과 객체 경계 정보 : 자기지도 학습된 ViT는 이미지의 장면 레이아웃과 특히 객체의 경계에 대한 명확한 정보를 포함하고 있습니다. 이는 그림 1에서 볼 수 있듯이, 마지막 블록의 self-attention 모듈에서 직접 확인할 수 있습니다.
-
우수한 k-NN 성능 : 자기지도 학습된 ViT의 특징은 미세 조정이나 선형 분류기 없이도 기본적인 최근접 이웃 분류기(k-NN)에서 매우 우수한 성능을 보이며, ImageNet 데이터셋에서 78.3%의 top-1 정확도를 달성합니다.
그러나 k-NN에서의 우수한 성능은 모멘텀 인코더와 멀티 크롭 증강과 같은 특정 구성 요소를 결합할 때만 나타납니다. 또한, ViT와 함께 작은 패치를 사용하는 것이 결과 특징의 품질을 향상시키는 데 중요하다는 점도 발견했습니다.
이러한 발견을 바탕으로, 우리는 레이블 없이 지식 증류(self-distillation)의 한 형태로 해석될 수 있는 단순한 자기지도 학습 접근법인 DINO를 설계했습니다.
DINO 프레임워크는 모멘텀 인코더를 사용하여 교사 네트워크의 출력을 직접 예측함으로써, 표준 교차 엔트로피 손실을 사용하는 방식으로 자기지도 학습을 단순화합니다.
흥미롭게도, DINO는 교사 출력의 중심화와 샤프닝만으로도 붕괴를 방지할 수 있으며, 예측기, 고급 정규화, 대조 손실과 같은 다른 인기 있는 구성 요소는 안정성이나 성능 측면에서 큰 이점을 추가하지 않습니다. 특히, 우리의 프레임워크는 아키텍처를 수정하거나 내부 정규화를 조정할 필요 없이 convnets과 ViT 모두에서 유연하게 작동합니다.
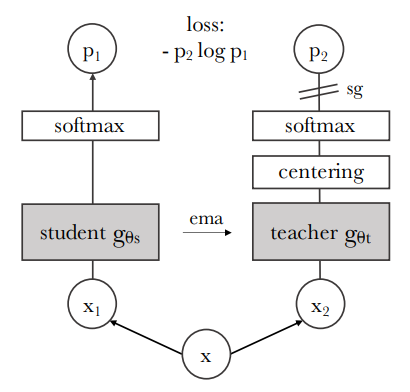
모델은 입력 이미지의 두 가지 다른 무작위 변환을 학생 네트워크와 교사 네트워크에 전달합니다. 두 네트워크는 동일한 아키텍처를 가지지만 파라미터는 다릅니다. 교사 네트워크의 출력은 배치 전체에서 계산된 평균으로 중심화됩니다. 각 네트워크는 특징 차원에 대한 온도 소프트맥스를 통해 정규화된 K 차원의 특징을 출력합니다.
그들의 유사성은 교차 엔트로피 손실로 측정됩니다. 우리는 교사에 대해 그라디언트를 전파하지 않기 위해 교사에 stop-gradient 연산자를 적용합니다. 교사 파라미터는 학생 파라미터의 지수 이동 평균(ema)으로 업데이트됩니다.
💡3. Approach
-
이미지 변형 생성: 주어진 이미지에서 여러 가지 변형된 뷰(예: 크롭된 이미지)를 생성합니다. 이때, 두 개의 전역 뷰(global view)와 여러 개의 국소 뷰(local view)를 만듭니다.
-
네트워크에 입력: 생성된 모든 변형된 이미지는 학생 네트워크에 입력되지만, 교사 네트워크에는 전역 뷰만 입력됩니다. 이는 학생 네트워크가 국소 정보와 전역 정보를 연결할 수 있도록 돕습니다.
-
손실 계산 및 역전파: 학생 네트워크의 출력이 교사 네트워크의 출력과 유사하도록 손실을 계산하고, 이를 기반으로 학생 네트워크를 업데이트합니다. 교사 네트워크의 파라미터는 학생 네트워크의 파라미터를 지수 이동 평균(EMA) 방식으로 업데이트하여 점진적으로 변화합니다.
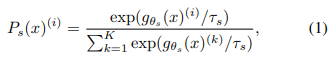
여기서 τ는 temperture를 나타내며, 확률값을 부드럽게 해줍니다. 일반적인 softmax의 경우 정답에만 매우 높은 확률 값을 주고, 나머지에 대해서는 낮은 확률값을 줍니다. 따라서 정답이 아닌 클래스에 대한 정보를 학습하기 위한 값이 너무 작아, 이를 부드럽게 해주기 위해 τ로 나누어줍니다.
하지만 DINO 논문에서는 τ를 작게하여 오히려 날카롭게 만들어 준다고 합니다. 이는 학생 네트워크가 더 명확한 타겟을 따르도록 유도하기 위함 입니다. 지도학습과는 다르게 비지도 학습이라 모델이 스스로 의미 있는 구조를 발견하도록 도와주어야 합니다.

Teacher network
일반적인 지식 증류(Knowledge Distillation)와는 달리, DINO는 사전에 주어진 교사 네트워크를 가지고 있지 않기 때문에, 학생 네트워크의 과거 반복(iterations)으로부터 교사 네트워크를 구축합니다. 섹션 5.2에서는 교사 네트워크를 업데이트하는 다양한 규칙을 연구하고, 한 에폭(epoch) 동안 교사 네트워크를 고정(freeze)하는 방법이 우리 프레임워크에서 예상외로 잘 작동함을 보여줍니다.
반면, 학생 네트워크의 가중치를 교사 네트워크에 그대로 복사하는 방식은 수렴하지 못합니다. 특히, 학생 네트워크의 가중치에 대한 지수 이동 평균(Exponential Moving Average, EMA)을 사용하는 방법, 즉 모멘텀 인코더(momentum encoder)는 우리 프레임워크에 특히 잘 맞습니다. 업데이트 규칙은 다음과 같습니다:
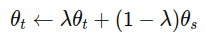
여기서 λ는 학습 기간 동안 0.996에서 1로 변하는 코사인 스케줄(cosine schedule)을 따릅니다. 우리는 이 교사 네트워크가 학습 전반에 걸쳐 학생 네트워크보다 더 나은 성능을 보이며, 따라서 더 높은 품질의 타겟 특징을 제공하여 학생 네트워크의 학습을 안내함을 관찰했습니다.
DINO에서는 사전 학습된 교사 모델이 없고, 대신 학생 모델 자체를 기반으로 교사 모델을 동적으로 생성하고 업데이트합니다.
사전 학습된 교사 모델이 없기 때문에, 교사 모델은 학습 과정 중에 학생 모델의 과거 가중치를 기반으로 지속적으로 업데이트됩니다. 이때 지수 이동 평균(EMA)은 최근 데이터에 더 큰 가중치를 부여하면서, 과거 데이터의 영향을 점진적으로 줄여가는 방식입니다.
이를 통해 사전학습된 교사 모델이 없어도, 교사 모델이 학생 모델 보다 더 좋은 특징을 제공하여 학생모델이 학습할 수 있는 기준을 주게 됩니다.
Avoiding collapse
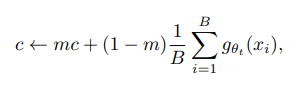
중심화(centering)는 모델이 붕괴(collapse) 되는 것을 방지하기 위한 중요한 메커니즘 중 하나입니다. 붕괴란 모델이 모든 입력에 대해 동일하거나 의미 없는 출력을 생성하는 현상을 말합니다. 이를 방지하기 위해 중심화는 교사 네트워크의 출력 분포를 조정하여 다양한 입력에 대해 일관되고 유의미한 특징을 학습하도록 유도합니다.
이전 중심값에 대한 가중치와, 현재 배치의 교사 네트워크 출력의 평균에 대한 가중치를 일정 비율로 합쳐 새로운 중심값 c가 됩니다.
중심화를 통해 특정 차원이 지나치게 지배적이 되는 것을 방지합니다. 예를 들어, 하나의 차원이 다른 차원들보다 훨씬 큰 값을 가지게 되는 것을 막아줍니다.
논문에서는 중심화와 샤프닝을 동시에 적용했을 때 모델 붕괴를 성공적으로 방지할 수 있음을 실험적으로 입증하였습니다. 특히, 중심화는 한 차원이 지나치게 지배하는 것을 막아주며, 샤프닝은 출력 분포를 뾰족하게 만들어 모델이 다양한 시각적 변형에도 일관된 출력을 생성하도록 유도합니다. 이러한 균형은 모멘텀 인코더가 있는 상황에서도 안정적인 학습을 가능하게 합니다.
Evaluation protocols
자기지도 학습의 표준 프로토콜은 고정된 특징(frozen features)에 대해 선형 분류기(linear classifier)를 학습시키거나, 다운스트림 작업에서 특징을 미세 조정(finetune)하는 것입니다. 선형 평가에서는 학습 중에 랜덤 리사이즈 크롭(random resize crops)과 수평 플립(horizontal flips) 증강을 적용하고, 중앙 크롭(central crop)에서 정확도를 보고합니다. 미세 조정 평가에서는 사전 학습된 가중치로 네트워크를 초기화하고, 학습 중에 이를 조정합니다. 그러나 두 평가 방법 모두 하이퍼파라미터에 민감하며, 학습률을 변경할 때 실행 간 정확도에 큰 변동을 보입니다.
따라서 우리는 간단한 가중 최근접 이웃 분류기(k-NN)를 사용하여 특징의 품질을 평가합니다. 사전 학습된 모델을 고정(freeze)하여 다운스트림 작업의 학습 데이터의 특징을 계산하고 저장합니다. 최근접 이웃 분류기는 이미지의 특징을 저장된 k개의 가장 가까운 특징과 매칭하여 레이블을 투표합니다. 우리는 다양한 k 값을 탐색(sweep)한 결과, 대부분의 실행에서 20 NN이 일관되게 가장 잘 작동함을 발견했습니다. 이 평가 프로토콜은 추가적인 하이퍼파라미터 튜닝이나 데이터 증강을 필요로 하지 않으며, 다운스트림 데이터셋을 한 번만 통과하여 실행할 수 있어 특징 평가를 크게 단순화합니다.

