궁금점
서버에서 query를 날리면, mysql이 어떻게 받아서 처리해서 응답을 해주는게 궁금해져서 글을 써보려 해요.
mysql과 WAS 사이의 작동 방식
자바에서 mysql을 연결하려고 하면 라이브러리를 통해 우리는 "connectior-j"를 사용해여 연결해요. 이것을 우리는 연결하는 Driver라고 하며, mysql은 이를 통해 외부의 요청(WAS)을 처리할 수 있게 된 것이죠.
작동 순서는 다음과 같아요.
WAS -> Utility Layer(MYSQL connector) -> MYSQL 엔진 -> 스토리지 엔진 -> 운영체제 -> 디스크
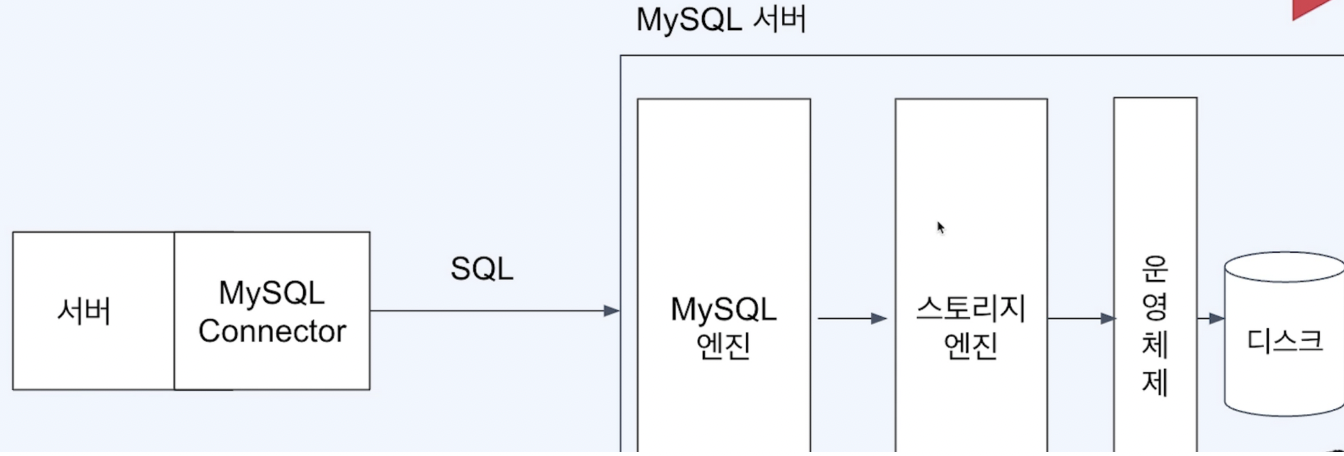
왜 디스크에서 가져올까?
운영체제를 공부하다보니 이부분에 대한 생각을 먼저 해보았어요.
가장 큰 이유는 메모리는 휘발성이에요. 전원이 켜져 있지 않는다면 데이터가 사라진다는 것이죠.
또한, 데이터베이스(특히 RDBS)는 보통 엄청나게 많은 데이터의 상태를 보관하는 곳이에요. 구조를 생각해보면 메모리에서 읽어오면 빠르게 가져올 수는 있지만, 데이터베이스에 있는 대량의 데이터를 담으려면 상상을 초월하는 비용이 들 거에요. 그러니 디스크에 저장한 데이터를 메모리에 가져와 활용하는 것이죠.
그렇기에 OS와 디스크가 가장 끝 단에 있을 거에요.
MYSQL 엔진
MYSQL 엔진은 MYSQL의 두뇌라고 불려요. 판단과 명령을 하는 곳이에요.
여기에는 4가지 단계가 있어요.
쿼리파서 -> 전처리기 -> 옵티마이저 -> 쿼리실행기
쿼리파서
쿼리 파서는 sql을 파싱하여 Syntax Tree를 만들어요. 이 때 문법 오류를 검사하는 거에요.
"SQL Error:번호"를 만나는 것은 여기서 걸러지는 것이에요.
전처리기
전처리기는 쿼리 파서에서 만든 Tree를 바탕으로 데이터 전처리를 시작해요. 이 때 테이블이나 칼럼 존재 여부, 접근 권한 등 Semantic 오류를 검사해요.
Syntax 오류와 Semantic 오류
- Syntax오류 : 문법적인 오류를 의미해요. 개발 툴에서 주로 빨간 밑줄이 뜨면서, 자동적으로 잡아주는 종류의 에러이죠. 이런 오류가 존재하면 프로그램이 정상적으로 컴파일되지 않는 경우가 대다수에요.
- Semantic오류 : 논리적인 오류를 의미해요. 논리적인 오류는 프로그램이 부정확하게 동작하게 하지만 비정상적으로 종료 또는 충돌시키지는 않는 버그에요. 논리 오류는 비록 즉시 인식되지는 않지만 의도치 않은 또는 바라지 않은 결과나 다른 행동을 유발하지요.
옵티마이저
옵티마이저는 쿼리를 처리하기 위한 여러 방법들을 만들고, 각 방법들의 비용정보와 테이블의 통계정보를 이용해 비용을 산정해요.
- 테이블 순서, 불필요한 조건 제거, 통계 정보를 바탕으로 실행 계획에 대한 전략을 결정해요.
- 옵티마이저가 어떤 전략을 선택하느냐에 따라 성능이 많이 달라져요.
- 옵티마이저가 내린 결정은 항상 최적이 아니에요. 그래서 개발자가 힌트를 주어 도울 수 있어요.
쿼리 실행기
쿼리 실행기는 옵티마이저가 결정한 전략을 계획대로 스토리지 엔진에 요청하는 역할이에요. (보통 Handler API 요청)
스토리지 엔진
스토리지 엔진은 MYSQL의 팔과 다리로 불려요. 판단을 수행, 동작하기 때문이에요.
스토리지 엔진은 다음과 같은 역할과 특징이 있어요.
- 디스크에서 데이터를 가져오거나 저장
- MYSQL 스토리지 엔진은 플러그인 형태로 핸들러 API만 끼워 맞춘다면 사용자가 구현해서 사용 가능
- InnoDB, MYIsam 등 여러개 스토리지 엔진 존재
- 8.0대 부터는 InnoDB 엔진이 디폴트 (InnoDB의 핵심 키워드인 Clustered Index, Redo - Undo, Buffer pool은 차후에 시간을 투자해서 다룰거에요.)
실행 과정 정리
다음 순서는 mysql 8.0 기준이에요.
- MYSQL Connector(driver)에 요청이 들어와요.
- 사용자 스레드가 할당되고 요청이 MYSQL 엔진에 전달되요.
- 파서가 SQL을 MySQL이 이해 가능한 최소 단위로 잘라내고, 문법 유효성을 검증해요.
- 전처리기가 컬럼명, 테이블명 등이 존재하는지 확인하고, 접근 권한이 있는지 검증해요.
- 옵티마이저가 전달된 쿼리를 어떻게 해야 효율적인지 계산하고 결정해요.
- 실행 엔진은 옵티마이저에서 결정한 전략을 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 수행하여 흐름을 제어해요.
- 결과를 반환해요.
- 백그라운드 스레드에서 커밋되었으나 디스크에 반영되지 않은 내용을 디스크에 접근하여 일괄 처리해요.
mysql을 개괄적으로 다루어 보았는데, 공부해야 할 부분이 아직 더 많이 남아있네요. 다음 편부터 Clustered Index, Redo - Undo, Buffer pool, 쿼리 캐시 등을 차근차근 다뤄볼거에요.
참고자료
[MySQL] 쿼리 실행 구조 및 쿼리 캐시
https://www.youtube.com/watch?v=vQFGBZemJLQ
https://dev.mysql.com/doc/refman/8.0/en/
