CUDA Programming Study
1.CUDA 프로그래밍 Study Ch 1. GPGPU 개요
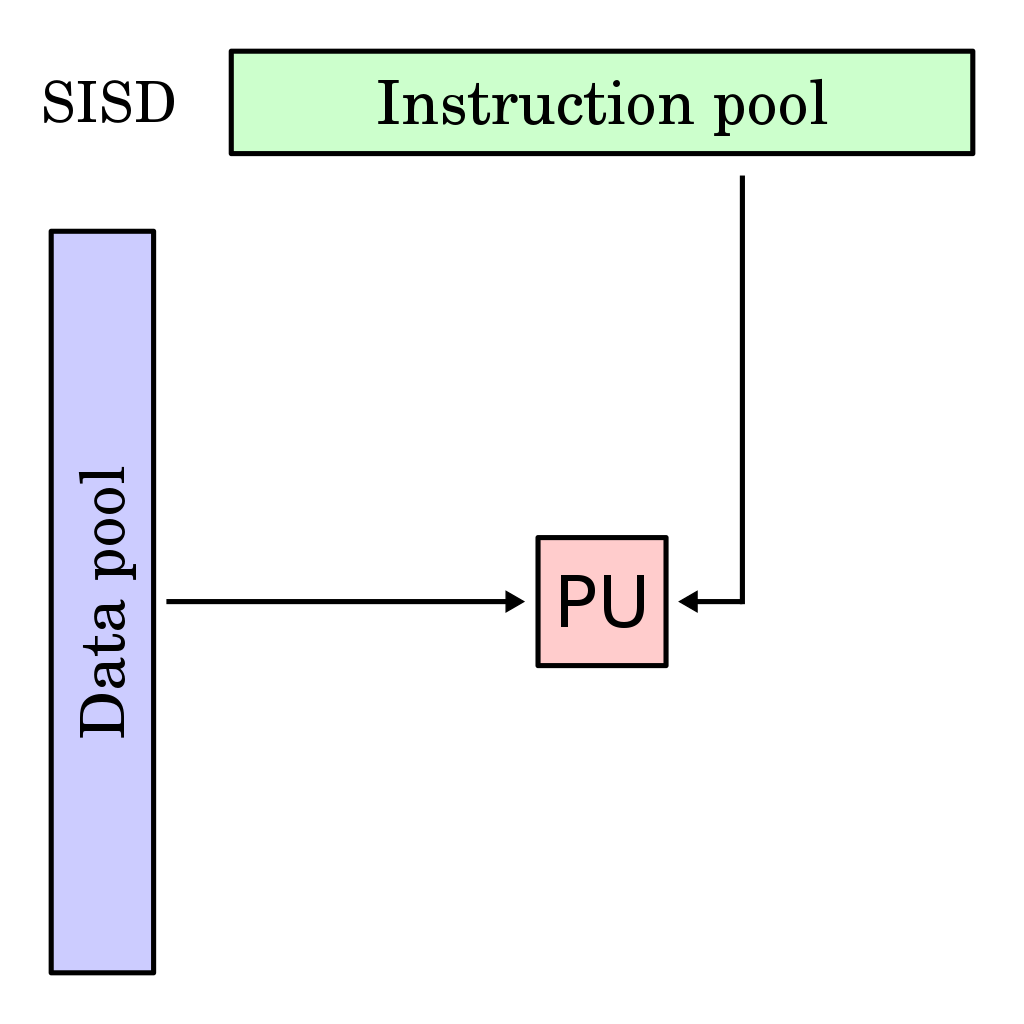
들어가기에 앞서: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다. CPU에서만 수행 가능하던 연산들을 GPU에서 수행하는 것이 GPGPU. NVIDIA GPU의 경우
2.CUDA 프로그래밍 Study Ch 2. CUDA 개요
들어가기에 앞서: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.Compute Unified Dvice Architecture : NVIDIA에서 GPU를 GPGPU
3.CUDA 프로그래밍 Study Ch 3. CUDA 프로그램의 기본 흐름

CPU가 운영체제와 같은 컴퓨터 시스템의 기본 연산 장치이며, GPU등 다른 연산 장치를 사용하기 위해서는 호스트 코드에서 커널을 호출해야함.CPU와 GPU는 서로 독립된 장치: 사용하는 메모리 영역도 다르다.모든 데이터는 기본적으로 호스트 메모리에 저장: GPU를 이
4.CUDA 프로그래밍 Study Ch 4. CUDA 스레드 계층
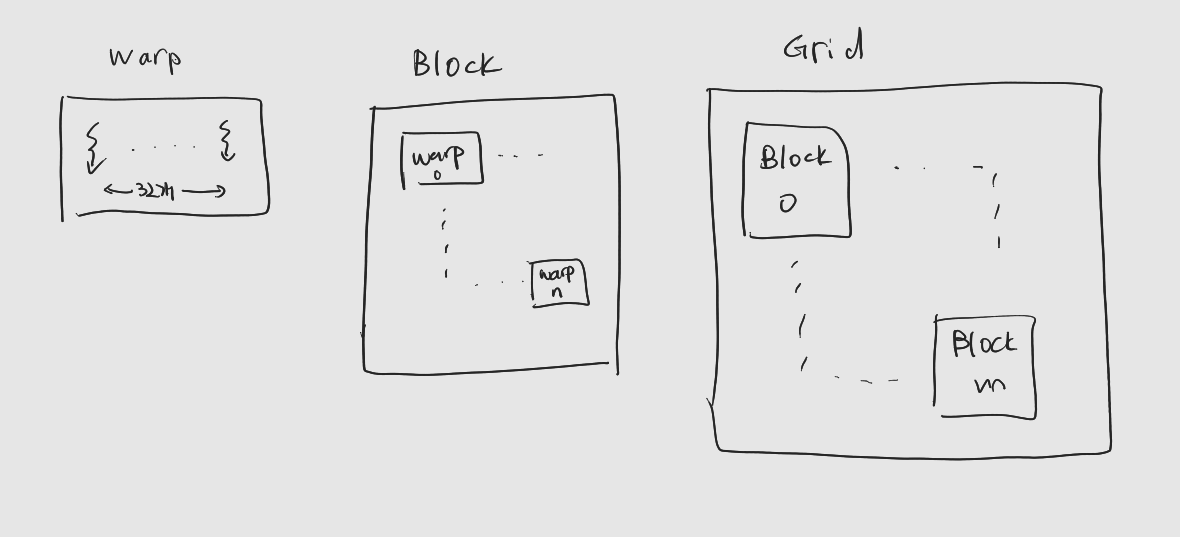
들어가기에 앞서: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.CUDA에서 연산을 수행하거나 CUDA 코어를 사용하는 기본 단위. : 커널 코드는 모든 스레드에 공
5.CUDA 프로그래밍 Study Ch 5. 스레드 레이아웃과 인덱싱
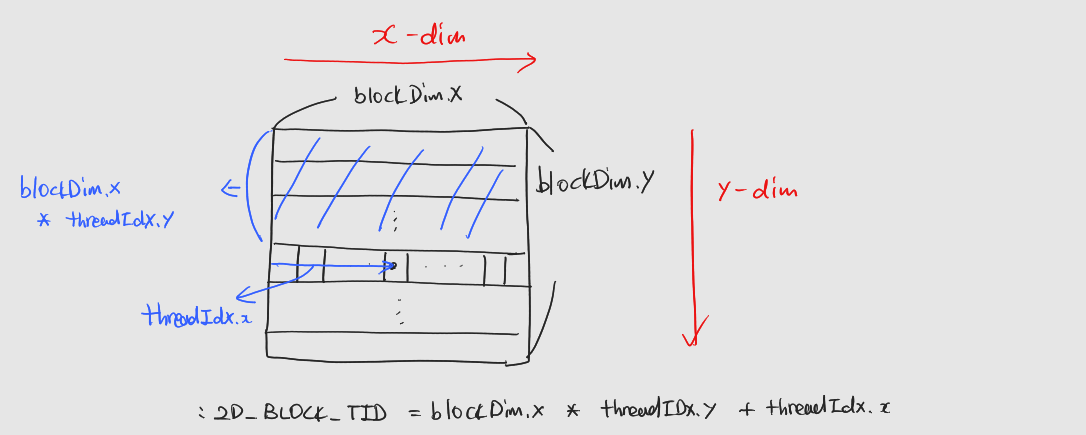
들어가기에 앞서 : 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다. 1. 1024보다 큰 벡터의 합 구하기 1.1 스레드 레이아웃 결정 블록의 크기 결정 과정
6.CUDA 프로그래밍 Study Ch 6. CUDA 실행 모델
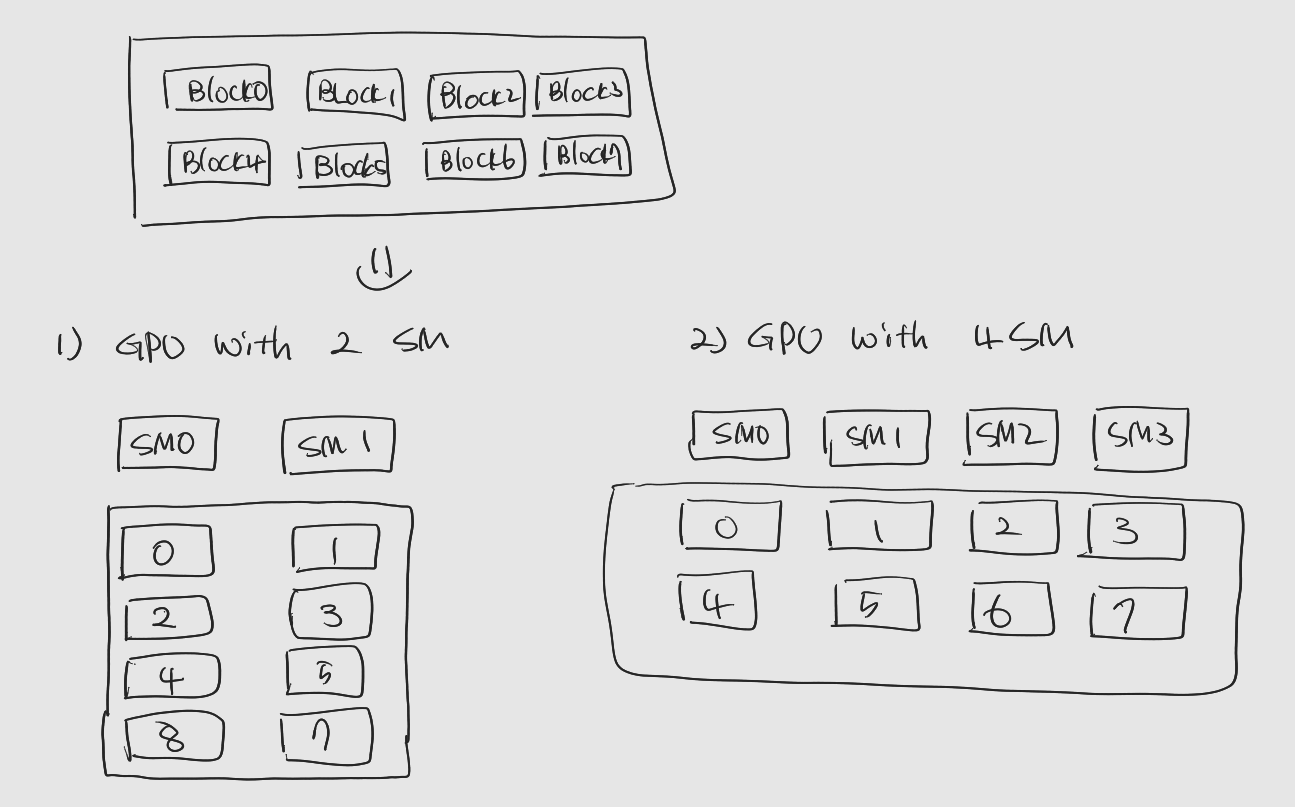
1. NVIDIA GPU Architecture 2010년 발표한 Fermi Architecture 부터, 2020년에 발표한 Ampere Architecture, 2022년 발표된 Hopper (데이터센터 전용 GPU Microarchitecture), Ada Lo
7.CUDA 프로그래밍 Study Ch 7. CUDA 기반 행렬 곱셈 프로그램
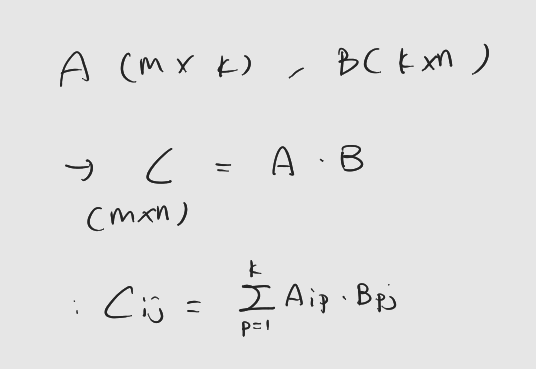
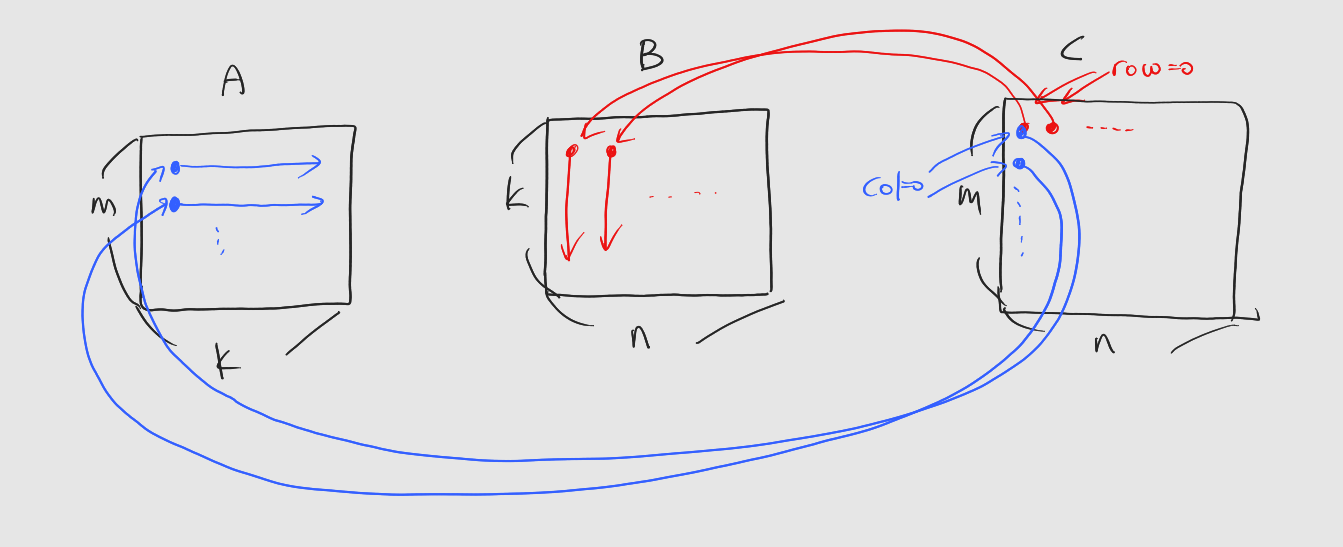
들어가기에 앞서: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.학부과정에서, 혹은 독학으로 선형대수학을 배우다 보면 행렬곱을 하는 방법을 알려준다. 자료구조와 알고
8.CUDA 프로그래밍 Study Ch 8. CUDA 메모리 계층
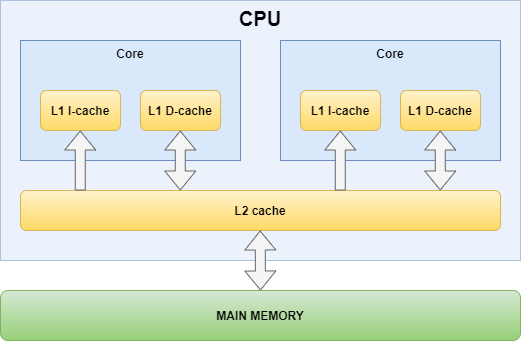
들어가기에 앞서: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
9.CUDA 프로그래밍 Study Ch 9. CUDA 공유 메모리
들어가기에 앞서: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.블록 내 스레드들이 공유하는 데이터 보관: 공유 메모리에 공간 만들고, 여러 스레드들이 해당 공간에
10.CUDA 프로그래밍 Study Ch 10. CUDA 공유 메모리를 활용한 행렬 곱셈 프로그램
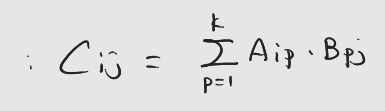
들어가기에 앞서: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다. : 입력 행렬의 데이터 크기가 공유 메모리보다 큰 경우에 어떤 식으로 최적화를 진행할 지를 학습한다
11.CUDA 프로그래밍 Study Ch 11. 메모리 접근 성능 최적화
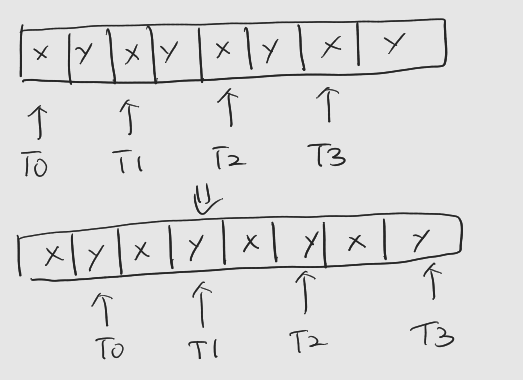
들어가기에 앞서 : 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다. 1. 전역 메모리 접근 최적화 전역 메모리에 대한 접근은 L2 및 L1 캐시 (사용시)을 통해
12.CUDA 프로그래밍 Study Ch 12. 동기화 및 동시 실행
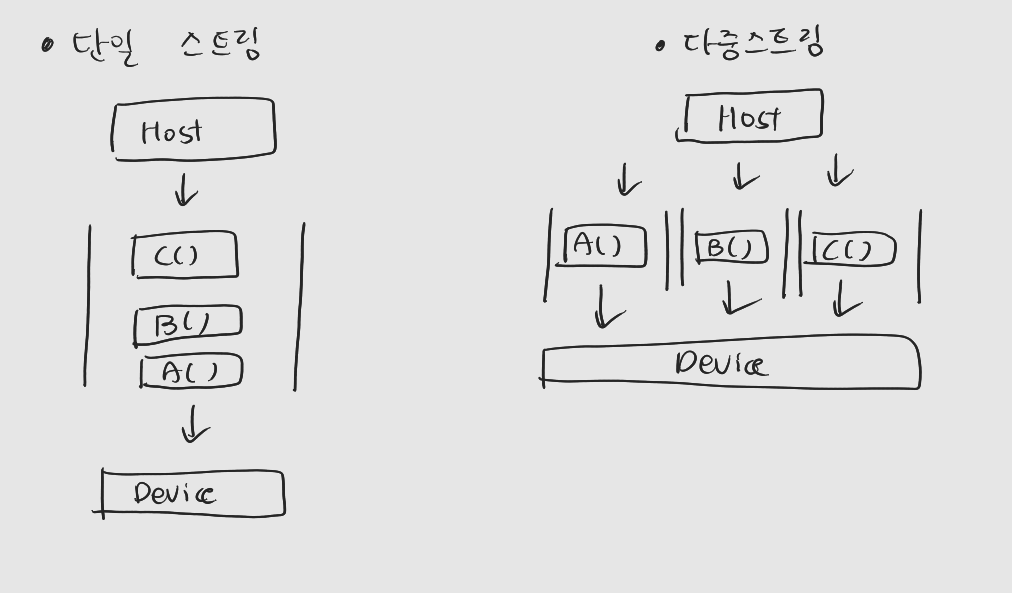
들어가기에 앞서 : 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다. 1. 동기화 동기화란 무엇인가. : 둘 이상의 연산 주체가 서로 정보를 교환(특정 정보를