[논문리뷰] R-CNN (Rich fearture hierarchies for accurate object detection and semantic segmentation)
논문리뷰
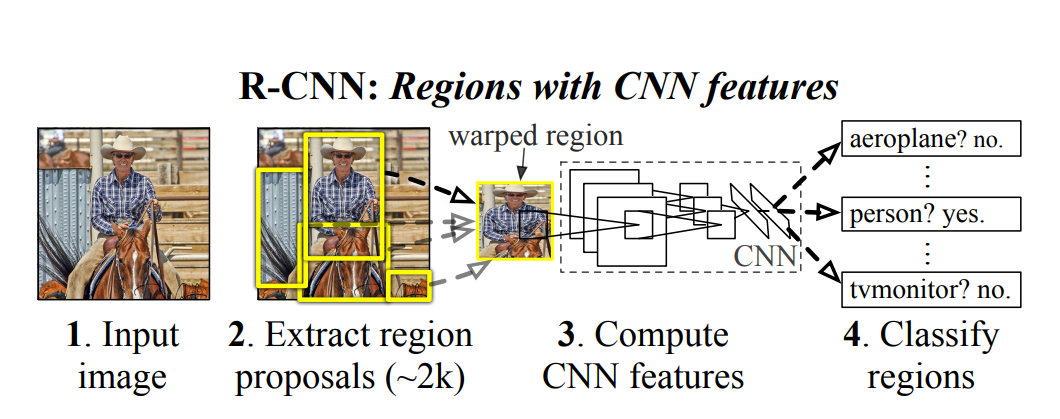
📌 드디어 classification이 아닌 object detection 논문을 읽어볼 차례입니다. classification의 경우 이미지당 하나의 클래스를 분류하는 문제였다면, object detection의 경우 이미지 한 장에서 여러개의 클래스를 찾아내고, 해당 클래스마다 바운딩 박스로 위치를 나타내주는 역할을 합니다.
💡Abstract
이 논문에서는 VOC2012에서 최고 성적보다 30%이상이 향상된 mAP 53.3%를 달성하는 간단하고 확작 가능한 알고리즘을 제안합니다. 우리의 접근 방식은 두 가지 방법을 결합하여 사용됩니다.
1. 큰 사이즈의 합성곱 신경망을 bottom-up region proposal로 객체의 위치를 지정하고 분할.
2. 레이블이 붙은 훈련 데이터가 부족할 때 보조 작업에 대한 지도 pre-training 후, fine-tuning 과정을 거침.
우리는 region proposal과 CNN을 결합하기 떄문에 R-CNN이라 명명합니다. 또한 최근 슬라이딩 윈도우 탐지기인 OverFeat과 성능을 비교합니다.
"Bottom-up region proposal"은 객체 탐지에서 사용되는 기법 중 하나로, 이미지에서 객체가 있을 가능성이 있는 영역을 제안하는 방법입니다. 아래 사진에서 노란색 박스가 그에 해당하죠.
이미지의 저수준 특징을 추출하여 잠재적인 객체 영역을 식별합니다. 추출한 이미지에서 잠재적인 객체 후보 지역(즉, 물체가 있을 수 있는 영역)을 생성합니다. 이러한 후보 지역은 일반적으로 객체가 있을 가능성이 높은 위치를 제안합니다. 이를 위해 다양한 기법이 존재하는데, 본문에서 더 자세히 다뤄봅시다.
💡1. Introduction
지난 10년간 다양한 시각 인식 작업의 진전은 SIFT와 HOG에 기반해왔다. 그러나 PASCAL VOC의 객체 탐지 성능을 보면, 2010-2012년 동안의 진전은 느렸다고 일반적으로 인정되며, 앙상블 시스템을 구축하거나 성공적인 방법의 작은 변형을 사용하는 것으로 얻어진 작은 개선이었다.
SIFT와 HOG는 블록 단위 방향 히스토그램으로, 인식이 여러 단계의 하류에서 이루어지며, 이는 시각 인식에 더 정보가 많은 특징을 계산하기 위한 계층적이고 다단계의 과정이 있을 수 있음을 시사합니다.
CNN은 1990년대에 활발히 사용되었으나, 이후 서포트 벡터 머신(SVM)의 부상으로 인기가 줄어들었습니다. 2012년에 ILSVRC에서 이미지 분류 정확도가 크게 향상되었음을 보여주어 CNN에 대한 관심을 다시 불러일으켰습니다. 그들의 성공은 120만 개의 레이블이 붙은 이미지에서 대형 CNN을 훈련시킨 것과 LeCun의 CNN에 몇 가지 변화를 추가한 결과였습니다.
ImageNet 결과의 중요성은 ILSVRC 2012 워크숍에서 활발히 논의되었습니다. 논의의 핵심 문제는 다음과 같습니다.
CNN 분류 결과가 PASCAL VOC 챌린지에서 객체 탐지 결과로 얼마나 일반화되는가?
우리는 이 질문에 답하기 위해 이미지 분류와 객체 탐지 사이의 간극을 메우고자 합니다. 이 논문은 CNN이 HOG를 기반으로 한 시스템에 비해 PASCAL VOC에서 객체 탐지 성능을 극적으로 향상시킬 수 있음을 처음으로 보여줍니다.
이 결과를 달성하기 위해, 우리는 두 가지 문제에 집중했습니다.
1. 깊은 네트워크를 통한 객체 위치 지정
2. 적은 양의 annotation이 붙은 데이터로 높은 용량의 모델 훈련입니다.
이미지 분류와 달리, 탐지에서는 이미지 내의 객체의 위치를 지정해야 합니다. 이 위치 지정을 회귀 문제로 풀 수 있지만 좋은 성능은 나오지 않았습니다. 대안으로는 슬라이딩-윈도우 방법이 있습니다. CNN은 일반적으로 얼굴 및 보행자와 같은 제한된 객체 카테고리에 대해 20년 이상 이러한 방식으로 사용되어 왔습니다.
이러한 CNN은 높은 공간 해상도를 유지하기 위해 일반적으로 두 개의 합성곱 및 풀링 레이어만을 포함합니다. 우리는 또한 슬라이딩-윈도우 접근 방식을 채택하는 것을 고려했습니다. 그러나 우리의 네트워크는 다섯 개의 합성곱 레이어를 가지고 있으며, 이 네트워크의 상위 유닛은 매우 큰 수용 필드(195 × 195 픽셀)와 입력 이미지에서의 보폭(32×32 픽셀)을 가지기 때문에, 슬라이딩-윈도우 패러다임 내에서 정확한 위치 지정을 수행하는 것은 기술적인 도전 과제가 됩니다.
논문 작성자는 다양한 방안을 찾아보았지만 모두 문제점이 있었습니다.
- 회귀 문제 - Szegedy 가 이 방법은 잘 통하지 않는다는 연구를 발표함
- 슬라이딩 윈도우 - 입력으로 들어가는 이미지에서 추출하는 영역의 사이즈가 매우 크기 떄문에 계산량이 많아짐
이미지에서 찾아내려는 물체의 크기가 이미지의 절반이나 차지한다고 해봅시다. 그 물체를 모두 담아내기 위한 receptive field를 만들어 슬라이딩 윈도우 기법으로 이미지의 특징을 추출한다면 계산이 매우 비효율적일 것 입니다.
따라서 논문 저자는 region proposal 기법을 제안합니다.
pre-training & fine-tunning
ILSVRC의 많은 데이터로 pre-training 후, PASCAL 데이터로 fine-tunning을 합니다. 실험 결과, mAP가 8% 상승하였습니다.
classification의 경우 이미지의 클래스만 라벨링이 필요했지만, object detection에서는 객체의 위치값도 라벨링이 되어 있어야 합니다. 따라서 훈련데이터가 부족한 경우가 생기는데, 이에 대해 논문 저자는 다음과 같은 방법을 제시합니다.
💡2. Object detection with R-CNN
region proposal
-
수많은 후보영역을 생성합니다.
-
이후 형태나 질감이 비슷한 것 끼리 묶어 새로운 후보영역으로 합칩니다(selective search).
-
위 과정을 반복하여 최종적으로 총 2천장의 region proposal을 생성한다.
-
2000장의 region proposals을 227x227로 사이즈를 만든다.
-
CNN을 거친 후 서포트 벡터 머신(SVM)을 이용해 클래스를 분류한다.
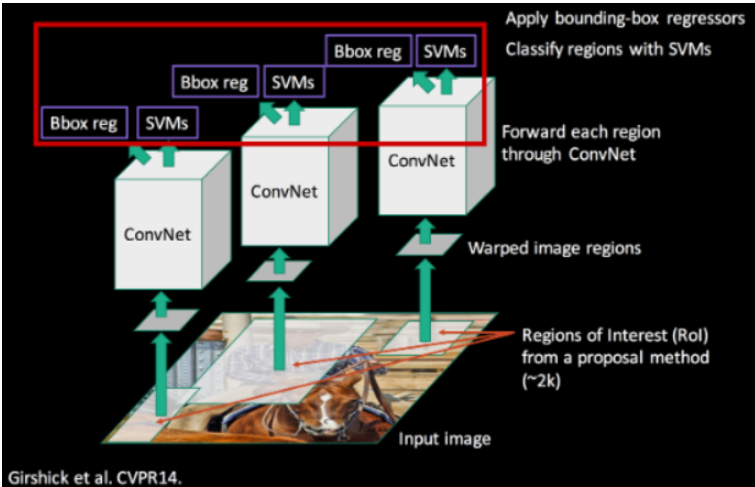
resion proposal 시 객체의 개별 부위를 따로 인식하지 않도록, 우리는 Selective Search 알고리즘을 사용합니다. 예를 들어, 사람의 눈이나 입과 같은 개별 부위를 따로 제안하기보다는, 사람의 전체 몸을 하나의 제안으로 생성할 수 있도록 합니다.

2.3 Domain-specific fine-tuning.
CNN 파라미터의 확률적 경량 하강법(SGD) 훈련을 합니다. CNN의 클래스를 (N + 1)-way 분류 레이어로 교체하는 것을 제외하고는, CNN 아키텍처는 변경되지 않습니다. 여기서 N은 객체 클래스의 수이며, 배경을 포함하여 1을 더합니다.
우리는 모든 region proposal 이 실제 박스와의 IoU가 0.5 이상일 경우 그 박스의 클래스에 대해 Positive로 처리하고, 나머지는 Negative로 처리합니다. SGD는 초기 사전 훈련 학습률의 1/10인 0.001로 시작하여, 초기화가 손상되지 않으면서도 미세 조정이 진행될 수 있도록 합니다. 각 SGD 반복에서, 우리는 32개의 Positive와 96개의 배경(Negative)을 균형 있게 샘플링하여 크기 128의 미니 배치를 구성합니다. Postive는 배경보다 훨씬 적기 때문에 샘플링을 Positive에 기울입니다.
IoU 0.5를 기준으로 Postivie와 Negative로 나눕니다.
대부분의 이미지에서 배경이 객체보다 더 많은 부분을 차지 하기 때문에 region proposal로 나온 이미지에서 Positive가 매우 적은 문제가 발생합니다. 따라서 일부러 데이터를 Positive가 많이 나오도록 샘플링을 해줍니다.
selective search 알고리즘을 통해 얻은 객체의 위치는 부정확할 수 있다. 이런 문제를 해결하기 위해 객체의 위치를 조절해주는 Bounding box regressor가 있다.
2.3 Object category classifiers
객체의 클래스를 분류할 때, 실제 바운딩 박스와 모델이 예측한 바운딩 박스의 IoU 갑싱 0.3 이상이면 Positive로 간주한다. 여러 값을 실험에 본 결과 0.3일 때가 가장 좋은 성능을 나타냈다.
파인튜닝을 할 때는 IoU 임계값을 0.5로 하고, 훈련 과정에서는 0.3으로 다르게 설정했을 때 더 좋은 성능이 나왔다고 합니다.
💡3. Bounding Box Regressor
나머지 내용은 결과에 대한 내용이므로, 이 논문에서 나름 중요하다 생각되는 부분을 리뷰하겠습니다.
classification의 경우 훈련과정에서 이미지의 클래스를 정답 라벨과 비교하여 loss를 구해 학습을 하게 됩니다.
반면, object detection의 경우 객체의 위치를 나타내주는 bounding box의 위치를 찾아내는 과정도 학습을 해야 합니다. 즉, 바운딩 박스의 x,y 좌표의 loss를 구하는 과정이 필요합니다.
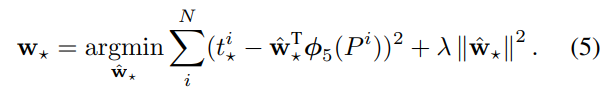
smooth L1 Loss를 사용합니다.
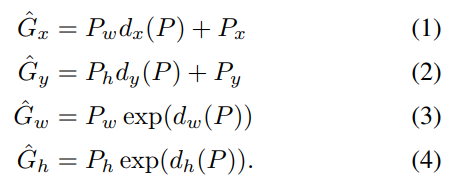
P는 모델이 예측한 값이며 G는 실제 값(ground truth)입니다. d를 t로 변환한 뒤 t에 대한 식으로 정리하면 아래와 같은 결과가 나옵니다. 바운딩 박스의 예측값과 실제값의 차이가 적어지도록 하는 식입니다.
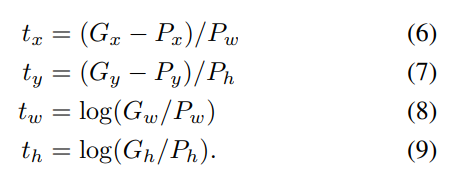
위 식을 자세히 보시면 x,y의 경우 그냥 차이를 구하지만, w와 h는 log 스케일로 변경해준 걸 볼 수 있습니다.
제 생각에 x와 y의 좌표의 경우 차이가 상대적으로 일정하게 유지되기 때문에 그냥 차이만을 구하는 걸로 보입니다.
반면, 너비 w와 높이 h의 차이가 커질 경우 손실이 제곱에 비례해 증가하기 때문에 로그 스케일 변환을 통해 학습 과정에서 손실이 너무 커지는 것을 완화해주는 것 같습니다.
예를 들어, w와 h가 2배 증가한다면 넓이는 4배가 차이가 날 것입니다.
💡4. Non maximum Suppression
resion proposal에서 생성된 바운딩 박스는 총 2천개 입니다. 이 모두를 실제 정답으로 제시하지는 않습니다. 같은 물체를 탐지한 바운딩 박스의 경우 가장 정확도가 높은 것을 남기고 모두 삭제해주는 과정이 Non maximum suppression 입니다.
- confidence score threhold 값 보다 낮은 박스들을 삭제 합니다.
- 남은 박스를 confidence score에 따라 내림차순으로 정렬 한 뒤, 가장 높은 confidence score box와 나머지 box들 간의 IoU 값이 threhold 값 이상인 box를 삭제 합니다.
ex) confidence score threhold가 0.3 & IoU threhold가 0.9
1. confidence score threhold가 0.3 이하인 바운딩 박스는 모두 제거합니다.
-> 객체가 있을 확률이 너무 작은 박스들은 삭제합니다.
2. 가장 높은 정확도를 가진 바운딩 박스와 겹치는 영역(IoU)가 0.9 이상인 바운딩 박스를 삭제합니다.
-> 0.9이상으로 겹칠 경우 서로 다른 바운딩 박스가 동일한 객체를 감지한 경우일 가능성이 매우 크기 때문에, 한 객체당 하나의 바운딩 박스만 선택되도록 삭제하는 과정입니다.
📌 finish
object detection의 경우 다양한 알고리즘을 접목시키기 때문에, 한 논문을 읽으면 공부해야할 내용이 정말 많습니다. R-CNN만 해도 selective search, non maximum suppression, IoU, SVM 등 처음 듣는게 많을 수 있습니다.
다른 논문에서 이미 나온 내용이기 때문에, 자세한 설명을 다루지 않는 경우도 많습니다. 따라서 모르는 내용이 나오면 따로 찾아봐야 하는 경우가 자주 생깁니다.
저 같은 경우 알고리즘 하나하나에 대한 논문을 찾아보기 보다는 블로그에 알고리즘을 정리해주신 분들의 글을 읽으며 따로 공부를 하고 있습니다.
거기서 배운 알고리즘을 유명한 모델들을 공부해가며 어떻게 사용되는지 확인해보시면 좋을 듯 합니다.
