📌 이번엔 Anomaly Detection 분야에서 Mvtecdataset 기준 SOTA, 즉 정확도가 1위인 논문을 리뷰해보려고 합니다.
논문을 읽어본 바, 지금까지 읽었던 논문 중에서 상당히 어려운 논문에 속합니다. 수식도 많고 다양한 아이디어가 적용되기 때문에 처음 읽을 때는 많이 힘들었습니다만, 정리하고 보니 아이디어 자체가 이해하기 어려운 건 아닙니다. 그러니 처음 본 분들도 이해하기 쉽도록 정리해보겠습니다.

🤷 Abstract
기존의 Unsupervised 이상탐지 모델은 불량 데이터가 부족하거나, 작은 결함을 탐지하기 어려운 문제점이 있습니다.
GLASS에서는 새로운 이상 합성 전력을 제시합니다.
-
Global & Local Anomaly Synthesis
-
Gaussian Noise
-
Gradient Ascent
-
Truncated Projection
위 4가지 기법을 통해 정상 이미지에 불량 패턴을 합성하여 학습을 시킵니다. 이를 통해 데이터셋이 증가하게 되고, 미세한 불량도 탐지할 수 있도록 합니다.
🙎♂️ 기존 모델과의 차이점
대부분의 이상탐지 모델은 정상 데이터셋을 활용하여 이상 영역을 식별하고 위치를 파악하는 것을 목표로 합니다. 그 이유는 이상탐지 모델의 경우 대부분 산업현장에서 쓰이며, 정상 데이터에 비해 불량 데이터를 모으기가 매우 힘들기 때문입니다. 또한 픽셀 수준의 라벨링은 매우 높은 비용(시간)이 소비되기 때문에 현실적으로 비지도 이상탐지 기법이 산업용 검사 분야에서 널리 활용되고 있습니다.
하지만 이런 방식 때문에 모델이 불량에 대한 정보를 직접적으로 학습하기 힘들고 정상과 비슷한 미세한 불량은 탐지 성능이 떨어진다는 한계점을 가지고 있습니다.
기존의 이상탐지 기법은 세 가지 범주로 나눌 수 있습니다.
-
재구성 기반(Reconstruction) - Encoder와 Decoder 기반의 모델로 정상 이미지로 학습하기 때문에 오로지 정상이미지만 잘 복원할 수 있다는 특징을 이용합니다.
-
임베딩 기반(Embedding) - 사전 학습된 모델을 활용하여 특징을 추출 및 압축한 , 정상 클러스터와 이상치 특징을 분리하는 방식 입니다. 즉, 정상데이터는 비슷한 곳에 모이게 되고, 이상치의 경우 정상데이터와 멀리 떨어져 있을 거라는 생각을 바탕으로 합니다.
-
합성 기반(Synthesis) - 정상 샘플에 이상치를 합성하여 탐지 모델이 이상을 구별하도록 학습하는 방식입니다.
GLASS는 3번째 방식인 합성 기반을 바탕으로 합니다. GLASS 이전 논문들의 합성 전력은 다음과 같습니다.
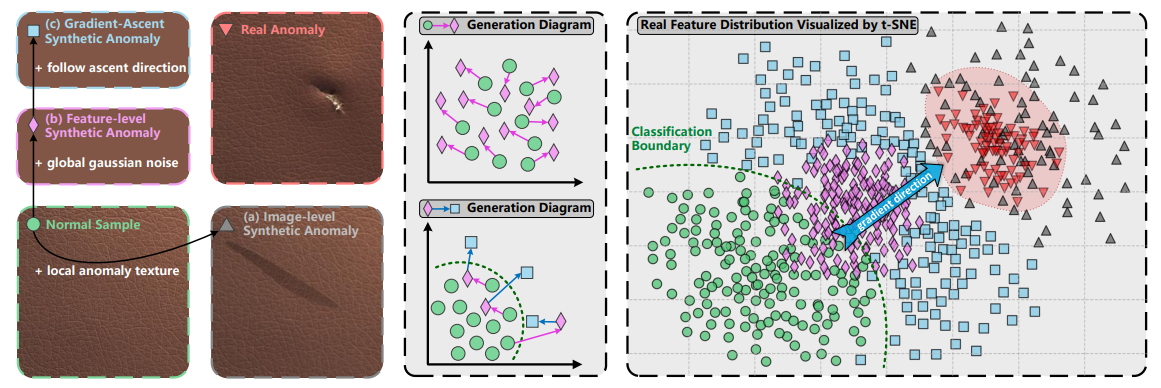
-
(a) Image-Level : 정상 이미지에 불량 패턴을 직접 합성합니다. 명시적으로 합성 가능하지만, 다양성과 현실감이 부족합니다.
-
(b) Feature-Level : 특징 공간에서 이상을 합성하는 방식입니다. 즉, 이미지에 합성하는 것이 아닌 feature map이 추출되면 그곳에 이상치를 합성하는 방식입니다. feature map은 이미지보다 사이즈가 작아 효율적이지만, 그만큼 방향성 있는 이상을 합성하기 어렵고 제어가 힘들다는 단점이 있습니다.
GLASS는 위 두 방식을 모두 사용하지만, 각각 다른 전략을 추가적으로 사용합니다.
🔶 GAS(Global Anomaly Synthesis)
이는 위 (b) 방식의 feature map 수준의 합성 전략입니다. 제어 가능한 방식을 위해 Gaussian Noise와 Gradient Ascent를 적용합니다.
Gaussian Noise
실제 산업환경에서는 이상 분포를 알 수 없기 때문에, 가우시안 노이즈를 사용하여 다양한 이상 패턴을 시뮬레이션 합니다.
는 정규분포를 따르는 가우시안 노이즈 입니다. 이를 Feature map 에 더하여 이상 특징을 만들어 냅니다. 하지만, 이런 이상 분포는 방향성이 없이 랜덤한 값이기 때문에 학습에 효과적이지 않습니다. 따라서 경사 상승(Gradient Ascent) 기법을 사용합니다.
딥러닝을 공부하시는 분들이라면 경사하강법을 많이 들어보셨을 겁니다. 학습의 loss를 줄이는 방향, 즉 기울기가 0인 방향으로 이동하는 것을 말합니다.
Gradient Ascent
Gradient Ascent는 이와 정반대되는 개념입니다. 정상에서 멀어지도록, loss가 커지도록 이동하는 방식입니다. 논문의 저자는 이를 통해 이상치를 합성할 때 방향성을 제시할 수 있다고 합니다.
앞서 합성된 에 기울기 방향으로 학습률 만큼 이동하게 됩니다.
를 로 나눔으로써 벡터의 방향을 결정해주고, 의 비율로 이동합니다.
다만 위 방법에는 문제점이 있습니다. Gradient Ascent를 통해 이동을 할 경우, 정상과는 적당한 거리로 떨어져 있어야 하며, 이상과 너무 멀리 떨어져서도 안됩니다.
이에 대해 논문 저자는 다음과 같은 개념을 제시합니다.
Manifold Hypothesis & Hypersphere Hypothesis
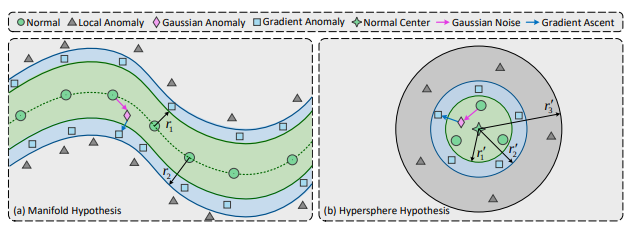
굳이 번역을 하자면 다양체 가설과 초구 가설이라 할 수 있습니다.
정상치들이 저차원에서 왼쪽 그림과 같이 선형 조합을 통한 전체적인 비선형 분포를 나타내는 유클리드 공간으로 표현할 수 있다.
또한 오른쪽 그림과 같이 정상적인 특징 점들의 조합은 하나의 압축된 원 내부에 포함된다고 가정한다.
다양체 가설
모든 판별하려는 점 는 모든 정상점 과 최소 만큼 떨어져 있어야 이상치로 간주 한다.
즉, 왼쪽 그림에서 그림에서 특정 사각형(Gradient Anomaly)가 모든 원(Normal)과 이상 떨어져 있어야 합니다.
초구 가설
모든 판별하려는 점 는 중심점과 이상 떨어져 있어야 이상치라 판단한다.
위 두 가설을 바탕으로 논문의 저자는 Gradient Ascent로 이상치를 추가할 때, 정상치와 떨어진 거리에 제한을 두었습니다. 이를 Truncated Projection라 합니다.
Truncated Projection
Gaussian Noise와 Gradient Ascent를 적용한 와 정상치인 뺀 값이
과 사이 값이 되도록 합니다.
그러기 위해 값을 다음과 같이 제한합니다.
간단히 말하자면, 보다 작을 때 는 이 되도록, 보다 클 때는 가 되도록 제한하자는 의미입니다.
초구 가설에서도 이는 동일합니다.
초구의 중심과의 거리가 과 사이 값이 되도록 합니다.
저희가 지금까지 정리한 Truncated Projection은 GAS(Global Anomaly Synthesis)에만 해당하는 것 입니다.
가우시안 노이즈와 경사 상승을 적용한 것이 GAS.
이미지 자체에 불량 패턴을 직접 합성한 것이 LAS.
때문에 GAS는 미세한 불량이 되고, LOS는 좀더 직접적인 불량으로 실제 불량과 매우 비슷하게 위치할 것 입니다.
따라서 LAS는 정상치에서 더 멀리 떨어져 있다고 할 수 있습니다.
그래서 논문 저자는 LAS의 경우,
과 사이의 위치하도록 합니다. 즉 LOS는 GAS보다 이상치가 더 멀도록 제한하였습니다.
이 때, 입니다.
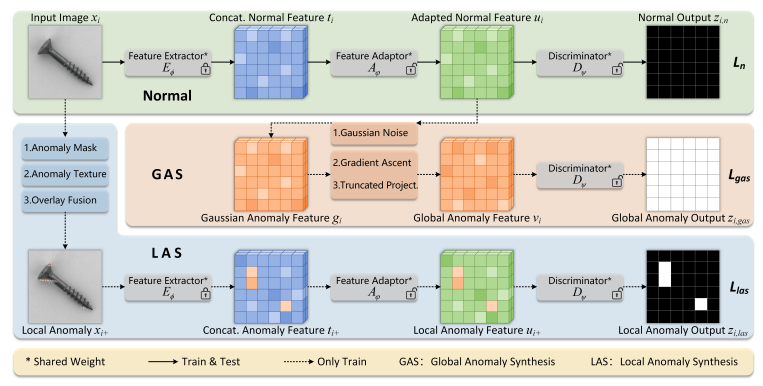
앞서 설명한 과정들을 그림을 통해 정리 한 뒤에 진행해봅시다.
우선 초록색 배경부터 살펴봅시다. 정상이미지가 입력으로 들어오고 사전훈련된 특징 추출기 를 통해 특징맵을 추출합니다.
이때 특징 추출기는 얼려져(Frozen) 있는 상태로 학습이 안됩니다. 따라서 훈련가능한 Adaptor에 특징맵을 넣어줍니다.
어댑터를 통해 추출된 특징맵을 바탕으로 GAS를 진행합니다. 가우시안 노이즈와 경사상승을 앞서 설명한 Truncated Projection 조건에 맞도록 적용하여 Global Anomaly Feature Map이 만듭니다.

알고리즘은 위와 같다고 하네요.
🔶 LAS(Local Anomaly Synthesis)
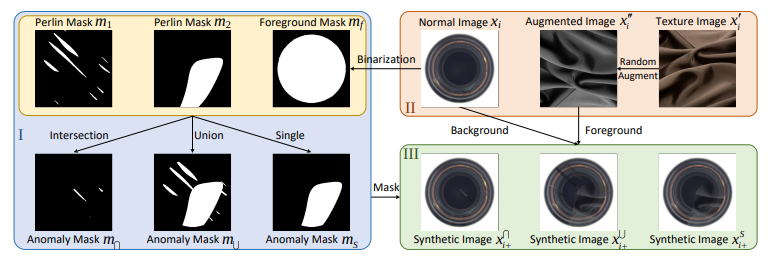
LAS는 내용은 간단하지만 순서가 살짝 복잡하기 때문에 단계별로 적어 보겠습니다.
-
Normal Image에서 Foreground Mask를 만든다.(정상이미지를 Binarization 하여 샘플의 전체 위치를 찾아냅니다)
-
Perlin Mask를 통해 불량 패턴을 적용할 위치를 Mask로 만들어냅니다.(과 를 만듭니다.)
-
최종적으로 만들어지는 3가지 Mask(Forground, , ) 는 3가지 패턴으로 서로 합쳐집니다.
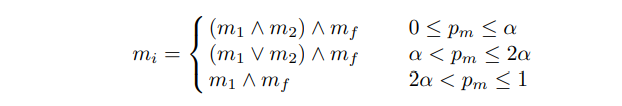
- 안에서 , 이 겹치는 부분
- 안에서 , 이 포함되는 부분
- 와 이 겹치는 부분
각각 1/3씩 비율을 차지하도록 만듭니다.
위 내용을 통해 텍스쳐를 정상이미지와 합칠 때, 단순히 이상패턴을 더해주는 것이 아닌 특정 비율을 통해 더해줍니다.
위 식은 3가지 항으로 나뉩니다.
정상영역 유지 항
- 정상이미지와 이상마스크의 반전(정상영역)이 겹치는 부분으로 정상영역을 유지하는 역할입니다. 정상이미지에 이상패턴이 더해져야 하기 때문에, 정상영역이 기본적으로 존재해야 합니다.
이상 텍스처 적용 항
- 이상영역과 이상마스크가 겹치는 부분으로 가중치 만큰 투명도 계수를 곱하여 이상 텍스쳐를 추가합니다.
원본 이미지 혼합 항
- 정상영역과 이상마스크가 겹치는 부분으로 이상 영역 부분에서도 원본 이미지를 일부 유지합니다. 이상 텍스처만 더하는게 아니라 이상 부분에 정상 텍스처도 유지하여 너무 인위적인 합성이 되지 않도록 도와줍니다.
Loss Function
손실함수는 위와 같습니다. Normal, GAS, LAS에 손실을 모두 BCE Loss를 사용합니다.
Normal 이미지의 경우 불량이 없기 때문에 모든 픽셀에 대해 0이 정답 마스크가 됩니다.
GAS는 전체 범위에 가우시안 노이즈와 경사상승을 적용해씩 때문에 모든 픽셀이 불량입니다. 따라서 1이 정답 마스크가 됩니다.
LAS는 이상 마스크를 적용한 부위만 불량 픽셀이므로 정답 마스크로 이상마스크를 넣습니다.
이 때 는 Adaptor에서 추출된 특징맵을 Discriminator에 입력으로 넣었을 때 나오는 Segmentation Result 입니다.
정리하면 다음과 같습니다.
Feature Extractor에 입력 이미지를 넣고, Feature map을 얻습니다. 이 때, Extractor는 단순히 추출하는 기능만 있고 학습을 하지 않기 때문에 Adaptor에 Feature map을 넣어줍니다.
Adaptor의 출력을 Discriminator에 넣어 Segmentation Result를 얻습니다.
Anomaly Map을 얻을 때, Discriminator를 통해 추출된 Anomaly map이 원본 이미지와 사이즈 차이가 있기 때문에 보간해준 뒤 Gaussian Smoothing을 적용하여 노이즈를 완화해줍니다.
그리고 Anomaly map에서 가장 큰 값이 Anomaly Score가 됩니다.
또한 인퍼런스 과정에서는 LAS와 GAS를 사용하지 않고 오로지 Normal 파트만 사용하여 불량을 탐지합니다. 따라서 인퍼런스 과정에서 시간이 시간이 오래 걸리진 않을 것으로 생각됩니다.
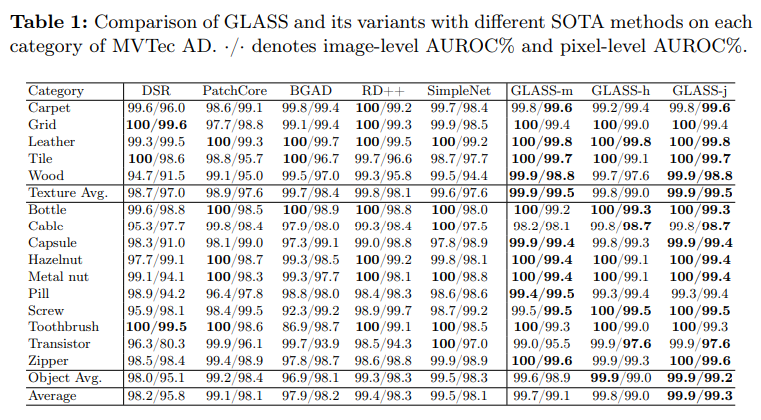
Experiments
📌 fin
이 논문은 다른 논문들에서 제시한 기법을 많이 채용하여 모델의 정확도를 높이려 한 것 같습니다. 대부분의 기법들이 이미 기존의 사용되던 기법들이고, 이를 잘 활용하여 SOTA 모델이 되었습니다. 하지만 한편으로는 모델의 구조가 매우 복잡하다는 단점이 있습니다. 학습 하기 위해 총 3개의 구조를 사용하다 보니 훈련시간도 매우 오래 걸릴 것 같네요.
다만 인퍼런스 과정에서는 GAS와 LAS를 적용하지 않고 Normal 파트만 사용하기 때문에 인퍼런스 과정은 오래걸리지 않을 것 같습니다.
