- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. GPGPU와 GPU프로그래밍, 병렬처리
-
CPU에서만 수행 가능하던 연산들을 GPU에서 수행하는 것이 GPGPU. NVIDIA GPU의 경우 CUDA를 통해 가능하게 되었다.
-
CPU대비 GPU의 초당 최대 처리량 (FLoating point Operations Per Second, FLOPS)가 뛰어나다. 이는 GPU가 CPU에 비해 많은 수의 연산 코어를 가지고 있는 대규모 병렬 처리 장치이기 대문.
-
병렬처리는 하나의 큰 문제를 여러 연산 장치가 나누어 처리한다.
2. 병렬 처리 하드웨어
-
병렬처리 하드웨어에 대해 소개하기 전에, thread란 무엇인지 간단하게 정리하고 넘어가자.
: thread란 병렬처리에서 연산을 수행하는 논리적 주체이다. 운영체제에서 하나의 task를 담당하는 논리적 주체는 프로세스이며, 연산 장치르 활용하는 기본 단위를 thread로 한다. -
플린의 분류법에 의하면 병렬처리 하드웨어는 다음 4가지 프로세서로 구분한다.
-
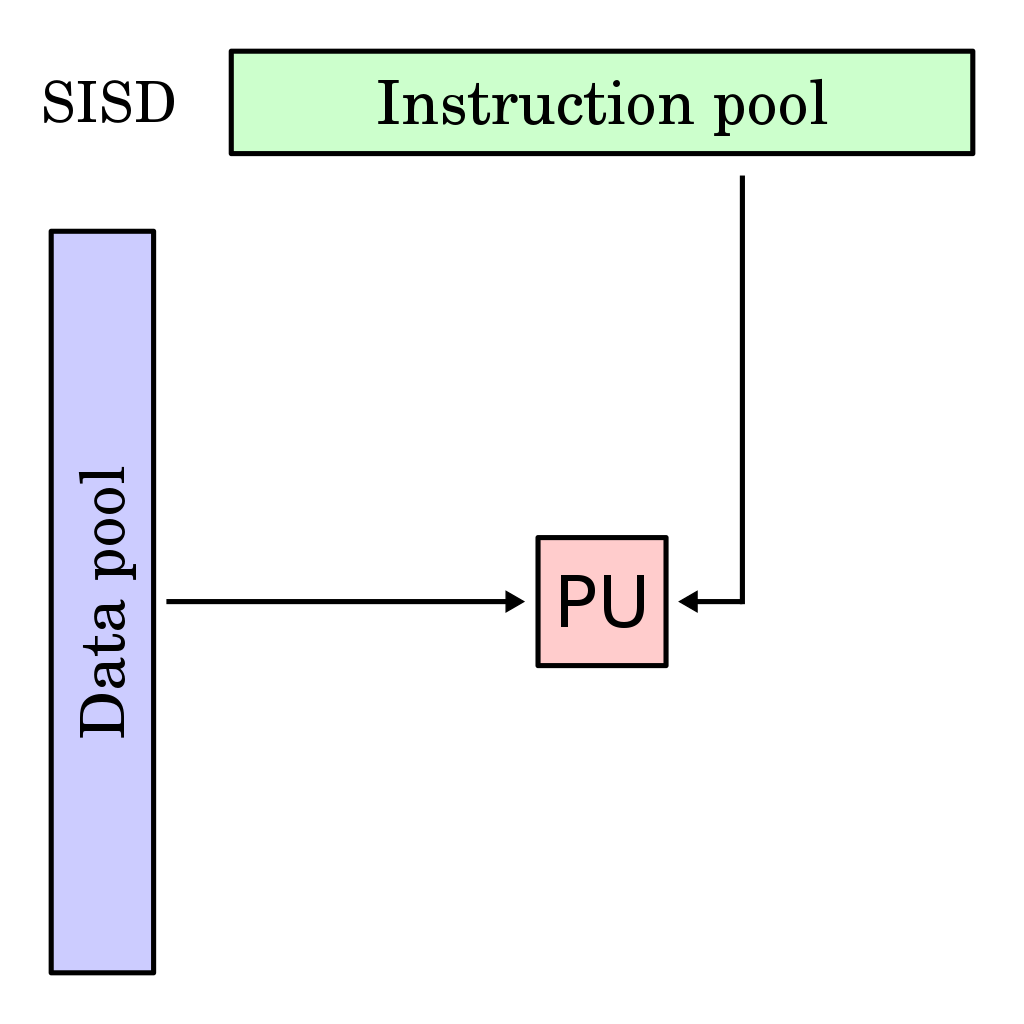
Single Instruction, Single Data (SISD)
: 단일 코어 CPU -
Multiple Instruction, Single Data (MISD)
: 개념적으로만 기술되는, 아직 실현되지 않은 아키텍처 -
Multiple Instruction, Multiple Data (MIMD)
: 여러 명령을 여러 개의 데이터에 적용하지만, 명령어와 데이터는 1대1로 연결, 다수의 SISD가 하나의 칩 안에 들어있는 구조. 즉 여러 독립된 프로세서의 집합.
: 멀티코어 CPU
: 각 프로세서가 자신만의 Control Unit과 Context (process 실행과 관련된 정보들 (register state, memory stack 등)의 집합) 을 가진다.
: task-level parallelism -
Single Instruction Multiple Data (SIMD)
: 하나의 동일한 명령어를 여러 개의 데이터에 대해 수행.
: Vector Processor
: GPU
: SIMD 유닛으로 MMX, SSE, AVX, Neon (CPU) 등이 있음.
: 동일한 제어 명령으로 여러 개의 Core를 제어.
: data-level parallelism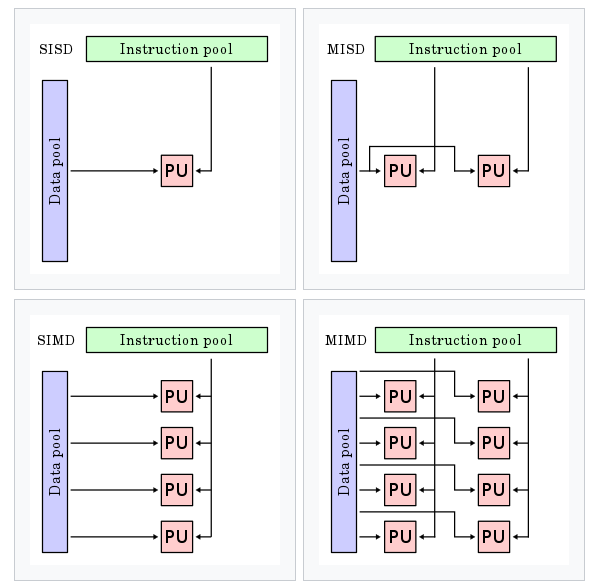
: 각 프로세서를 그림으로 표현한 것. (Wiki)
-
병렬 처리 하드웨어의 또 다른 분류 기준은 메모리 공유 여부이다. shared memory system과 distributed memory system으로 구분한다. GPU는 shared memory system 이다.
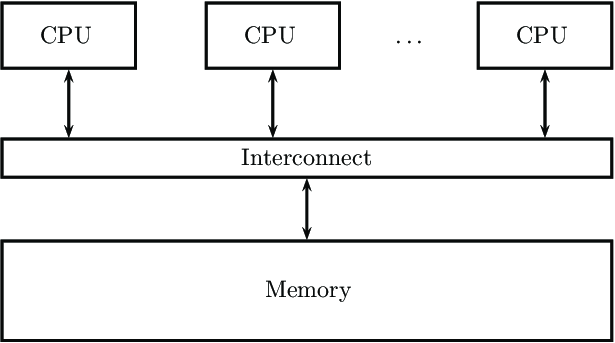
: 위 그림은 Shared memory system을 그림으로 나타낸 것이다.
(출처 https://www.researchgate.net/figure/Shared-memory-systems_fig1_343134734)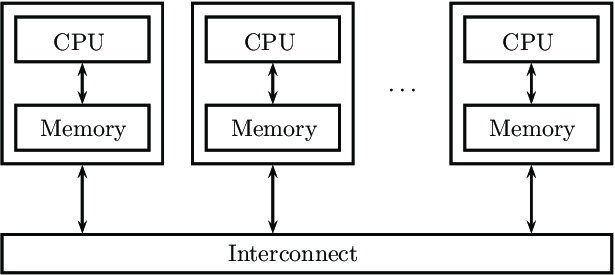
: 위 그림은 Distributed memory system을 그림으로 나타낸 것이다.
(출처 https://www.researchgate.net/figure/Distributed-memory-systems_fig2_343134734)
- 하지만 GPU는 SIMT (Single Instruction Multiple Thread) 구조이다.
: 여러 Thread에 명령을 내리는 구조.
: 특징으로는
1) 한 thread 그룹 내의 스레드들을 하나의 제어 장치로 제어
2) 각 스레드는 자신만의 제어 문맥을 가진다.
3) 그룹 내 스레드들 사이의 분기 (divergent workflow)가 허용된다.
: 해당 내용들은 앞으로 공부하면서 정리할 예정이다.
3. Multicore CPU vs. GPU
-
Multicore CPU
: 단일 코어의 성능은 GPU에 비해 월등히 높지만, Core의 수 자체는 GPU보다 적다.
: 제어장치 및 Cache에 많은 공간을 할당. -> 불규칙한 흐름을 가지는 연산에 대해 GPU에 비해 높은 성능을 보인다. -
GPU
: 메모리에 대한 접근 형태가 규칙적 -> 캐시에 상대적으로 작은 공간 할당.
: 한번에 많은 데이터에 접근 -> 높은 대역폭 갖는 DDR6, HBM 같은 고성능 메모리 사용.
