
궁금점
데이터베이스의 성능을 높인다는 것은 무엇을 의미하는 것일까?
어떻게 성능을 높인다는 걸까?
인덱스는 어떻게 사용하는 걸까?
데이터베이스 성능 핵심
데이터베이스는 디스크에서 값을 읽어 와요. 즉, RAM에 비해 속도가 현저히 느리다는 것이죠. 이 부분을 정리해보니 다음과 같은 결론이 나요.
데이터베이스의 성능을 높이려면 디스크 I/O 접근을 최소화해야 한다.
그렇다면 어떻게 줄일까?
우선 데이터베이스를 활용한다는 것은 크게 두 가지로 나뉘어요.
!!조회와 쓰기!!
조회는 당연히 디스크에서 값을 읽어오기 때문에 디스크에 가기 전 메모리에 올라온 데이터를 활용해요.
쓰기도 디스크에 접근하기 전에 메모리를 거치게 되요.
그렇다면 메모리에 올라온 데이터를 최대한 활용하면 되요.
즉, 캐시히트율을 올리는 거에요.
두 가지를 생각해보아요.
캐시히트율을 어떻게 높일까?
-- 캐시에 대한 공부 필요 --
WAL
메모리는 휘발성이에요. 즉, 전원 공급이 의도치 않게 꺼진다면 데이터가 날라가요. 무조건 해결책이 있어야 되는 것이에요. 그래서 사용하는게 Write Ahead Log(이하 WAL)이에요.
WAL은 파일에 순차적으로 내가 실행한 쿼리에 로그가 남기 때문에 설령 메모리에 쌓여있는 데이터가 디스크에 가지 않고 유실 되더라도 서버가 다시 뜰 때, 파일(히스토리)에 순차적으로 쌓아 놨던 로그를 재실행 시켜요.
WAL은 랜덤 I/O가 아니라 순차적 I/O를 사용해요. 이를 통해 정합성을 유지하며 일관성을 보장할 수 있어요.
랜덤 I/O vs 순차 I/O
랜덤 I/O와 순차 I/O의 작업은 사실상 동일해요. 디스크 드라이브의 플래터(원판)를 돌려 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽어들이는 과정이에요.
핵심은 디스크 헤더를 움직여 읽고 쓸 위치로 옮기는 단계에요.
디스크의 성능은 디스크 헤더의 움직임 없이 얼마나 많은 데이터를 한번에 기록하느냐에 결정되기 떄문이에요.
랜덤 I/O는 순차 I/O에 비해 상대적으로 여러번 읽고 쓰기를 요청해요. 이 떄문에 작업 부하는 커지게 되요.
인덱스
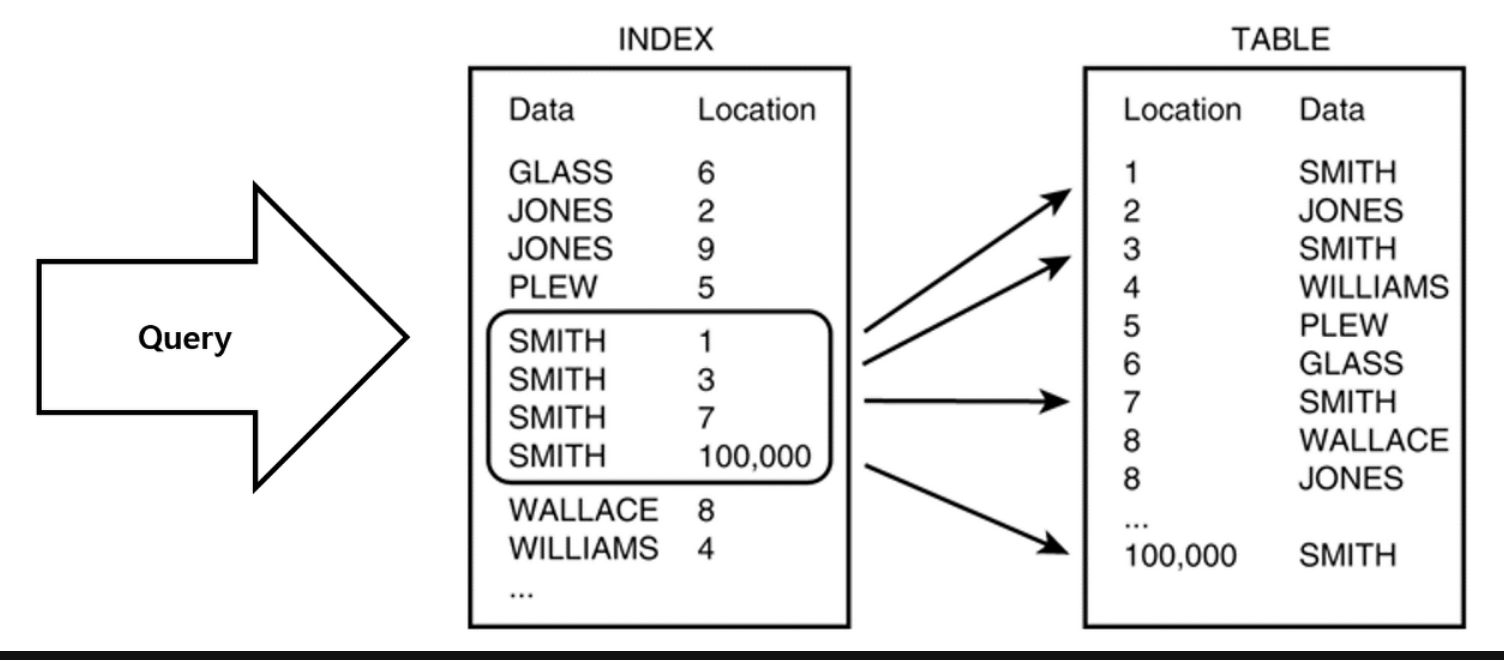
인덱스는 정렬된 자료구조로, 이를 통해 탐색범위를 최소화하는 것이 목표에요. (인덱스도 테이블이다)
인덱스의 자료구조는 B+Tree를 사용해요. (tree의 높이를 줄이는 것이 탐색속도를 줄이는 것이 효율성을 높이는 것)
- 삽입/삭제 시 균형을 이룸
- 하나의 노드가 여러 자식을 가지고 있음
- 리프노드에만 데이터 존재 → 연속적인 데이터 접근 유리
인덱스를 사용한다는 것은 조회의 성능을 높일 수는 있지만, 쓰기나 갱신의 성능을 낮출 수 밖에 없다. 즉, trade-off 관계인 것이지요.
클러스터 인덱스
- 클러스터 인덱스는 데이터의 위치를 결정하는 key값 이에요.
- 클러스터 키는 인덱스와 같은 정렬된 자료구조이며, 클러스터 키의 위치에 따라 데이터의 주소가 결정되요.
- 즉, 클러스터 키 순서에 따라 데이터 저장위치가 변경되는 것 → 클러스터 키도 삽입/갱신이 성능이슈 발생해요.
- MYSQL의 PK는 클러스터 인덱스에요.
- MYSQL에서 PK를 제외한 모든 인덱스는 PK를 갖고 있다.
- PK의 사이즈가 인덱스의 사이즈를 결정해요.
- 인덱스가 PK가 아닌 데이터의 직접적인 주소를 갖게 되면 데이터의 순서가 바뀔 때마다 인덱스도 같이 갱신되어야 하니 부하가 훨씬 많이 들 것 → 그래서 인덱스는 PK를 들고 있음으로써 PK의 데이터가 변경될 때, 인덱스는 아무 상관(변화)이 없게 되요.
- 세컨더리 인덱스만으로는 데이터를 찾을 수 없어요. why? 세컨더리 인덱스를 통해 PK를 찾고 PK를 통해 데이터를 찾는 거에요.
장점
- PK를 활용한 검색이 빨라요. (특히 범위 검색)
- 세컨더리 인덱스들이 PK를 가지고 있어 커버링에 유리
