[Korea University] Multivariate Data Analysis 4. Dimensionality Reduction
Multivariate Data Analysis 4. Dimensionality Reduction, Pilsung Kang 강의를 참고하였습니다.
https://www.youtube.com/watch?v=2aTdOGJg7ys&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=13
1. Dimensionality Reduction
보통 머신러닝에서 Business Analytics의 과정은 크게 다음과 같이 이루어진다.
1. Pre-Processing: Normalization, Dimension reduction, Image processing, etc
이때 데이터를 수집한 후 데이터 전처리를 진행하는데 이때 outlier는 없는지, missing value는 없는 지 등 확인하여 머신러닝 알고리즘이 잘 학습하도록 한다.
이 중 대표적인 한가지가 Dimension reduction.
2. Learning: supervised, unsupervised, minimization, etc
3. Error analysis: precision/recall, overfitting, test/cross validation data, etc
그렇다면 Dimension reduction는 무엇일까?
x_1부터 x_d까지의 데이터가 있는 X데이터가 있을 때, 차원의 수인 d가 너무 많아서 학습을 잘 못하거나, 가지고 있는 객체의 수보다도 차원이 많다거나 하여 통계적인 가정을 만족하지 못하는 알고리즘이 존재한다.
이에 학습을 방해하지 않는 선에서 x_1부터 x_d'까지 X의 차원을 축소시키는 것이 Dimension reduction.


어떠한 문서에 대해서 데이터를 뽑는 방법으로는 전통적으로 Bag of words라는 방법이 있었다.
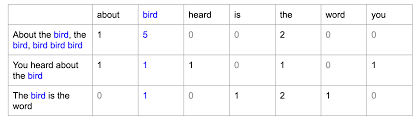
이는 다음과 같이 각 문장에 대해 특정 단어를 몇번 언급하였나를 나타내주는 것. 이때, 단어의 수가 결국에는 언어에 존재하는 총 단어수가 들어가게 되어버린다. 한글에는 약 13만개의 단어가 있는데, 이에 총 13만개의 차원을 만들어야 한다는 것. 이는 효율적이지 못하다. 이에 문서가 가지는 특성을 포함하면서 효율적으로 이를 바꾸어야 했다.
넷플릭스의 경우에는 유저 수를 각 행에 두고, 추천하는 영화의 수를 열로 두개 된다면, 총 480,189 X 17,770의 matrix를 만들어야 한다.
이를 효율적으로 처리하기 위하여 차원축소를 이용한다.
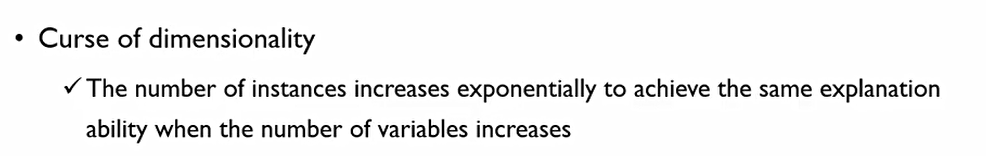
차원의 저주(Curse of dimension)는 우리가 동일한 정도의 설명력을 가지기 위해서는 변수가 선형적으로 증가하면 객체는 기하급수적으로 증가한다.
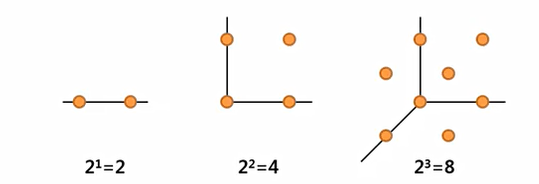
n 차원에서는 동일한 정보를 보존하기 위해서는 2^n개의 관측치가 필요하다.

실제로 우리가 가지는 original dimension보다는 intrinsic dimension은 더 작을 것.
이때, MNIST 데이터를 PCA나 ISOMAP을 통해서 차원을 축소해본 결과물은 다음과 같다.
MNIST 데이터셋의 차원은 16X16=256개의 차원을 가진다. 이를 2차원으로 축소해본 결과는 다음과 같다.
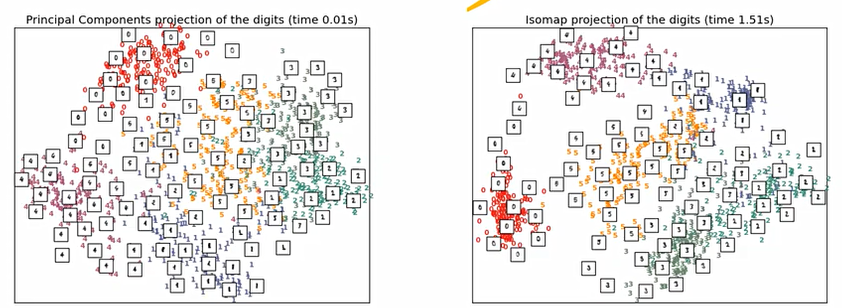
즉, 본질적인 의미를 가지는 Intrinsic dimension은 상대적으로 original dimension보다 작을 수 있다. 항상 그렇다는 것은 아니며, 그럴 확률이 높다는 것.

y = f(x) + ε에서 noise인 ε는 변수의 개수가 많아지면 많아질수록 포함되거나 생성이 될 가능성이 더 많아진다. 그렇게 된다면 예측 성능이 낮아지게 될 수 있다.
또한 변수의 개수가 많다면 계산 시간이 많아질 수 있다.
이러한 차원의 저주 문제를 해결하기 위해서는 다음과 같은 방법이 있다.
-
그 Domain의 전문가들이 수작업으로 변수를 골라낸다.
-
적은 수의 변수를 선호하는 regularization을 진행한다.(Shrinkage 방법)
-
정량적인 차원 축소 테크닉 사용

이론적으로 예측 모형의 performance는 변수가 증가할수록 향상된다. 단, 변수들이 서로 독립적이어야 한다. 이는 사실상 real world data에서는 불가능하다. 실제로는 변수들이 서로 의존적이고 Noise역시 존재한다.

우리의 목적은 모델에 best하게 fit하는 subset of variables를 찾는 것.

이러한 과정을 거치면, 우리는 다음과 같은 효과를 얻을 수 있다.
-
변수들 간의 상관관계 제거
-
관리해야 하는 변수들이 단순화 됨으로써, 사후 과정이 단순해짐
-
중복되거나 불필요한 정보 제거
-
차원이 줄어듬으로써 시각화가 더 용이해진다.
supervised Dimensionality reduction vs unsupervised Dimensionality reduction
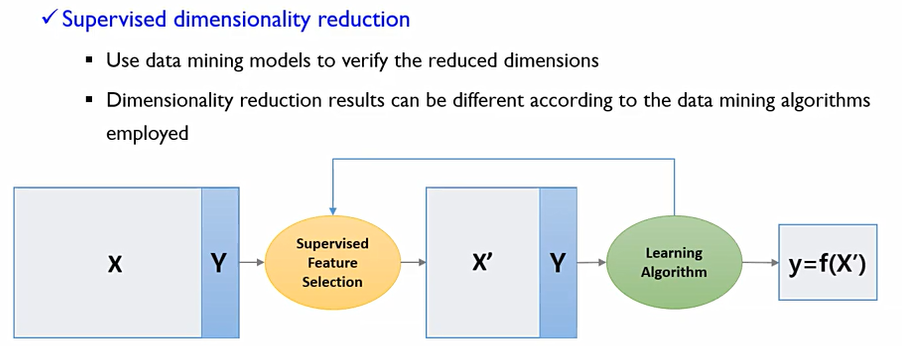
supervised Dimensionality reduction방식은 중간에 알고리즘 또는 모델이 개입을 하는 것. supervised feature selection을 통하여 차원을 줄이고, 알고리즘에서 feedback roof를 통하여 개선하는 것.
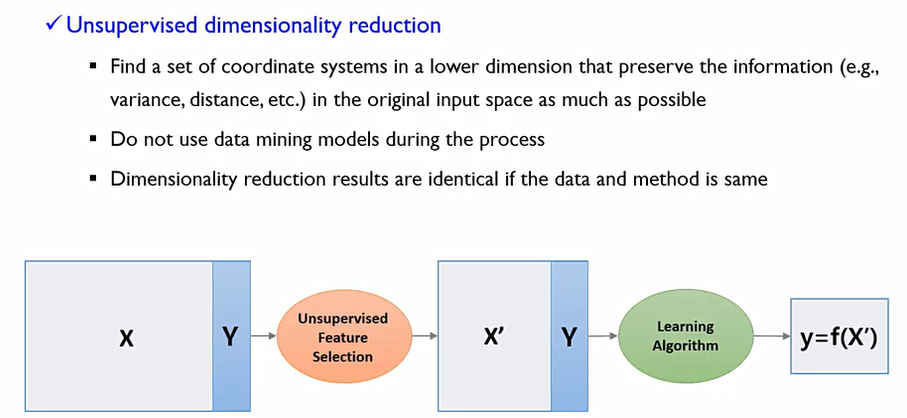
unsupervised Dimensionality reduction는 feedback roof가 존재하지 않는다. 특정한 방법이나 지표를 사용하여 한번만 실행하여 변수를 줄이는 것.
Feature selection or Feature extraction
차원 축소에 대한 결과물에 따라 selection과 extraction으로 나뉜다.

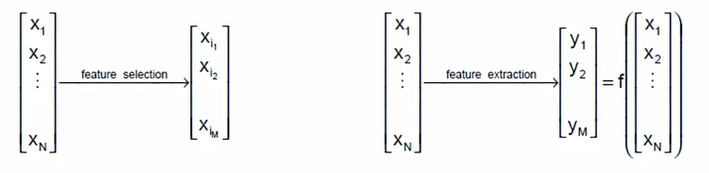
selection은 말 그대로 현재 존재하는 변수들로부터 부분집합을 뽑아내는 것
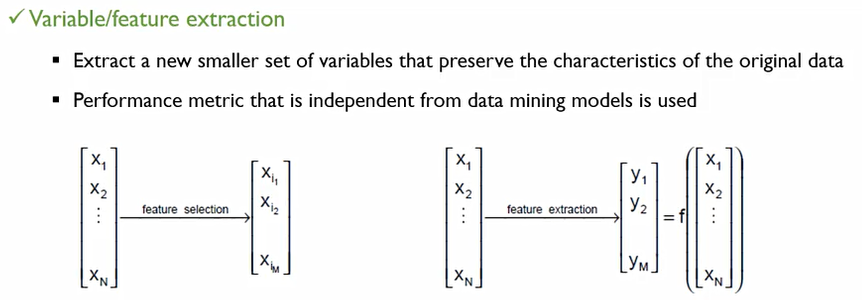
Extraction은 기존 변수들의 조합을 통하여 새로운 변수 집합을 만들어 내는 것
2. Variable Selection Methods
Exhaustive Search(전역 탐색)

모든 가능한 조합들에 대해서 다 테스트를 해보는 방법. 이때 Adjusted R^2등을 사용하여 성능을 판단해 가장 좋은 조합을 뽑아내는 것.
이 방법의 문제점은 n개의 변수가 존재할 경우 2^n-1번의 계산을 진행해야 하는 것. 현실적으로는 불가능하다.
이에 약간의 성능 저하가 있더라도 시간을 줄이는 방법을 찾아보자.
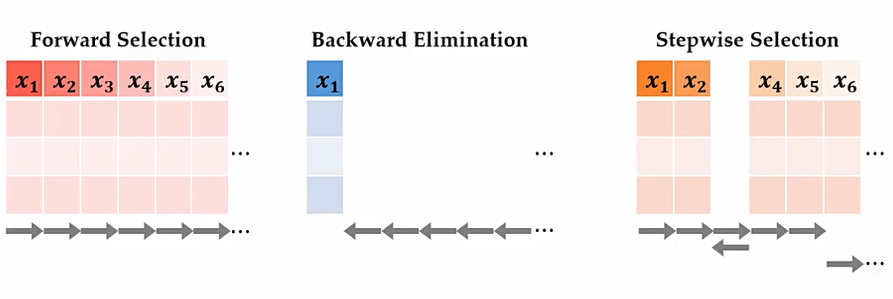
Forward selection(전진 선택법)
이는 아무것도 변수를 사용하지 않는 모델로부터 시작하여, 가장 중요할 것으로 생각되는 변수들이 순차적으로 더해진다. 이렇게 추가된 변수들은 다시는 지워지지 않는다.
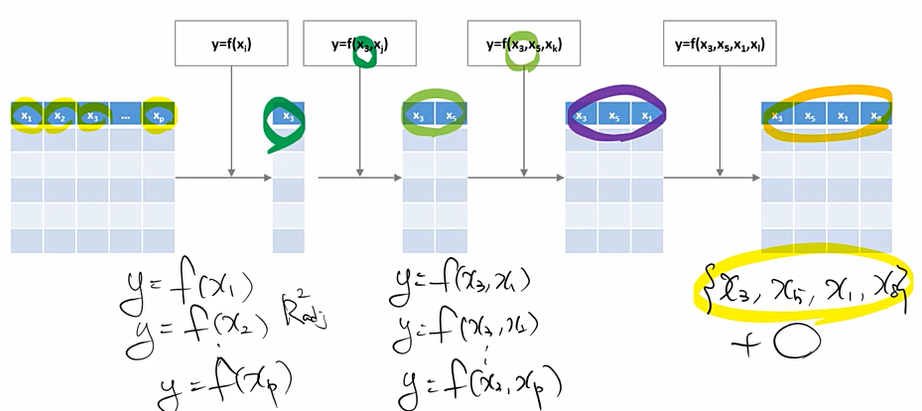
변수가 p개 있을 때, 각각 하나의 변수만을 사용하여 p개의 모형을 만든다. 이 경우 3번 변수의 성능이 좋아 이를 일단 Fix한 후, 이를 포함하는 모형을 각각 변수 p-1개와 모두 조합하여 모형을 또 만들어본다. 이때, 3과 5번 변수를 함께 사용했을 때 성능이 좋았기에 이 역시도 fix한다. 이 과정을 쭉 반복한다. 이후 어떠한 변수를 추가를 해봐도 성능의 개선이 없으면 이를 종료한다.
Backward elimination(후방 소거법)
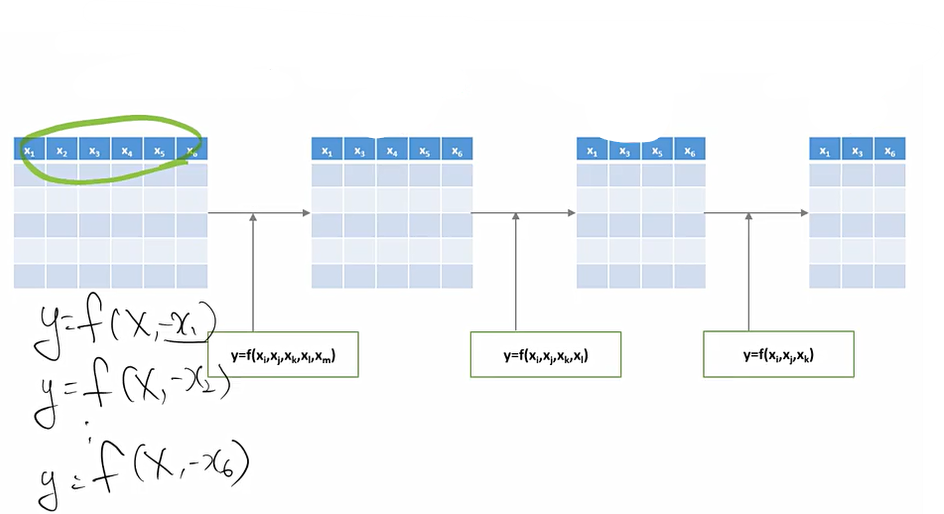
이는 모든 변수를 사용하는 모델로부터 시작하여 하나의 변수씩 제거하면서 진행된다. p개의 변수가 있을 때 하나씩 모델에서 제거하면서 성능을 확인한 후, 이 변수를 제거했음에도 모델의 성능이 좋아지거나, 변화가 미미하면 이 변수를 삭제한다. 종료 조건은 현재 조합에서 어떤 변수를 빼도 성능저하가 급격하게 일어나면 현재 존재하는 변수들은 모두 중요한 변수들이므로 알고리즘을 종료한다.
Stepwise selection
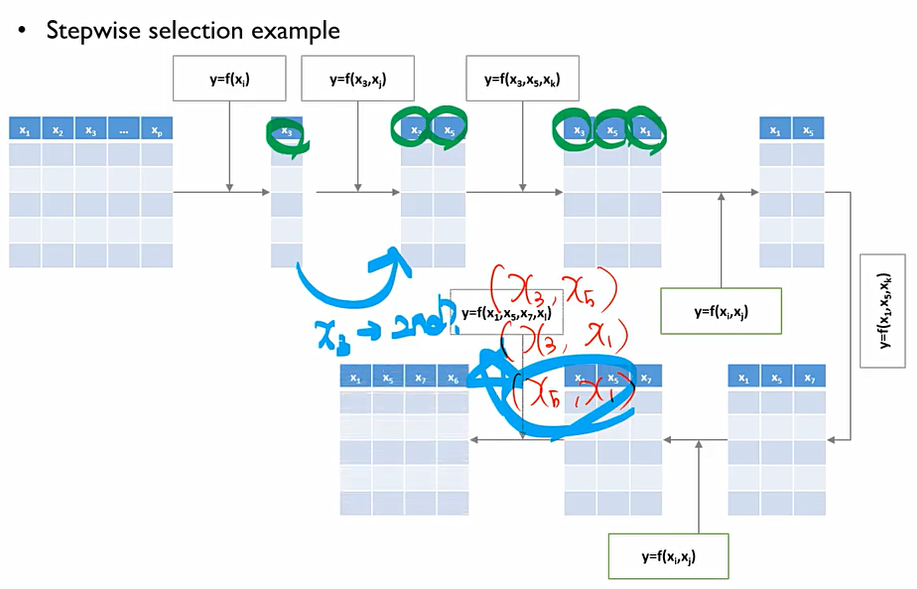
앞서 설명한 FS/BE보다는 시간이 더 들지만, 성능을 더 높이고자 하는 방법. FS와 BE를 번갈아 가면서 사용하는 것. 이때, 한번 선택이나 제거가 되었던 변수들이 다시 선택되거나 다시 제거될 수 있다.
이에 더 많은 시간을 소요하나, Optimal set of variables를 찾을 가능성이 더 높아진다.
FS/BE/SS의 비교
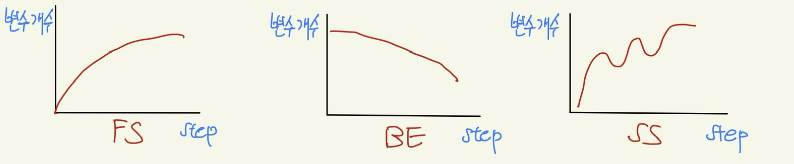
Performance Metrics
변수를 선택하는 과정에서 성능을 평가하는 지표
- Akaike Information Criteria(AIC)

- Bayesian Information Criteria(BIC)
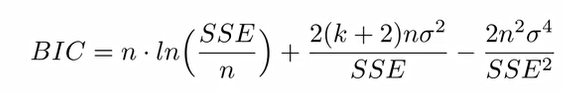
- Adjusted R^2

Genetic Algorithm(유전 알고리즘)
Stepwise selection보다도 시간은 오래 걸리나 Optimal한 performance 내는 알고리즘
더 계산시간을 투입하여 Local search(forward/backward/stepwise)의 성능을 improve시키자.
이를 Meta-Heuristic approach라고도 하는데, trial error 방식을 사용한다. 그러나 무작위로 trial하는 것이 아니라 어떻게 더 효율적으로 할 수 있을까를 고안하는 것.
이때 많은 수학적 최적화 알고리즘은 Natural system에 영향을 받아서 만들어진 것들이 많다.
이때 genetic algorithm은 양성생식에 의한 진화를 모방하는 알고리즘이다. 다윈의 자연선택설을 모사하여 수학적인 최적해를 찾는 알고리즘. 다음의 세가지 중요한 과정을 거친다.
-
selection: 현재 객체들 중 상대적으로 우수한 것을 찾자.
-
cross over: 기존 해들을 가져다가 새로운 대안을 찾자.
-
mutation: local optima에 빠지면 돌연변이를 만들어 이를 점프하여 새로운 optim을 찾자.
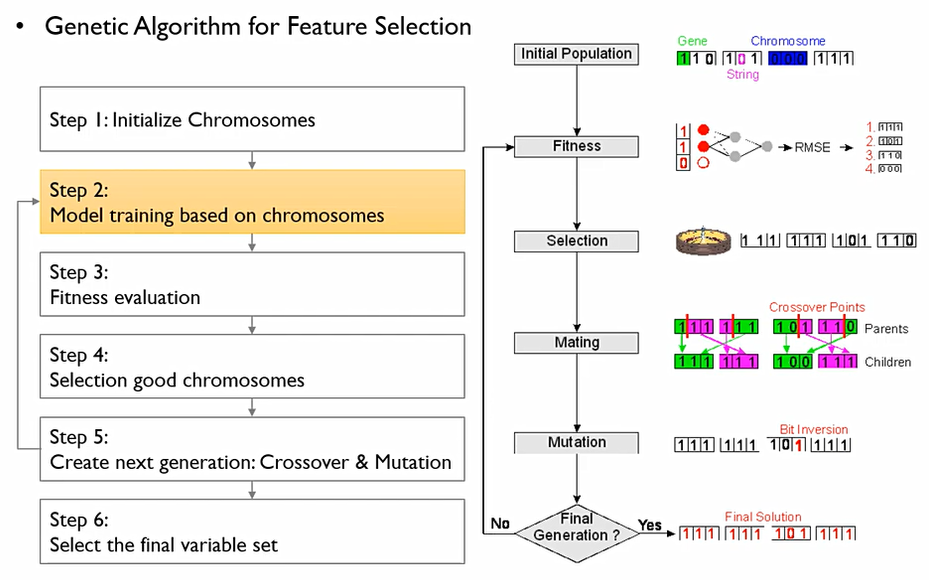
Step 1: Initialization
- Encoding chromosomes
이 방법론들을 실행하기 위한 초기화 단계. 전체 변수들의 집합을 chromosomes이라고 하고, 하나의 열을 Gene이라고 한다. binary encoding 사용. 1이면 사용하고 0이면 사용하지 않는다.
즉, 어떤 변수를 쓸 것인가에 대한 정보가 Chromosomes내의 gene에 저장되어 있는 것. 보통 chromosome은 50-100개 정도 만든다.
- Parameter Initialization
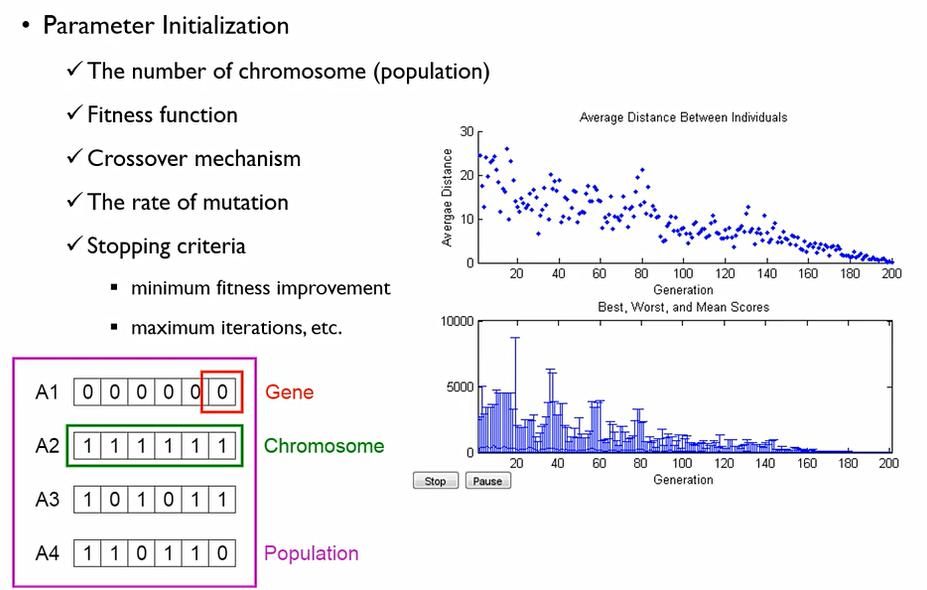
chromosome의 개수를 population이라고도 한다. Fitness function, Crossover mechanism, rate of mutation, stopping criteria은 사용자가 지정하는 하이퍼파라미터.
Step 3: Fitness Evaluation
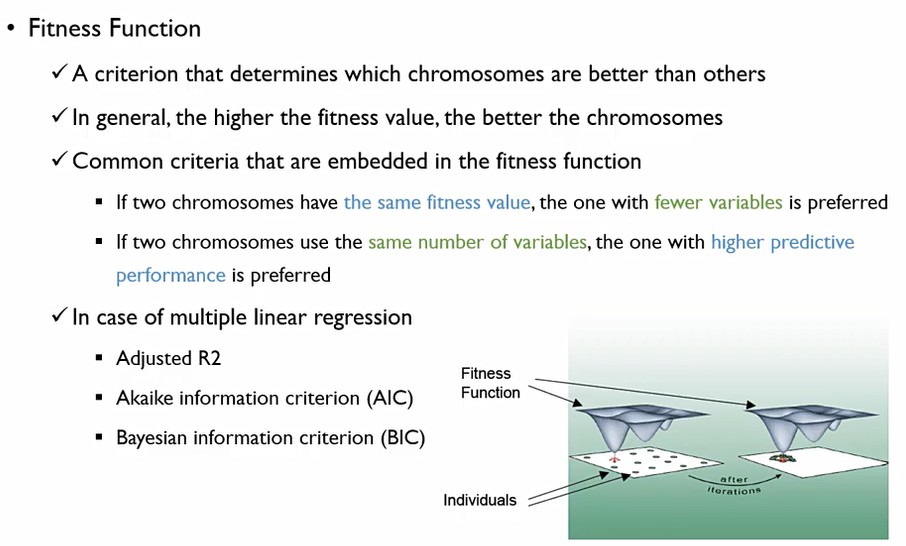
어떤 chromosomes 들이 더 나은지를 평가해주는 지표. fitness value가 클수록 chormosomes이 더 크다고 판단한다. 이전에 배운 Adjusted R^2, AIC, BIC 등 사용.
Step 4: Selection

Population에서 한 50개의 chromosomes를 잡았을 때, 이들 모두를 통해 다음 세대를 생성하는 것이 아니라 일부 우수한 chromosomes만을 추출한다. 이때, Selection에는 두 가지의 접근법이 있다.
- Deterministic selection

상위 N%에 속하는 chromosomes 모두 선택하고 나머지는 모두 out
- Probabilistic selection
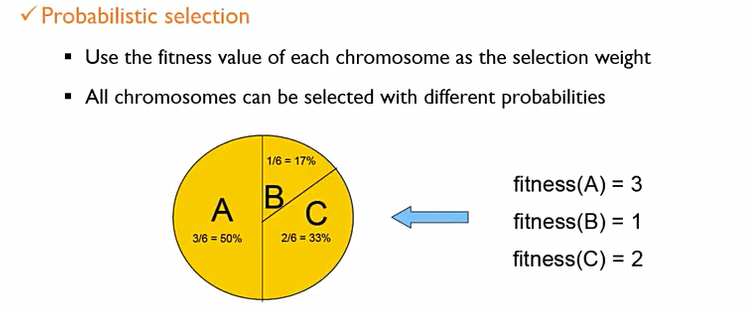
각 chromosomes이 가지는 fitness에 따라 가중치를 나눈 후, 이 가중치에 따라서 선택될 확률을 부여한 후 추출. 열등한 chromosome이라도 기회를 부여하는 것.
Step 5: Crossover & Mutation
- Crossover(reproduction)
두 개의 부모 chromosome으로부터 두 개의 자식 chromosome을 만든다. 이때 crossover를 통하여 부모 chromosome의 gene들을 랜덤하게 잘라서 이를 섞는다.
- Mutation
앞에서 만들어진 일부 Child chromosome들에 대해서 매우 낮은 확률로 값을 반대 값으로 바꿔준다. 이를 통해서 local optimum에 빠지는 것을 방지하자! 보통 0.01 확률로 해준다.
Step 6: Find the best solution
Step 2-5 과정을 Iteration만큼 반복하여 highest fitness 값을 가질때 그만둔다.
3. Shrinkage Methods
목적함수 자체에 적은 개수의 변수를 선호하도록 만드는 장치.
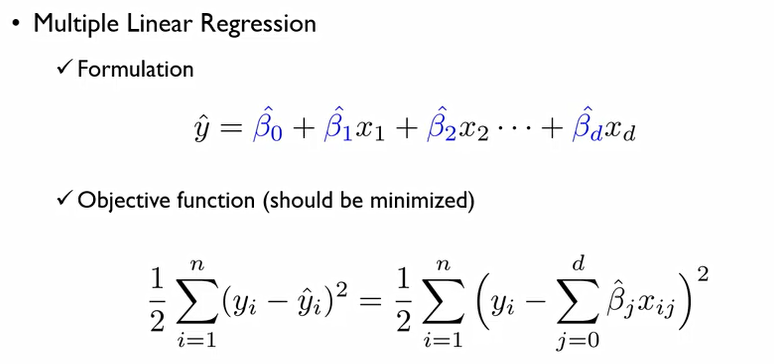
이 경우에는 목적함수 자체에 제약이 들어간다. 이에 알고리즘에 대하여 종속적이다.
핵심은 종속변수는 설명변수들에 대한 선형결합으로 표시가 된다는 것. 또한 최소화가 되야하는 값은 실제값과 추정값의 차이. 이를 OLS라고 했다.
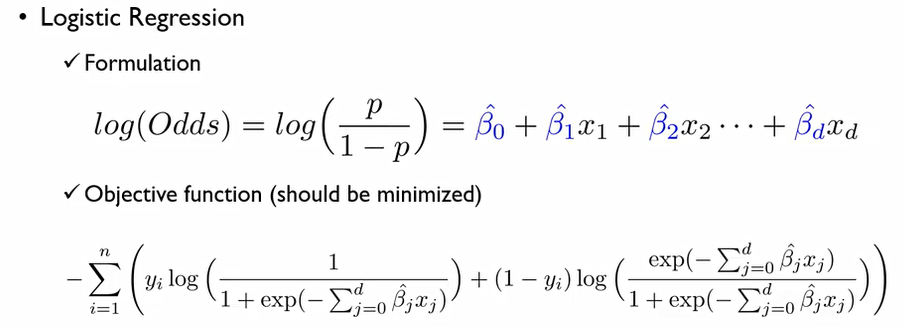
로그 승산에 대한 회귀식을 만들었기에, 오른쪽은 목적변수에 대한 회귀식.
Ridge Regression
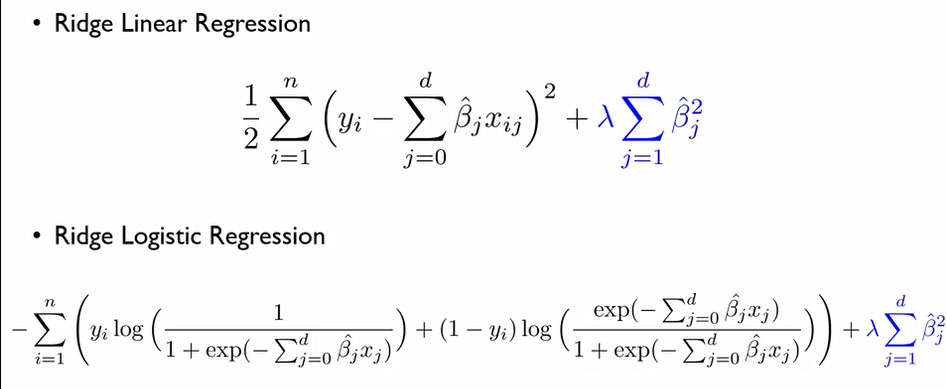
이는 선형회귀분석과 로지스틱분석 둘다 사용가능하다. 이때 핵심은 β^hat의 제곱합에 가중치 λ를 주어서 만들어지도록 하는 것. 이는 즉 Adjusted R^2 같은 값이라면 β의 크기의 제곱합이 훨씬 적은 β 조합들을 선호하겠다라는 것

이는 L2 norm을 패널티로 더한 것과 마찬가지. OLS estimate에서 구해진 β들을 점점 키워가는 β들의 조합이 있다고 할때, Ridge regression이 원하는 것은 원점을 중심으로 원을 만들어가며 OLS estimate의 등고선과 만나는 점을 최종적인 해로 찾겠다라는 것.
두 모델이 같은 Performance 일때는 작은 regression coefficients를 가지는 모델을 선호하겠다라는 것.
그러나 Rigde regression은 변수를 직접적으로 선택하는 기법은 아니다. 제곱이기 때문에 coefficient가 매우 작은 값을 가질 순 있어도 0으로 수렴하지는 않는다. 이에 변수들 사이에 높은 상관관계가 있을때 잘 작동하는 방법이다.
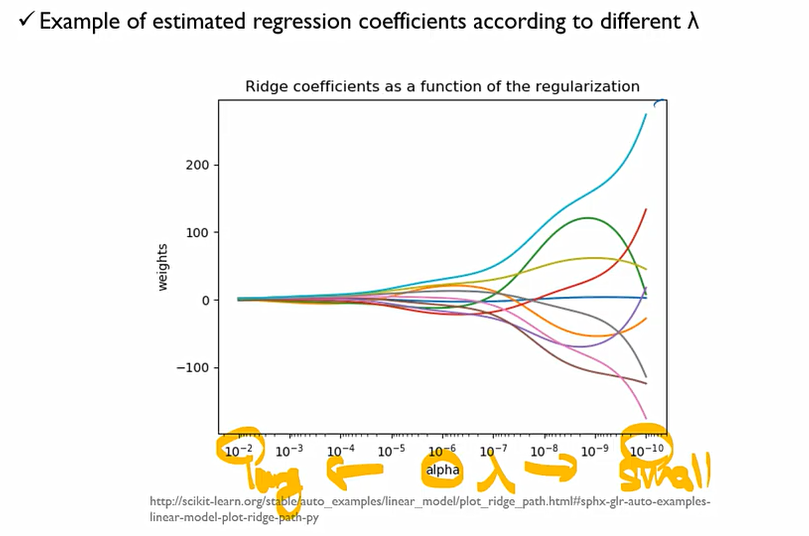
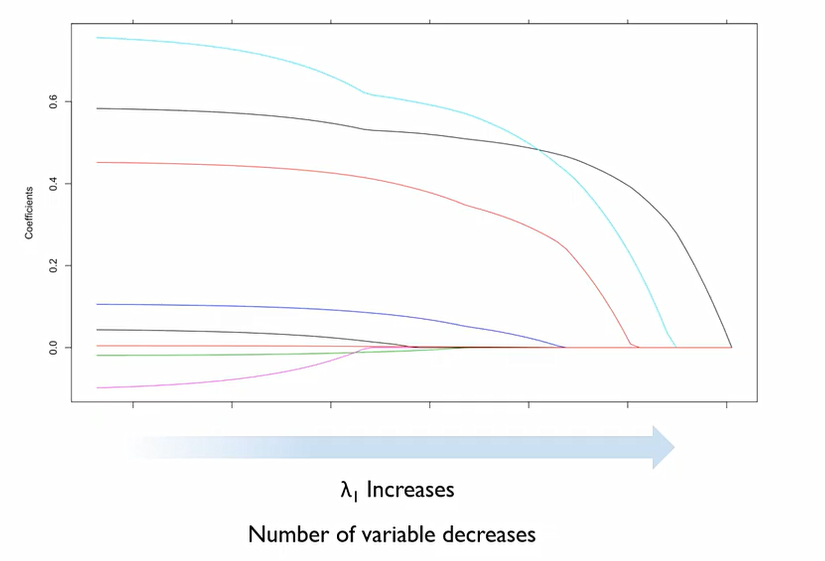
이 그래프에서 각각의 선들이 각각의 변수라고 생각했을 때, λ가 하는 것은 OLS의 해와 β를 얼마나 작게 할 것인가에 대한 Trade off를 조정하는 역할을 하는 것.
LASSO

변수를 선택할 수 있다. 여기서는 회귀값들의 절대값들의 합(L1에 대한 패널티)을 패널티로 준다.

왼쪽은 Lasso, 오른쪽은 Ridge
Rigde에서는 L2 Norm에 해당하는 패널티를 주고, LASSO에서는 L1 Norm에 해당하는 패널티를 준다.
Rigde에서는 어떤 β값도 0이 되지 않지만, Lasso에서는 상대적으로 덜 중요한 β는 0이 되어버릴 수 있다. 즉, 해당 β에 해당하는 변수는 사용하지 않게 되는 것.
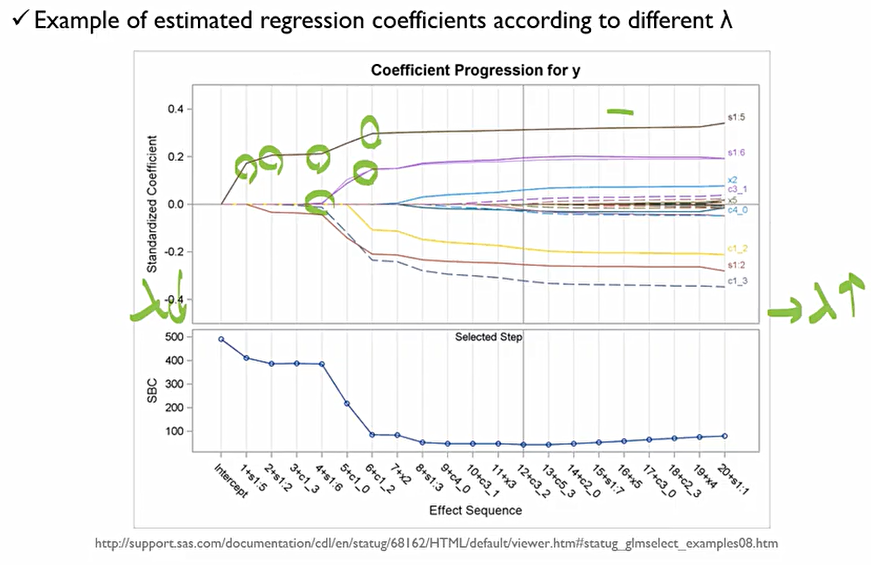
Ridge와는 다르게 λ를 조정하는 과정에서 뚝뚝 끊어지는 것을 확인할 수 있고, 특정 λ 값을 지나면 변수가 그냥 0이 되어버리는 것도 확인할 수 있다.
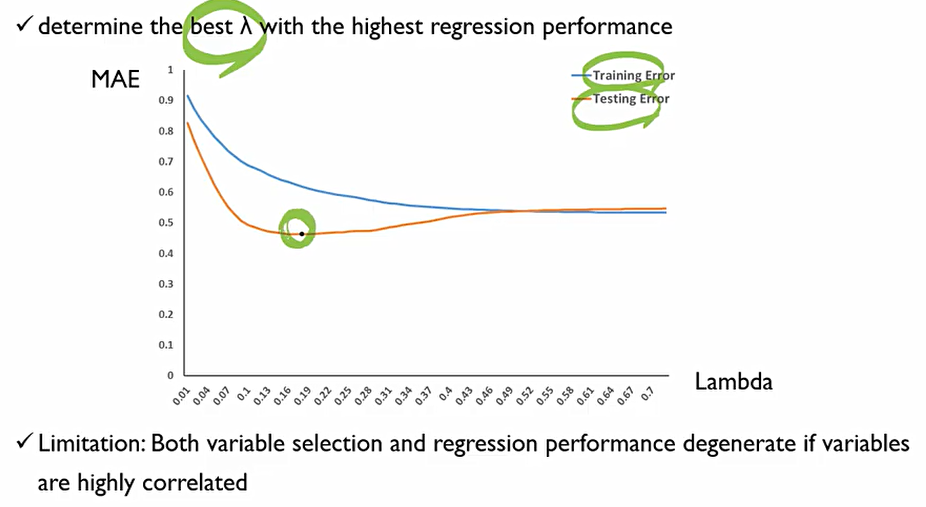
그렇다면, λ값을 어떻게 정해야 할까? 학습용 데이터와 테스트 데이터를 같이 사용 해서, λ값이 커질때 학습용 데이터와 테스트 데이터가 가장 적게 나타나는 부분의 λ를 사용하는게 일반적인 방식.
Elastic Net

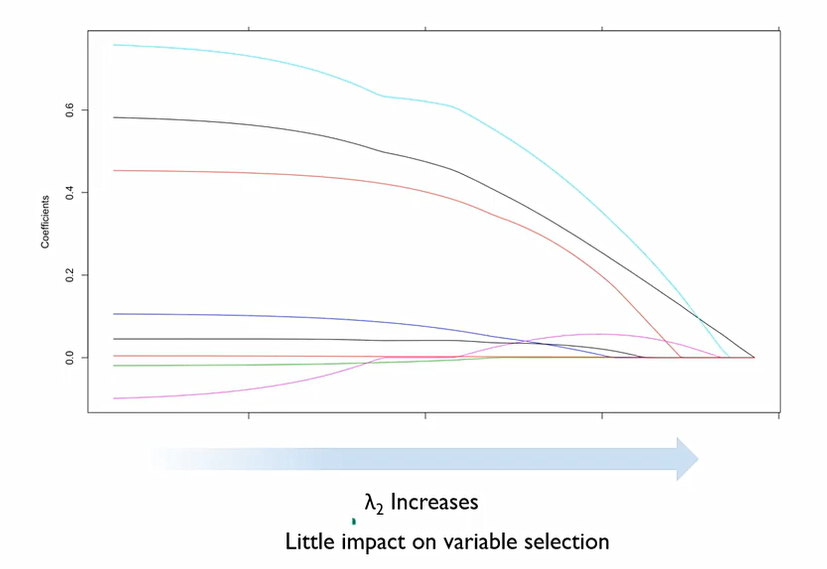
Ridge가 가지는 장점인 두 변수 사이의 correlation이 있을 때 이를 제외할 수 있다는 것과 Lasso가 가지는 장점인 변수 선택을 결합한 것.
L1, L2의 패널티를 모두 부여하는 것. 이때 각각 두개의 λ를 가진다.