Redis란 무엇일까? - Redis의 특징과 사용 시 주의점

웹, 인공지능, 빅데이터 등이 생겨나고 데이터 정보의 크기가 커지면서 DB의 한계가 생기는데,
이는 SSD로 많이 개선되었지만 여전히 디스크에 데이터를 저장해야하므로 이 또한 한계에 다다르게 된다.
이번 포스팅에서는 데이터를 하드디스크나 SSD에 저장하지 않고 메모리에 저장하는 In-Momory DB인 Redis에 대해서 알아볼 예정이다 !
✏️ Redis
-
고성능 Key-Value 구조의 저장소
-
비정형 데이터를 저장, 관리하기 위한 오픈 소스 기반의 NoSQL
📌 NoSQL에 대한 자세한 개념은 아래 포스팅을 참고해주세요.
-
In-Memory 데이터 구조를 가진 저장소
-
DB, Cache, Message Queue, Shared Memory 용도로 사용됨
👉 웹 서버의 부담을 획기적으로 줄이고, 고속으로 데이터 제공이 가능
✔️ 인메모리 ( In-Memory )
- 컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용하는 방법
- RAM에 데이터를 저장하게 되면 메모리 내부에서 처리가 되므로
데이터를 저장/조회할 때 하드디스크를 오고가는 과정을 거치지 않아도 되어 속도가 빠름
⠀
But, 서버의 메모리 용량을 초과하는 데이터를 처리할 경우,
RAM의 특성인 휘발성에 따라 데이터가 유실될 수 있음
✔️ 휘발성
➜ 전원이 꺼지면 가지고 있던 데이터가 사라지는 특성
💡 기존 DB가 있는데도 Redis를 사용하는 이유가 뭘까?
DB는 데이터를 디스크에 직접 저장(write)하기 때문에 서버에 문제가 발생하여 다운되더라도 데이터가 손실되지 않는데
매번 디스크에 접근해야하기 때문에 사용자가 많아질 수록 부하가 많아져서 느려질 수 있어서 캐시 서버를 도입하여 사용해야한다.
이 캐시 서버로 이용할 수 있는 것이 바로 Redis이다.
⠀
👉 같은 요청이 여러번 들어올 때 Redis를 사용함으로써
매번 DB를 거치지 않고 캐시 서버에서 저장해놨던 값을 바로 가져와
DB의 부하를 줄이고 서비스의 속도도 느려지지 않게 할 수 있다 !
✔ Redis의 특징
-
Key, Value 구조
-
빠른 처리 속도
➜ 디스크가 아닌 메모리에서 데이터를 처리하기 때문에 속도가 빠름 -
Data Type(Collection)을 지원
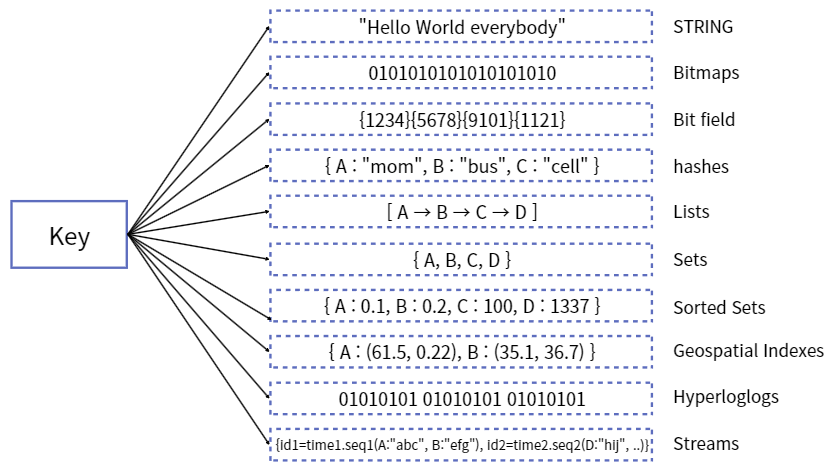 ➜ 개발의 편의성, 생산성이 좋아지고 난이도가 낮아짐
➜ 개발의 편의성, 생산성이 좋아지고 난이도가 낮아짐Ex.
DB에 데이터를 저장하고, 저장된 데이터를 정렬해서 다시 읽어오는 과정은 디스크에 직접 접근해야하기 때문에 시간이 걸리는데,
인메모리 DB인 Redis를 사용하고 Redis에서 제공하는 Sorted-Set 자료구조를 사용하면 좀 더 빠르고 간단하게 데이터 정렬 가능 -
AOF, RDB 방식
➜ 인메모리 데이터 저장소가 가지는 휘발성의 특성으로 데이터가 유실될 경우를 방지하여 백업 기능을 제공- AOF (Append On File) 방식
➜ Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태
⠀ - RDB(Snapshotting) 방식
➜ 순간적으로 메모리에 있는 내용 전체를 디스크에 담아 영구 저장하는 방식< 참고 >
Redis 공식 사이트 - Redis persistence
Redis - Persistence 란? 참고
Redis의 백업(RDB, AOF) 알아보기참고
- AOF (Append On File) 방식
-
Redis Sentinel 및 Redis Cluster를 통한 자동 파티셔닝을 제공
➜ Master와 Slaves로 구성하여 여러대의 복제본을 만들 수 있고, 여러대의 서버로 읽기를 확장 가능✔️ 파티셔닝 ( Partitioning )
- 다수의 Redis 인스턴스가 존재할 때 데이터를 여러 곳으로 분산 시키는 기술
- 각 Redis 인스턴스는 전체 키 중 자신에게 할당된 일부 파티션의 키들만 관리하게 됨
[ 참고 - Partitioning: how to split data among multiple Redis instances ]
[ 참고 - Redis 운영 방식 : Cluster vs Sentinel 어떤 것을 선택해야 할까 ? ]
-
다양한 프로그래밍 언어 지원
-
싱글 스레드
➜ 한번에 하나의 명령만 수행이 가능하므로 Race Condition이 거의 발생하지 않음✔️ Race condition
- 공유 자원에 대해 여러 프로세스가 동시에 접근을 시도할 때, 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
- 즉, 두개의 스레드가 하나의 자원을 놓고 서로 사용하려고 경쟁하는 상황에서 발생
- 프로그램의 일관성과 정확성을 손상시킬 수 있음
⠀
Ex.
두개의 스레드 A, B가 X라는 공유변수를 사용하는데, A의 역할은 X에+ 1후 저장 / B의 역할은 X에- 1후 저장일 때
A가 X를 읽은 후 B가 실행되기 전에 결과를 저장한다고 하면, A의 결과가 스레드 B의 결과데 덮어씌워지게 됨
[ Race Condition 참고 ]
✔ Redis 사용 시 주의할 점
-
시간 복잡도
➜ Single Threaded(싱글 스레드) 사용으로 한번에 하나의 명령만 수행이 가능하므로 처리 시간이 긴 요청의 경우 장애가 발생 -
메모리 단편화
➜ 크고 작은 데이터를 할당하고 해제하는 과정에서 메모리의 파편화가 발생하여 응답 속도가 느려질 수 있음✔️ 메모리 단편화 (Memory Fragmentation)
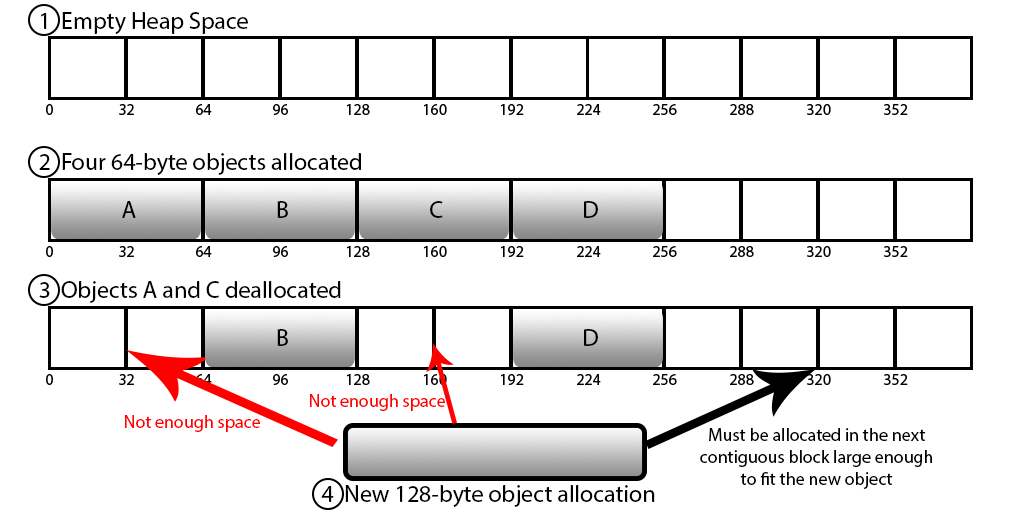
➜ RAM에서 메모리를 할당받고 해제하는 과정에서 위와같이 부분부분 빈 공간이 생기는데,
새로운 메모리 할당 시에 사용 가능한 메모리가 충분히 존재하지만 메모리의 크기만큼의 부분이 없어 마지막 부분에 할당되어 메모리 낭비가 심하게 됨
⠀
➜ 이 현상이 계속되면 실제 physical 메모리가 커져 프로세스가 죽는 현상이 발생 할 수도 있으므로, redis를 사용 시에 메모리를 적당히 여유있게 사용하는 것이 좋음
[ 메모리 단편화 참고 ] -
주기적인 모니터링
➜ 메모리 사용량이 너무 많으면 Redis 서버의 성능 저하나 장애로 이어질 수 있기 때문에 주기적인 모니터링을 통해 메모리를 관리해주어야함
🌼 Redis 설치 방법
[ 참고한 사이트 ]
📌 다음 포스팅은 Redis로 로그아웃 기능 구현하기에 대한 내용입니다.
⠀
👉 [Project] Redis로 로그아웃 기능 구현하기 !
