이전까지 설명한 GAN의 개념과 내용을 바탕으로 Tensorflow2를 이용하여 MNIST 이미지를 생성하는 모델을 학습시키고 해당 코드의 내용을 분석하며 실습하겠습니다.
이번 실습은 아래와 같은 결과물을 생성 할 수 있습니다.


심층 합성곱 생성적 적대 신경망 | TensorFlow Core
아래 링크에서 본 문의 코드를 확인 할 수 있습니다.
실습 환경
- Google Colab(GPU)
- Tensorflow 2.0
필요한 라이브러리 설치 및 Import
!pip install tensorflow-gpu==2.0.0-rc1
!pip install imageiotensorflow-gpu
Colab에서 GPU를 사용하는 tensorflow
imageio
GIF 이미지를 만들기 위한 Library
# python 표준 라이브러리
import os
import time
import glob
# 오픈소스 라이브러리
import tensorflow as tf
from tensorflow.keras import layers
import imageio
import matplotlib.pyplot as plt
import numpy as np
import PIL
# Colab Notebook Library
from IPython import displayglob
쉘이 사용하는 규칙에 따라, 지정된 패턴과 일치하는 모든 경로명을 찾는 라이브러리입니다. 데이터 셋을 구성하기 위해, 지정된 경로 내의 FileName을 가져오는 용도로 사용합니다.
matplotlib.pyplot
공식 문서 https://matplotlib.org/stable/users/index.html
본 실습에서는 Colab에서 셀의 결과로 이미지를 출력하기 위해 사용합니다.
PIL
Pillow, 파이썬 이미지 처리 라이브러리
IPython.display
쉘의 출력을 제어 할 수 있는 모듈
데이터셋 준비
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()Tensorflow에서 제공하는 API Dataset 중, MNIST Dataset이 있습니다.
https://www.tensorflow.org/api_docs/python/tf/keras/datasets/mnist
위 처럼 함수 호출 한 번으로 MNIST Dataset을 한 번에 호출하고 다중 할당을 이용하여 train_images에 (60000, 28, 28)의 Numpy 배열 데이터를 할당 할 수 있습니다.
이제 train_images에는 6만 장의 MNIST 데이터가 저장되었습니다.
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # 이미지를 [-1, 1]로 정규화합니다.train_images 내부의 각각의 이미지는 현재 0~255 까지의 값을 갖는 Int Type 픽셀으로 구성된 GrayScale 이미지입니다.
GAN을 구성 할 때는 0~255까지의 값을 가지고 연산하는 것보다, 0 ~ 1 또는 -1 ~ 1까지의 값으로 연산하는 것이 경험적으로 더 높은 성능을 보입니다.
이유를 추측하자면, 훈련 과정에서 loss가 0~1사이의 값을 갖는 것이나, Discrimiator 모델이 판별 값으로 0~1사이의 값을 출력하는 것과 가까워서 그렇지 않을까 싶습니다.
따라서, train_images 내부 요소들의 Data Type을 float32 타입으로 변경하고, 0~255 사이의 값을 -1~1사이의 값을 갖도록 연산합니다.
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# 데이터 배치를 만들고 섞습니다.
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)Tensorflow에서는 편의를 위해 다양한 API를 제공합니다. 그 중 하나로 from_tensor_slices 함수로 반환되는 BatchDataset 타입의 데이터는 shuffle 메소드로 매 Epochs에서 데이터를 섞어 줄 수 있고, 지정된 Batch Size 만큼 자동으로 분할하여 반복 가능한 객체를 만들어 줍니다.
물론 훈련과정에서 6만개의 데이터를 반복문을 이용해 일일이 반복 할 수도 있고, 매 Epochs 에서 데이터의 순서를 섞는 일도 작성 할 수 있습니다.
모델 구성
Generator
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(128, activation='relu', input_shape=(100,)))
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(28*28*1, activation='tanh'))
model.add(layers.Reshape((28, 28, 1)))
return model작성한 코드의 구조를 그림으로 나타내면 아래와 같습니다.
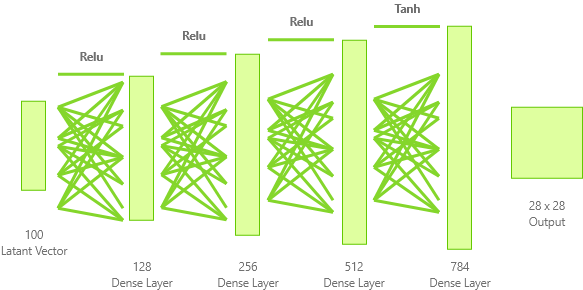
단순히 Latant Vector z를 입력으로 받아, Dense Layer(완전 연결 신경망)을 겹겹히 쌓아 출력의 전체 개수인 784개의 뉴런까지 확장하는 모습입니다.
Relu 활성화 함수를 사용하고, 마지막 Layer에서 Tanh 활성화 함수를 사용하여 뉴런의 값을 -1~1사이로 확정시킨 모습입니다. Tanh 활성화 함수를 사용한 이유는 Train Dataset을 -1~1사이의 값으로 전처리 시켜준 것과 이어서 생각 할 수 있겠네요.
Discriminator
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(1))
return model작성한 코드의 구조를 그림으로 나타내면 아래와 같습니다.
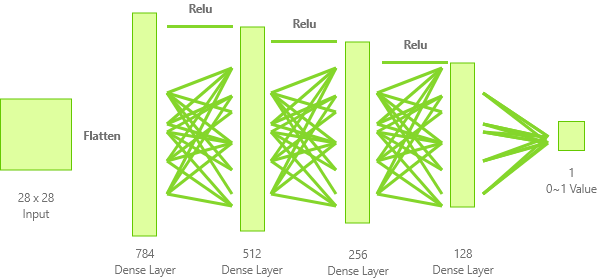
앞선 Generator와 거의 반대되는 모습입니다. 입력으로 받은 28x28 크기의 데이터를 1차원 Vector 형태로 변환한 후, Dense Layer를 이용하여 점차적으로 축소시킵니다.
마지막 Layer까지 Relu 활성화함수를 거쳐왔기 때문에, 0 보다 작은 데이터는 0에 매우 근사하게 위치할 것이고, Input을 -1~1사이의 이미지로 정의했기 때문에 최종값 또한 근사치로 나올 것을 예상 할 수 있습니다.
최종 Layer의 값은 Input 이미지가 진짜라고 판별한다면 1에 가까운 값을, 가짜라고 판별한다면 0에 가까운 값을 출력하도록 학습 할 것입니다.
generator = make_generator_model()
discriminator = make_discriminator_model()정의한 함수를 실행하여 전역 Scope에 존재하는 각각의 변수에 할당합니다.
Loss Function 및 Optimizer 정의
# 이 메서드는 크로스 엔트로피 손실함수 (cross entropy loss)를 계산하기 위해 헬퍼 (helper) 함수를 반환합니다.
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)https://www.tensorflow.org/api_docs/python/tf/keras/losses/BinaryCrossentropy?hl=en
Generator와 Discriminator 모두 loss를 계산 할 때, Discriminator의 출력 값을 기준으로 합니다. 따라서 Discriminator의 출력이 0 또는 1으로 수렴해야하기에, BinaryCrossentropy 를 채택합니다.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)Generator의 목적은 Generator가 생성한 이미지를 Discriminator가 1(진짜이미지)으로 판별하도록하는 것입니다. 따라서 Generator의 Loss는 생성한 이미지를 Discriminator가 판별한 결과를 입력으로 받아서, 그 값이 얼마나 1에서 멀리있는가 를 기준으로 Loss를 결정합니다.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_lossDiscriminator의 목적은 Generator가 생성한 이미지는 0(가짜)으로 판별하고, 진짜 이미지는 1(진짜)으로 판별하는 것입니다. 따라서 Discriminator의 Loss는 두 개의 Loss를 합쳐서 결정됩니다.
- Generator가 생성한 이미지에 대한 판별 값이 얼마나 0에서 멀리있는가
- 실제 이미지에 대한 판별 값이 얼마나 1에서 멀리있는가
위 두 개의 Loss를 각각 계산하고, 합친 값을 Discriminator의 Loss로 반환합니다.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)두 모델 모두 무난하게 좋은 성능을 보이는 Optimizer인 Adam Optimizer를 사용합니다.
훈련 과정 정의
EPOCHS = 300
noise_dim = 100
num_examples_to_generate = 16
# 이 시드를 시간이 지나도 재활용하겠습니다.
# (GIF 애니메이션에서 진전 내용을 시각화하는데 쉽기 때문입니다.)
seed = tf.random.normal([num_examples_to_generate, noise_dim])훈련에 필요한 파라미터를 정의합니다.
EPOCHS
경험적으로 이번 모델에서는 EPOCHS의 값으로 300~500 사이가 적절했습니다.
noise_dim
Generator의 Input으로 사용 될 Latant Vector의 크기는 100으로 정의합니다.
num_examples_to_generator
훈련에 직접적으로 영향을 끼치는 변수는 아닙니다.
훈련과정에서 Generator가 생성하는 이미지를 중간중간에 확인할텐데, 몇 개씩 확인 할지를 정의하는 변수입니다.
seed
훈련에 직접적으로 영향을 끼치는 변수는 아닙니다.
위 num_examples_to_generator의 개수만큼 Latant Vector를 생성하여 Generator에게 생성을 명령합니다.
# `tf.function`이 어떻게 사용되는지 주목해 주세요.
# 이 데코레이터는 함수를 "컴파일"합니다.
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))@tf.function 데코레이터
https://www.tensorflow.org/api_docs/python/tf/function?hl=en#args_1
Tensorflow2.0 공식문서를 확인하면 다음과 같이 설명합니다.
TensorFlow 그래프를 호출 가능한 함수를 컴파일합니다.
Tensorflow1 버전에서 session을 사용하며 컴파일하면서 생기는 여러 문제를 해결하고 간편하게 사용하도록 추가한 기능인데, 위 링크의 예제를 보면 좀 더 이해하기 쉽습니다.
내부적으로 선언되는 Tensorflow Graph를 만들어, Loss 기록, 가중치 기록 및 업데이트 등을 가능하게 합니다.
Tensorflow2에 대한 공부가 따로 더 필요 할 것 같습니다.
train_step 함수 분석
noise = tf.random.normal([BATCH_SIZE, noise_dim])
Generator에 쓰일 noise를 생성합니다. noise의 shape은 (BATCH_SIZE, noise_dim)의 형태로 본 문에서는 (256, 100) 크기의 무작위 값이 됩니다.
tf.GradientTape
https://www.tensorflow.org/api_docs/python/tf/GradientTape
자동 미분을 위한 연산 기록
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_tape, disc_tape에 tf.GradientTape() 자원을 할당합니다.
with 구문 내에서 사용되는 tf.variable 타입의 변수는 자동으로 watch됩니다. (generator, gen_loss, discriminator, disc_loss가 여기에 해당)
with 구문 밖으로 나가면, tf.GradientTape의 일부 자원이 할당 해제되는데, 예측하건데 with 구문 내의 tf 변수를 watch하는 자원이 해제 될 것 같습니다.
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)Generator로 가짜 이미지를 생성하고, Discriminator가 가짜 이미지와 진짜 이미지를 각각 판별합니다. Discriminator의 출력값으로 loss를 계산합니다.
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)gen_tape.gradient(y, x) 함수로 미분 값(기울기)을 구합니다.
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))앞서 구한 기울기를 바탕으로 Generator와 Discriminator의 가중치를 업데이트합니다.
train 함수
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# GIF를 위한 이미지를 바로 생성합니다.
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# print (' 에포크 {} 에서 걸린 시간은 {} 초 입니다'.format(epoch +1, time.time()-start))
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# 마지막 에포크가 끝난 후 생성합니다.
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)dataset, epochs를 인자로 받아 epochs 만큼 훈련을 반복합니다. 각 epoch에서는 세 가지 행동을 반복합니다.
- dataset을 mini batch로 나누어 훈련을 진행하는
train_step함수 - Generator가 생성한 16개의 이미지를 저장하고 셀의 결과로 출력하는 함수
generate_and_save_images - 각 epoch에서 걸린 시간을 기록
def generate_and_save_images(model, epoch, test_input):
# `training`이 False로 맞춰진 것을 주목하세요.
# 이렇게 하면 (배치정규화를 포함하여) 모든 층들이 추론 모드로 실행됩니다.
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()matplot Library를 사용하여 generator가 생성한 16개의 이미지를 병합하고 저장한 후, 셀의 결과로 출력합니다.
훈련
%%time
train(train_dataset, EPOCHS)훈련을 시작합니다. 매 epoch 마다 Generator가 생성하는 예제와 수행 시간을 확인 할 수 있습니다.

GIF 생성
anim_file = 'gan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
last = -1
for i,filename in enumerate(filenames):
frame = 2*(i**0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import IPython
if IPython.version_info > (6,2,0,''):
display.Image(filename=anim_file)imageio Library로 훈련과정에서 생성한 이미지를 연속으로 이어붙여 gif 파일을 생성합니다.

try:
from google.colab import files
except ImportError:
pass
else:
files.download(anim_file)위 코드로 gif파일을 다운로드 할 수 있습니다.
끝
