📌 Object detection을 공부하는 사람이라면 YOLO를 꼭 알아야 하듯, Segmentation 분야를 공부하는 사람이라면 UNet을 모를 수 없는 유명한 모델입니다.
🤷 Segmentation Model?
Computer Vision 분야에서 이미지를 인식하는 분야는 크게 3가지로 나눌 수 있습니다.
- Classification : 이미지를 보고 해당 객체가 무엇인지를 구분하는 작업입니다. 예를 들어, MNIST 데이터셋을 이용해 숫자를 분류하는 작업이 이에 해당합니다. 이 경우, 한 이미지에는 하나의 객체만 존재합니다.
-
Object Detection : 이미지에서 객체의 위치를 Bounding Box로 표시하고, 각 객체가 어떤 클래스에 속하는지 판별하는 작업입니다. 대표적인 모델로는 YOLO가 있습니다. Classification과 달리, 한 이미지에 여러 객체가 있을 수 있습니다.
-
Segmentation : 객체나 특정 영역을 픽셀 단위로 정확하게 분리하는 작업입니다. Object Detection이 객체의 위치를 사각형 박스로 표시하는 반면, Segmentation은 객체의 형태에 맞게 픽셀 단위로 구분하여 색상을 다르게 표시합니다.
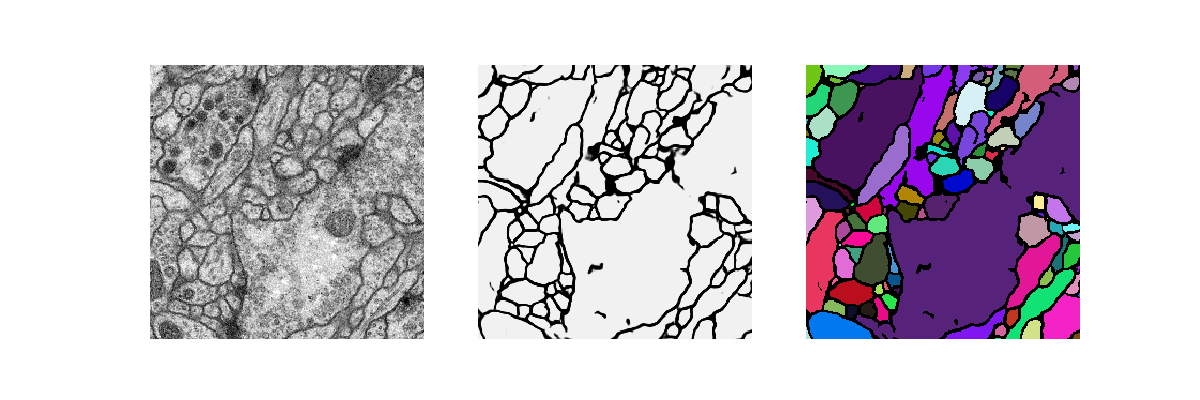
위 이미지가 Segmentation의 예시 입니다.
🙎♂️ 기존 모델과의 차이점
-
슬라이딩 윈도우 방식의 단점 극복 : 기존 방법은 윈도우를 슬라이딩 하여 예측하기 때문에 중복된 계산과 속도 문제를 야기하여, 전체 문맥을 제대로 반영하지 못합니다.
반면, UNet은 down, up 샘플링을 결합한 대칭적인 U자 형태의 CNN 아키텍처를 사용하여, 문맥을 효과적으로 반영하고 더 정밀한 로컬라이제이션을 가능하게 합니다. 이 방식은 각 이미지의 문맥을 보다 잘 활용할 수 있게 합니다. -
풀링 대신 업샘플링을 사용 : 기존 네트워크에서는 풀링 계층을 사용하여 공간 해상도를 낮추고, 이로 인해 로컬라이제이션 정확도가 떨어질 수 있습니다.
제시된 네트워크는 업샘플링 연산자를 사용하여 출력 해상도를 증가시킵니다. 이를 통해 더 높은 해상도의 출력을 생성하면서, 세부적인 위치 정보도 보존됩니다. -
데이터 증강을 통한 훈련 데이터 효율성 증가 : 기존 방법들은 훈련 데이터의 부족으로 성능이 제한적일 수 있습니다. 특히 생물학적 이미지에서 수천 개의 훈련 샘플을 확보하는 것이 어려운 경우가 많습니다.
과도한 데이터 증강을 통해 탄성 변형 등을 사용하여 훈련 데이터를 늘리고, 훈련 샘플의 수가 적어도 효율적으로 학습할 수 있도록 합니다. -
접촉하는 객체 분리 : 기존 방법들은 접촉하는 객체(예: 세포)가 같은 클래스를 가질 경우 이를 분리하는 데 어려움이 있었습니다.
제시된 네트워크는 가중 손실 함수를 사용하여 접촉하는 객체들 사이의 경계를 더 정확하게 구분하도록 돕습니다. 이를 통해 동일 클래스의 접촉하는 객체를 더 정확히 분리할 수 있습니다.
🔶 Architecture
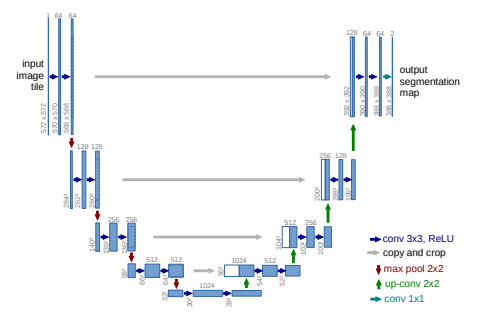
모델의 구조는 사진에서 보이듯이, Max-Pooling을 통해 사이즈를 줄여가며 학습한 뒤, 다시 Up-Sampling 과정을 통해 원본 사이즈로 되돌립니다.
다운 샘플링 과정에서는 채널 수를 늘려주고, 업 샘플링 과정에서는 다시 채널수를 줄여줍니다.
이를 통해 다운 샘플링 과정에서 정보가 손실되지 않게 해줍니다.
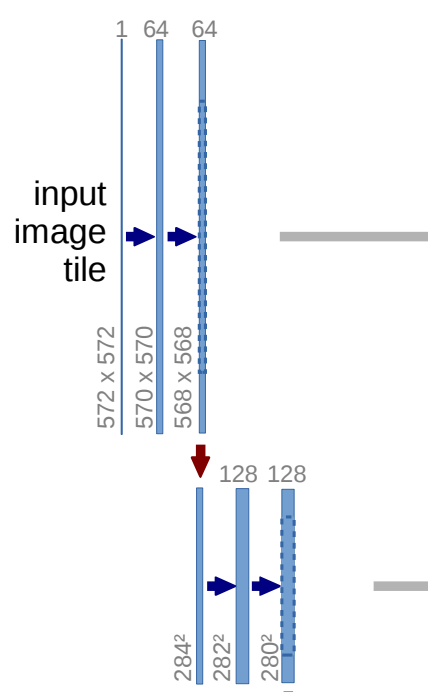
사진을 보시면 입력 사이즈가 572X572 입니다. 두번의 CNN을 거친 뒤 Max Pooling을 해줍니다. 이때 CNN에서 padding을 하지 않기 때문에 사이즈가 2씩 줄어들게 됩니다.

또한 skip connection으로 다운 샘플링 부분과 업샘플링 부분을 Concat하여 합쳐 줍니다. 이때, 사진에서 feature map의 사이즈가 서로 다른걸 알 수 있습니다. 왼쪽에서 284 사이즈 이미지가 두번의 CNN을 통과 후 280이 됩니다. 하지만 오른쪽에서 업샘플링 후 feature map은 200사이즈로 서로 다르기 때문에 Concat을 할 수 없습니다. 따라서 Crop을 하여 280사이즈의 이미지를 200으로 잘라 준 뒤에 합쳐주게 됩니다.
🤷 Input Image?
그럼 여기서 궁금한게 생깁니다. 입력 이미지의 사이즈를 어떻게 주어야 할 까요? 우선 CNN을 통과할 때 마다 사이즈가 2씩 줄어들고, Down Sampling을 하면 사이즈가 절반이 됩니다. 따라서 입력이미지는 반드시 짝수의 크기를 가져야 절반으로 나누는 과정에서 픽셀이 손실되는 일이 발생하지 않습니다.
또한 의료 데이터의 경우 매우 큰 해상도를 가진 경우가 많습니다. 따라서 적당한 크기로 잘라 입력으로 넣어줘야 합니다. 중첩되지 않게 patch 형식으로 잘라 입력으로 넣어줍니다. 이때 모든 patch의 크기가 동일 해야 합니다. 하지만 일정한 크기의 patch가 불가능 할 수도 있습니다.
예를 들어 입력이미지가 10x10의 경우 4x4 사이즈의 patch로 자를 경우 가로 세로 각각 2크기의 픽셀이 남게 됩니다.
논문 저자는 이런 경우 좌우 대칭 패딩을 추가하자는 의견을 제시했습니다.
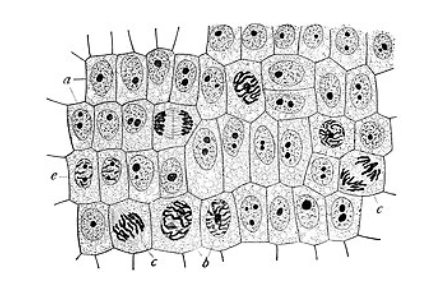
의료 이미지의 경우 위 사진처럼 특정 모양이 반복되는 패턴이 많습니다. 따라서 오른쪽 픽셀의 크기가 부족한 경우 그 픽셀을 좌우 대칭해도 사진에서 처럼 사각형 모양의 세포가 좌우반전되서 나타나기 때문에 실제 모습과 비슷할 것 입니다.
🔶 Data Augmentation & loss
Segmentation은 픽셀 단위의 라벨링이 필요하기 때문에 데이터셋을 구하기 매우 힘듭니다. 따라서 적은 데이터셋을 증강하여 사용합니다. 논문의 저자는 다음과 같은 데이터 증강 기법을 사용했습니다.
① Shift ② Rotation ③ Gray value ④ Elastic Deformation
Elastic Deformation은 랜덤하게 픽셀을 변형시키는 기법입니다.
논문에서 특이한 점은 loss 함수를 구할 때 softmax 후 Crossentropy를 한 값에 픽셀 weight를 곱한 것 입니다.
이 weight는 학습 가중치를 의미하는 게 아니라, 가우시안 분포를 통해 구한 픽셀 마다의 weight를 말합니다. 즉, 가우시안 분포를 통해 이미지에서 경계선을 찾아내고, 이 경계선에 해당하는 픽셀에는 더 큰 loss를 주어 학습을 효과적으로 하겠다는 뜻 입니다.
📌 fin
이 논문은 단순히 세그멘테이션에서 뛰어난 성능을 보여주는 것뿐만 아니라, 참신하고 다양한 기법들을 사용하여 더욱 의미 있는 연구 결과를 제시합니다. 입력 이미지 처리부터 손실 함수, 그리고 단순히 다운샘플링 구조의 CNN을 사용하는 것에 그치지 않고, 업샘플링과 스킵 커넥션을 결합하여 더 풍부한 학습을 가능하게 만든 점이 특히 인상적입니다.
이와 같은 다양한 기법들이 하나의 논문 안에서 유기적으로 결합되어 있다는 점이 정말 대단하다고 생각합니다.
