- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. CUDA란
-
Compute Unified Dvice Architecture
: NVIDIA에서 GPU를 GPGPU를 목적으로 사용할 수 있게 제공하는 프로그래밍 인터페이스.
: C/C++의 확장.
: Python에서도 CUDA로 작성된 모듈을 호출해서 사용할 수 있지만, GPU를 직접 제어하려면 CUDA C/C++로 코드 작성해야함
: 다른 회사의 GPU를 GPGPU로 사용할려면 OpenCL 같은 개방형 API 사용해야한다.
: Driver API와 Runtime API라는 두 가지의 API를 지원한다. -
Driver API
: Context 및 Module 로드 등에 대해 더 세밀한 제어 기능을 제공. (저수준)
: CUDA kernel (GPU 사용을 시작하는 함수. 뒤에 설명) 실행을 위한 구현 방법이 복잡하다.
: 해당 커널이 필요할 때만 동적으로 로드해서 사용가능 -> 메모리 등의 자원을 더 효율적으로 사용.
: 언어 비종속적 -> 다양한 언어에서 해당 모듈 사용 가능. -
Runtime API
: CUDA kernel 구현에 대한 설정을 자동으로 해준다.
: Kernel이 프로그램 시작과 함꼐 초기화 및 로드되고, 프로그램이 종료될 때 까지 유지. -
GPU의 성능
: 중요한 지표는 CUDA 코어의 수와 메모리 크기 및 대역폭.
: # of CUDA Core 해당 GPU가 가진 연산 코의의 수.
: 대역폭은 CUDA 코어들에게 한 번에 공급할 수 있는 데이터의 양이 많다는 의미. -
CUDA compute capability
: GPU가 제공하는 기능과 구성을 보여주는 지침
2. CUDA 개발 환경설정
- 책과는 다르게 Colab을 사용한다.
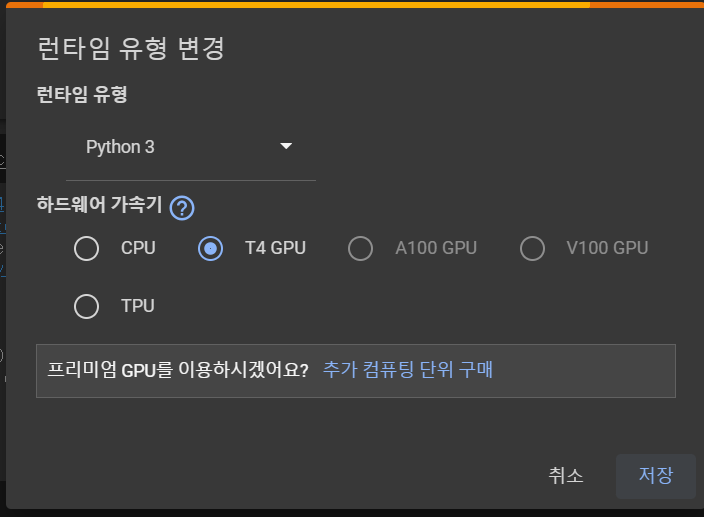
1. 새 Colab 파일을 만들면, 런타임을 변경한다. 런타임 -> 런타임 유형 변경 -> 하드웨어 가속기 : T4 GPU로 변경.
2. NVCC 플러그인 설치
: Colab에는 CUDA가 이미 설치되어 있다. 버전확인은 다음 코드로 확인 가능하다.
!nvcc --version
: 플러그인 설치는 다음 코드를 작성 후 실행시키면 된다.
!pip install git+https://github.com/andreinechaev/nvcc4jupyter.git
: 플러그인 설치 후 다음 코드를 작성 후 실행시켜서 플러그인을 로드한다.
%load_ext nvcc_plugin
: 이후 코드를 작성하면 되는데, 코드 작성 시 주의사항은 CUDA를 사용하기 위해서는 코드 맨 위에 %%cu를 작성해줘야 한다.
3. Hello CUDA
-
간단한 CUDA 프로그램인 Hello CUDA를 작성해 볼 것이다. 그 전에, Host / Device의 개념을 정리하고 가자.
-
Host
: About CPU
: GPU에서 실행되는 최초 모듈은 CPU에 의해 호출된다. 따라서 Host라는 이름이 붙었다.
: Host Code는 CPU에서 실행되는 코드. gcc 또는 Visual Studio 컴파일러 등 C언어 컴파일러로 컴파일.
: Host Memory는 CPU가 사용하는 시스템 메모리 -
Device
: About GPU
: Device Code는 GPU에서 실행되는 코드. nvcc 컴파일러로 컴파일.
: GPU에서 실행되는 최초의 Device Code (Kernel)은 Host Code에서 호출되어야 한다. -
Hello CUDA 프로그램
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void helloCUDA(void)
{
printf("Hello CUDA from GPU!\n");
}
int main(void)
{
printf("Hello GPU from CPU!\n");
helloCUDA <<<1,10>>>();
cudaDeviceSynchronize(); // stream 동기화
return 0;
}: 코드를 자세히 살펴보자.
-
헤더 파일
: 다음은cuda_runtime.h에 대한 설명이다.cuda.h defines the public host functions and types for the CUDA driver API.
cuda_runtime_api.h defines the public host functions and types for the CUDA runtime API
cuda_runtime.h defines everything cuda_runtime_api.h does, as well as built-in type definitions and function overlays for the CUDA language extensions and device intrinsic functions.
: 즉,
cuda_runtime.h는 Runtime API에 대한 헤더파일.:
device_launch_parameters.h는 Kernel Function에서 자기 Blockidx, BlockDim, thredidx를 구할 때 필요하다. (나중에 설명) -
CUDA C/C++ 키워드
: C/C++ 확장을 위한 keyword.1) 함수 실행 공간 지정 키워드
(1)
__host__: 호출 host -> 실행 host (default)
(2)__device__: 호출 device -> 실행 device
(3)__global__: 호출 host -> 실행 device (이렇게 지정된 함수를 kernel이라고 함)2) 실행구성 문법 (execution configuration)
:<<<>>>
: 커널을 수행할 CUDA thread 수를<<<>>>를 통해서 지정한다. 코드에서helloCUDA<<<1, 10>>>()는 10개의 CUDA thread가helloCUDA()kernel을 수행하라는 의미
cudaDeviceSynchronize(): 계산된 값을 CPU와 synchronize하여 작동. 즉, stream 동기화
- 프로그램 실행
: 프로그램 실행 결과는 다음과 같다.
:Hello GPU from CPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU!helloCUDA()kernel은 한 번 호출되었는데, 10개의 thread가helloCUDA()kernel을 실행했기 때문에 Hello CUDA from GPU! 가 10번 출력되었다.
