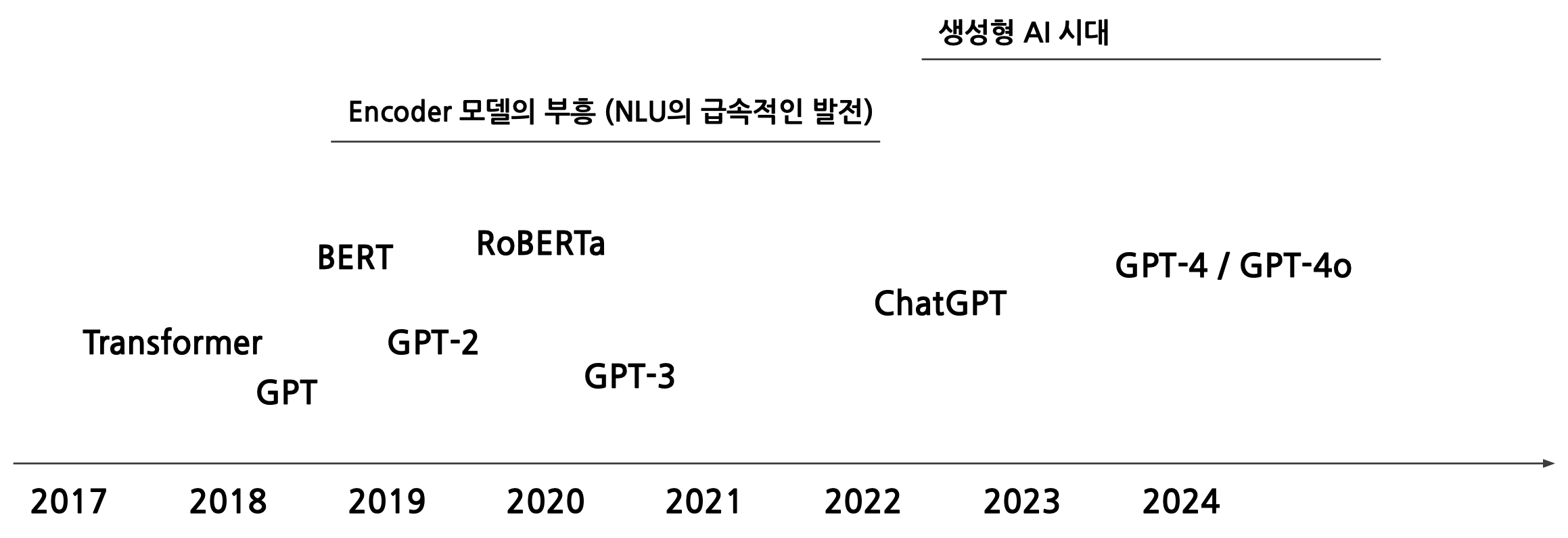
들어가며
Transformer의 등장에서, 학습된 모델들은 기본적으로 완전히 weight, parameter가 random initialized부터 학습을 시작.
Transformer의 등장까지만 해도, Encoder-Decoder이라는 구조에 대한 변화만 있었을 뿐, 모델 성능의 큰 향상은 없었다.
GPT의 등장도 처음에는 Decoder 부분만 떼어와서 학습에 이용을 한 것이었다. 또한 굉장히 적은 양으로 학습을 했다. BERT은 구글에서 내놓은 Encoder-only 모델로, OpenAI을 따라서 발표한 모델이다. BERT을 학습한 데이터도 크지 않았지만 성능은 매우 높았다.
이후에는 연구들이 대부분 BERT 모델을 기반으로, Encoder 모델을 기반으로 연구가 많이 이루어졌다. RoBERTa 또한 더 많은 데이터로 학습한 것일 뿐, 모델 구조에 혁신적인 변화는 없었다.
반면 OpenAI은 꾸준히 GPT을 밀고 있었다. GPT-2은 말을 너무 잘 생성하여 악용될 우려까지 있어서 model의 weight을 공개하지 않았다. GPT-3부터는 크기가 100B이 넘어가면서, 거대 언어 모델로 바꾸어가는 변화가 일어났다. 여기까지만 해도, Next-token만 생성하는 앵무새가 아니냐 하는 느낌이 있었는데, ChatGPT service가 나오고, GPT-4, GPT-4o가 나오고 있다.
그렇다면, Encoder은 무엇을 하고 있는가?
Encoder-Decoder Model
종류: Transformer, BART, T5 등
- 인코더-디코더 모델은, 인코더에서 정보를 해석하고 디코더에서 생성하는 형태이다.
- 인코더의 정보를 디코더에서 Cross-Attention 연산을 통해 생성할 때, 인코더 정보를 추가적으로 활용한다.
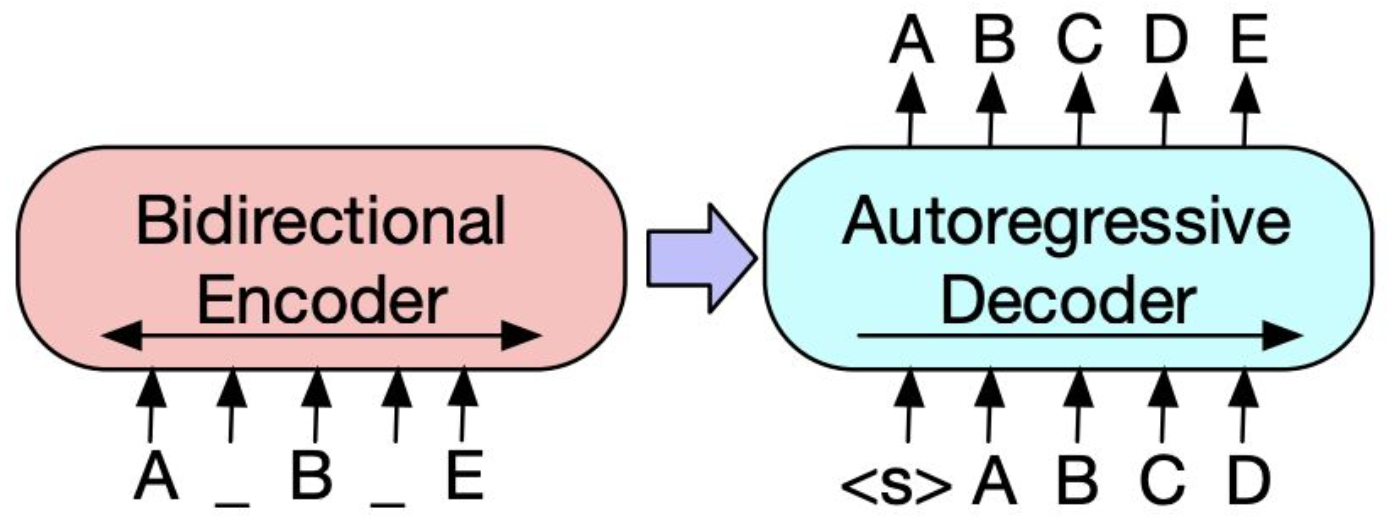
- 위의 그림에서, 불연속적인 정보를 인코더가 손실압축된 정보를 디코더에 가져다주면, 디코더는 그 불연속적인 정보를 예측하여 메꾼다.
- 인코더는 서로가 모든 토큰을 확인하는 과정(Biderectional Encoder)을 해주고,
- Auto-regressive Decoder 같은 경우는, 생성된 앞쪽 부분만 보고 뒤의 내용을 생성한다.
- Bidirectional Encoder만 사용하면 BERT 같은 모델이 되고, Autoregressive Decoder만 사용하면 GPT와 같은 모델이 된다. 둘 다 사용하게 되면 Encoder-Decoder Transformer와 같은 모델이 된다.
Encoder-Decoder Model의 활용
- Encoder-Decoder 모델은 기계 번역, 요약, Generative QA 등에 사용되었다.
그러나
- Generative라고 하긴 해도, 단어, 단락 수준에 그치기 때문에 디코더 모델보다는 성능이 떨어진다.
- 기계 번역의 output 문장 길이에 대해서도 한계가 있었다.
- 인코더-디코더 모델 구조 자체에서, self-attention 뿐만 아니라, 연결부의 cross-attention 또한 처리를 해줘야 하는데, 계산량이 많아 병목이 많았다.
- 확장성 측면에서도 input으로 사용하는 양이 적다보니 최적화하는데 비용 소모가 컸다.
- 그래서 어느 순간부터 Encoder-Decoder 모델을 쓰지 않고 있다.
Encoder-only Model
BERT: Bidirectional Encoded
- BERT가 학습하는 방법?: 다음에 올 토큰을 예측하는 방식!
- 언어 모델은 (분류/회귀) 문제 중, 분류 방법을 많이 사용한다. Encoder는 불연속적인 정보를 연속적인 벡터 공간으로 압축하는 역할을 하는데, 이 압축된 벡터를 어떻게 만들도록 학습해야 할까?
- Self-supervised Learning: (스스로 진행하는 학습) BERT는 라벨링이 되어있지 않은 데이터로 사전학습을 한다.
- 32,000개의 단어 중 1개의 단어를 Mask 처리하고, 이걸 예측하도록 학습을 수행한다.
- 보통 시작하는 [CLS] 토큰을 만들어두고, 그 토큰의 벡터를 가져다가 768차원의 벡터를 가지고, nn.Linear(768,2)을 학습된 BERT 모델 밑에 붙여서 학습을 추가로 진행해주면, 사전에 학습된 방법을 이용해 분류를 잘 할 수 있게 된다.
Encoder-only Model의 활용
- Encoder-only 모델은 문서 분류(감정 분석, 스팸 필터링 등), 정보 검색(IR, 임베딩), Extractive QA(이 질문에 대한 정답이 제시문의 어느 부분에 있나요? -> 정답의 위치를 뽑아내준다)
그러나
- Sequential Task, 생성 task에 대한 한계가 있다. 하나의 단어만 맞추는 건 잘 할 수 있지만, 연속된 여러 개의 mask 토큰을 예측하거나 자연스러운 문장을 만드는 것에는 한계가 있다.
Decoder-only Model
GPT: Generative Pre-trained Transformer
Causal Language Model: 앞 토큰 문맥을 토대로 이후의 토큰을 예측하는 방식이다. 생성 task에 강점!
- GPT 같은 경우는, 우리가 사전학습할 때 쓴 '다음 토큰을 예측하는 방법'을 생성할 때도 사용하기 때문에, 생성형 task에서도 좋은 결과를 내고 성능 측면에서도 좋다.
- 또한 MLM은 15% 정도를 mask 처리하고 학습을 하는데, BERT 모델은 이 15%에 대해서만 학습이 이루어진다. 즉, 85% 정도는 학습할 때 직접적으로 쓰이지는 않게 되는 것이다. 그런데 GPT으로 학습하는 경우에는 모든 데이터를 이용해 학습하기 때문에 더 효율성도 뛰어나다.
- 이렇게 해서 모델 사이즈를 점점 크게 하는 길로 갔다. 모델 사이즈를 키우고, 학습량을 증가하면 성능이 기하급수적으로 증가했다. (Emergent Abilities) 100 bilion 정도의 모델 크기를 넘어설 때부터 성능이 갑자기 좋아진다! 이는 모델이 다양한 분야에서 쓰일 수 있도록 하는 근본적인 해결책 역할을 했다.
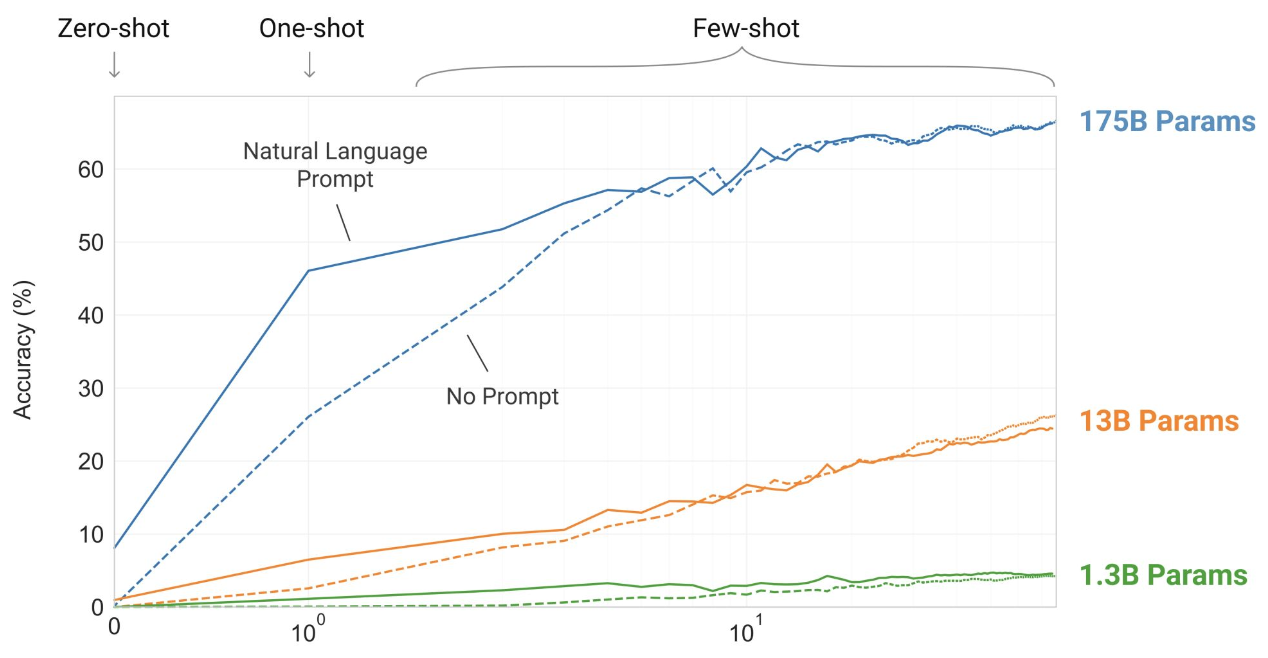
Emergent Ability이란?
Emergent Ability란 모델의 크기와 복잡성이 증가함에 따라, 사전에 명시적으로 훈련되지 않은 새로운 능력이 자발적으로 나타나는 현상을 의미한다. 이는 특정 임계점 이상의 규모와 데이터로 학습된 모델에서 관찰된다.
Decoder-only Model의 Emergent Ability은 추론 능력, 언어적 창의성, 그리고 문맥 기반 학습을 통해 NLP 시스템의 가능성을 열어준다. (적응성-훈련 데이터에 없던 새로운 작업을 처리 가능, 효율성-별도의 모델 재학습 없이 새로운 작업 수행, 범용성-다양한 도메인과 작업에서 일관된 성능)
이러한 특성은 범용 인공지능(AGI) 의 초기 단계로 이어질 가능성을 시사한다.
Emergent Ability의 예시로는,
Few-shot Learning
모델은 학습 과정에서 Few-shot 학습을 위한 특별한 데이터로 훈련받지 않았더라도, 프롬프트에 몇 가지 예시를 제공하는 것만으로 해당 작업을 수행할 수 있다.
예: 문법 오류 교정, 질의응답, 번역 등Zero-shot Learning
사전에 훈련되지 않은 새로운 작업이나 도메인에서도 프롬프트만으로 작업을 수행한다.
예: 새로운 언어로 번역 요청, 설명 생성문맥 기반 문제 해결
모델은 긴 문맥을 유지하고, 이 문맥 내에서 정보 추출, 요약, 논리적 추론 등의 작업을 수행할 수 있다.
예: 특정 인물이나 사건에 대한 맥락적 질문에 답변추론 능력
특정 크기 이상의 모델에서는 논리적 추론 및 수학적 계산과 같은 고차원적 사고 능력이 관찰된다. 모델이 크고 복잡할수록 이 추론능력이 더 잘 발달한다.
예: 숫자나 개념 간의 관계를 이해하고 문제 해결
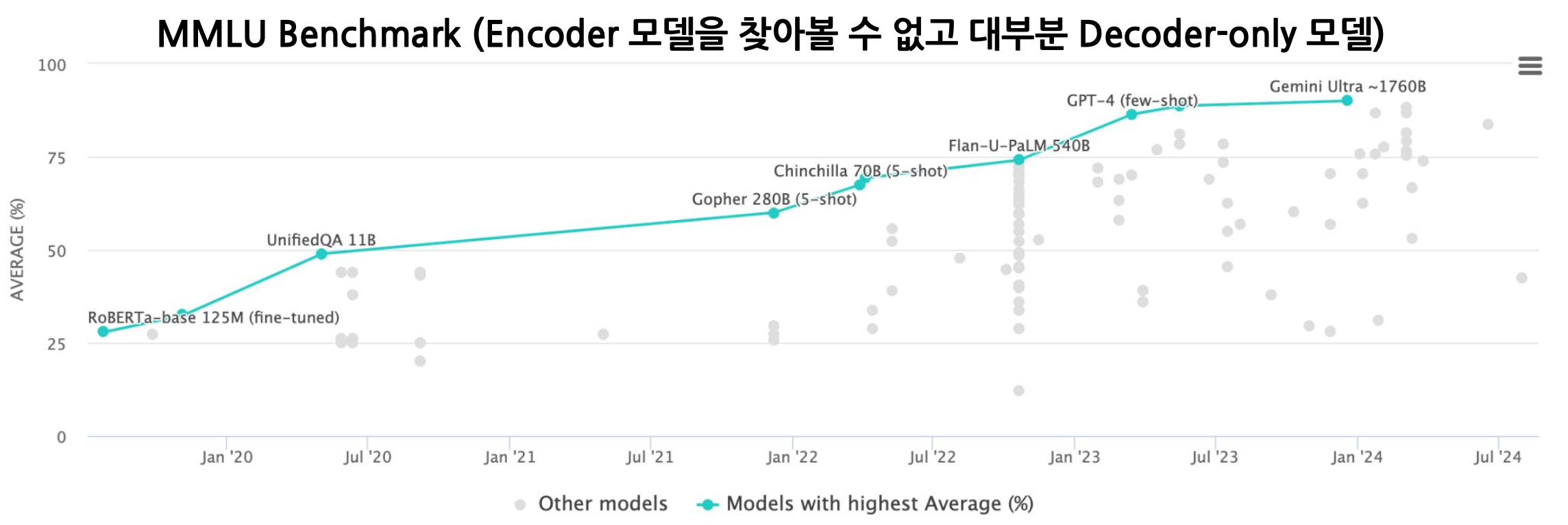
- 점점 벤치마크 데이터셋이 무의미해지고 있다.
- 그러면, 얘네는 생성만 잘 하나? 아니다. NLU task에 있어서도 훨씬 더 쉽게 잘 수행한다. Fine-tuning이 따로 필요없을 정도!
LLM Model
Decoder-only 모델에서, 파라미터 수를 아주 많이 늘린 게 결국 LLM 모델이다.
- Encoder-Decoder 모델보다 학습 및 추론 속도가 빠르고, Scailing UP(15%을 따로 마스크 처리할 필요없이, 그냥 다 가져다가 학습에 쓴다)에 강점이 있다.
- In-Context Learning을 더 길게 넣어줄 수 있다. 예시를 엄청나게 많이 넣어주는 방식이다.
In-Context Learning
우선 In-context learning과 Few-shot learning은 거의 같은 말이다.
Shot이라는 것 자체가, 예시를 몇 개나 쓰냐를 말하는 것이다. One-shot은 하나의 예시만, Few-shot은 N개의 예시를 넣어주는 것이다.
Chain-of-Thought (CoT)
몇 개의 예제만으로는 파악하기 어려운 문제들(수학 등의 문제)이 있다. CoT은 디코더 모델이 생성을 할 때, 바로 답변을 생성을 하는 것이 아니라, 그 이유에 대해서 먼저 생각하도록 처리하는 것이다.
사실 이것도 One-shot example이긴 한데, 이유를 생성함으로써 정답에 조금 더 가까워지도록 유도하는 방식이다.
Human Alignment
위처럼 모델이 사용자의 요구에 적합한 출력을 생성하고, 의도에 맞게 행동하도록 학습시키는 방법이다.
Instruction Tuning
다양한 작업과 사용자 지시를 포함한 데이터를 사용하여 모델을 학습시키는 과정이다.
RLHF
인간의 피드백을 활용하여 모델이 더 바람직한 출력을 생성하도록 학습시키는 강화학습(Reinforcement Learning) 기법이다.
