- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. 동기화
-
동기화란 무엇인가.
: 둘 이상의 연산 주체가 서로 정보를 교환(특정 정보를 공유하거나 서로 실행 순서를 맞추는 것) 하는 행위.
: 연산 주체 여러 개가 동시에 동일 데이터에 접근시, 약속 없이 데이터를 접근하거나 수정한다면, 잘못된 데이터가 생성, 프로그램이 오작동. -
동기화 기법
- 장벽(barrier)
: 모든 스레드가 모여야만 열리는 일종의 차단기
: 먼저 도착한 스레드들은 모든 스레드가 도착할 때까지 대기. - 상호 배제
: 특정 영역의 작업을 한 번에 하나의 스레드만 수행.
1.1 CUDA의 동기화
1.1.1 동기화 함수
: 장벽 역할을 수행.
- 블록 수준 동기화 함수 :
__synchtreads()
: 블록 내 모든 스레드가 도착할 때까지 대기.
: 예제 코드
__global__ void MatMul_SharedMem(DATA_TYPE* matA, DATA_TYPE* matB, int* matC, int m, int n, int k)
{
int row = blockDim.x * blockIdx.x + threadIdx.x;
int col = blockDim.y * blockIdx.y + threadIdx.y;
int val = 0;
__shared__ int subA[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int subB[BLOCK_SIZE][BLOCK_SIZE];
int localRow = threadIdx.x;
int localCol = threadIdx.y;
for (int bID = 0; bID < ceil((float)k / BLOCK_SIZE); bID++) {
int offset = bID * BLOCK_SIZE;
// load A and B
if (row >= m || offset + localCol >= k)
subA[localRow][localCol] = 0;
else
subA[localRow][localCol] = matA[row * k + (offset + localCol)];
if (col >= n || offset + localRow >= k)
subB[localRow][localCol] = 0;
else
subB[localRow][localCol] = matB[(offset + localRow) * n + col];
__syncthreads();
// compute
for (int i = 0; i < BLOCK_SIZE; i++) {
val += subA[localRow][i] * subB[i][localCol];
}
__syncthreads();
}
if (row >= m || col >= n)
return;
matC[row * n + col] = val;
}- 워프 수준 동기화 함수 :
__syncwarp()
: 워프 내 스레드들 사이의 장벽 역할을 하는 동기화 함수
: 동일 워프 내 모든 스레드가 도착할 때까지 대기.
: 예시 코드
: 코드에서, 워프 내 특정 스레드 하나만 어떤 작업을 완료한 후에, 워프가 다음 단계로 진행.
:__syncwarp()대신__syncthreads()를 사용해도 결과는 동일하지만, 동기화 범위를 블록 내 전체 스레드에서 워프 내 스레드로 줄임으로써, 동기화에 따른 병렬성 저하 정도를 낮추는 효과 기대.
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#define BLOCK_SIZE 64
__global__ void syncWarp_test()
{
int tID = threadIdx.x; // 0~63
int warpID = (int)(tID / 32);
// 0~31번 thread : 0
// 32~64번 thread : 1
__shared__ int masterID[BLOCK_SIZE/32];
if (threadIdx.x % 32 == 0) {
masterID[warpID] = tID;
// 0번 thread, 32번 thread : master
}
__syncwarp(); // intra-warp synchronization (barrier)
printf("[t%d] The master of our warp is t%d\n", tID, masterID[warpID]);
}
int main()
{
syncWarp_test <<<1, BLOCK_SIZE >>>();
} - 그리드 (커널) 수준 동기화 : 커널 분리
: 그리드 내 모든 스레드의 동기화 또는 블록들 사이 동기화 함수는 따로 제공되지 않는다.
: 대신 커널 호출 및 종료 시점에서 그리드 내 모든 스레드 사이에 암묵적인 동기화 수행.
: 따라서 그리드(커널) 내 모든 스레드를 동기화 하는 대표적인 방법은 커널을 분리하는 것.
: 예시 코드
// 커널 분리를 하지 않은 경우
void kernel (int *a, ...)
{
// step A
// 전체 스레드 동기화 지점
// step B
}
void main()
{
kernel<<<...>>> (...)
}
// 커널 분리를 한 경우
void kernelA(int *a, ...)
{
// step A
}
void kernelB(int *a, ...)
{
// step B
}
void main()
{
kernelA <<<...>>>(...)
kernelB <<<...>>>(...)
]1.1.2 원자 함수
-
데이터 접근에 대한 상호 배제 역할
: 컴퓨터 시스템에서 원자 함수 (atomic operation)이란 분할되지 않는 하나의 동작으로 수행되는 연산.
: 다른 프로세스나 스레드가 해당 연산이 수행되는 동안 개입할 수 없음
: 즉 한 번에 하나의 스레드만 해당 데이터에 접근할 수 있도록 보장 -
CUDA는 데이터에 대한 접근 및 수정을 위한 원자 함수 제공.
: 여러 스레드가 동일 데이터에 원자함수로 접근하고자 하는 경우, 현재 데이터를 사용중인 스레드 외 다른 스레드들은 대기.
: 해당 스레드가 속한 워프의 작업이 직렬화 -> 병목 -
32bit 및 64bit 데이터에 대해 read-modify-write (특정 위치의 데이터를 읽고 그 데이터를 수정한 후 원래 위치에 값을 쓰는 것을 의미) 을 한 번의 연산으로 수행.
-
전역 메모리에 있는 데이터에 적용
: 인자로 주는 변수에 따라 맞추어 동작 수행 -
예제 : 원자 함수를 이용한 스레드 수 계산
: 동기화가 없이 스레드 수 계산 시, 모든 스레드가 전역 메모리에 있는 변수 a에 어떠한 통제도 없이 동시에 접근해서 값을 바꾸기 때문에 실행 결과는 실제 스레드 수와 차이가 있다.
// 원자 함수 사용하지 않을 시
__global__ void threadCounting_noSync(int *a) {
(a*)++;
}
// 원자 함수 사용시
__global__ void threadCounting_atomicGlobal(int *a) {
atomicAdd(a, 1); // (*a) <- (*a) + 1
}- 동기화에 따른 성능 저하 완화
:threadCounting_atomicGlobal커널의 경우, 전역 메모리에 있는 변수에 대해 원자 함수를 적용
: 즉 동기화의 범위가 그리드 내 모든 스레드
: 공유 메모리에 있는 변수를 사용한다면 동기화 범위를 블록 내 스레드로 축소 가능
: 예제 코드
__global__ void threadCounting_atomicShared(int* a)
{
__shared__ int sa;
// 블록 내 스레드 수를 계산하기 위한 공유 메모리 변수
if (threadIdx.x == 0)
sa = 0;
__syncthreads();
// 블록 내 첫번째 스레드가 sa를 0으로 초기화
atomicAdd(&sa, 1);
__syncthreads();
// 공유 메모리 변수 sa를 대상으로 원자함수 수행
// 동기화 범위는 각 블록 내부로 제한.
if (threadIdx.x == 0)
atomicAdd(a, sa);
// 각 블록 내부 계산 결과를 하나로 취합.
// 각 블록에서 하나의 스레드가 전역 변수 a에 계산된 값을 더해주면 된다.
// if문 통해 각 블록의 대표 스레드만 취합 작업에 참여.
}1.1.3 수동 제어 (manual control)
-
사용자가 직접 로직을 설계해서 수동으로 제어
: 스레드 번호, 원자 함수, 동기화 함수를 이용 -
예제
: 짝수 스레드와 홀수 스레드가 서로 다른 작업을 수행
: 짝수 스레드들은 다른 모든 짝수 스레드가 작업을 완료할 때까지 대기
: 짝수 스레드드르 사이에만 동기화 ->__syncthreads()와 같은 동기화 함수 사용 x
: 특정 데이터에 대한 접근 동기화가 아닌 작업단위 동기화이므로 원자함수로 문제 해결 불가능.
: 코드
__ global __ void myKernel (int *input, int *output)
{
__shared__ int lock;
if (threadIdx.x % 2 == 0) // 짝수 / 홀수 스레드 작업 구분
{
// work for even threads
atomicInc(&lock);
// 각 짝수 스레드는 자신의 작업을 완료 후, lock +1
// 여러 스레드가 동시에 lock변수에 접근하는 것을 방지하기 위해 원자함수 사용
while (lock < blockDim.x / 2);
// spin lock 방식
// lock = blockDim.x 일 때까지 기다림.
}
else
{
// work for odd threads
}
// common work for all threads
__syncthreads();
// next step
}1.1.4 동기화 사용 시 주의점
- 동기화는 병렬 처리 프로그램이 정상적으로 동작하도록 제어하기 위한 필수요소이지만, 주요 병목지점이기도.
: 따라서 불필요한 동기화 시용 자제
: 동기화 최소화하는 알고리즘 설계
: 동기화 범위를 최소화
2. CUDA 스트림과 동시 실행
2.1 CUDA 스트림의 정의 및 특성
-
CUDA 스트림은 호스트에서 디바이스로 명령을 보내는 통로.
-
NULL Stream
: default stream
: 사용자가 스트림을 명시하지 않았을 경우, 묵시적으로 선언된 스트림
: 디바이스 당 하나 -
Non-NULL Stream
: 사용자가 명시적으로 생성 및 사용하는 스트림
: 사용자의 필요에 따라 여러 개 생성 -
하나의 스트림을 통해 전달하는 명령들은 순서대로 스트림에 쌓이며, 순차적으로 수행
-
서로 다른 Non-NULL
: 어느 것이 디바이스에 의해 먼저 처리될 지 알 수 없다. (서로 다른 스트림 사이의 실행 순서는 비결정적)
: 둘 이상의 스트림에 있는 명령이 동시에 처리될 수도 있다 (비동기적)
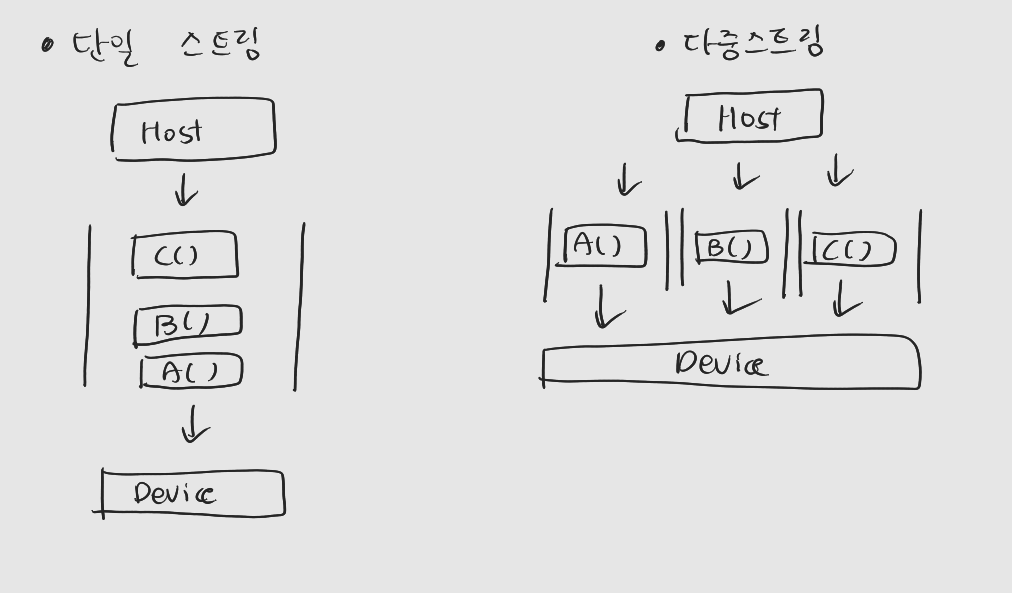
2.1.1 Non-NULL Stream 생성 및 제거
// 생성
cudaError_T cudaStreamCreate(cudaStream_t*)
//제거
cudaError_t cudaStreamDestroy(cudaStrea_t)2.1.2 커널 호출 시 스트림 지정하기
- 커널 호출 시 커널 실행 명령을 전달할 스트림을 실행구성 (<<< >>>)의 네 번째 인자로 전달
: 마지막 인자가 아닌 네번째 인자
: 중간에 사용하지 않는 인자가 있다면 0으로 명시
// 예시
cudaStream_t stream;
cudaStreamCreate(&stream);
myKernel<<<dimGrid, dimBlock, 0, stream>>>(...)
cudaStreamDestroy(stream);2.2 CUDA 명령어의 동시 실행
-
CUDA 프로그램의 흐름 (NULL-Stream)
: HostToDevice(H2D) 데이터 복사 -> 디바이스에서 커널 수행 -> DeviceToHost(D2H) 결과 복사
: NULL-Stream에서 동기적으로 실행 -
비동기적으로 실행 가능한 CUDA 명령들
: 호스트 연산과 디바이스 연산
: 호스트 연산과 H-D 데이터 통신
: 디바이스 연산과 H-D 데이터 통신
: H2D 데이터 복사와 D2H 데이터 복사(디바이스에 따라 다름)
: 서로 다른 디바이스들의 연산
: 요약하면 연산 작업들과 H-D 사이의 데이터 통신은 비동기저으로 실행 가능.
: 같은 스트림에 있는 명령들은 Non-NULL stream의 경우도 순차적으로 처리. -
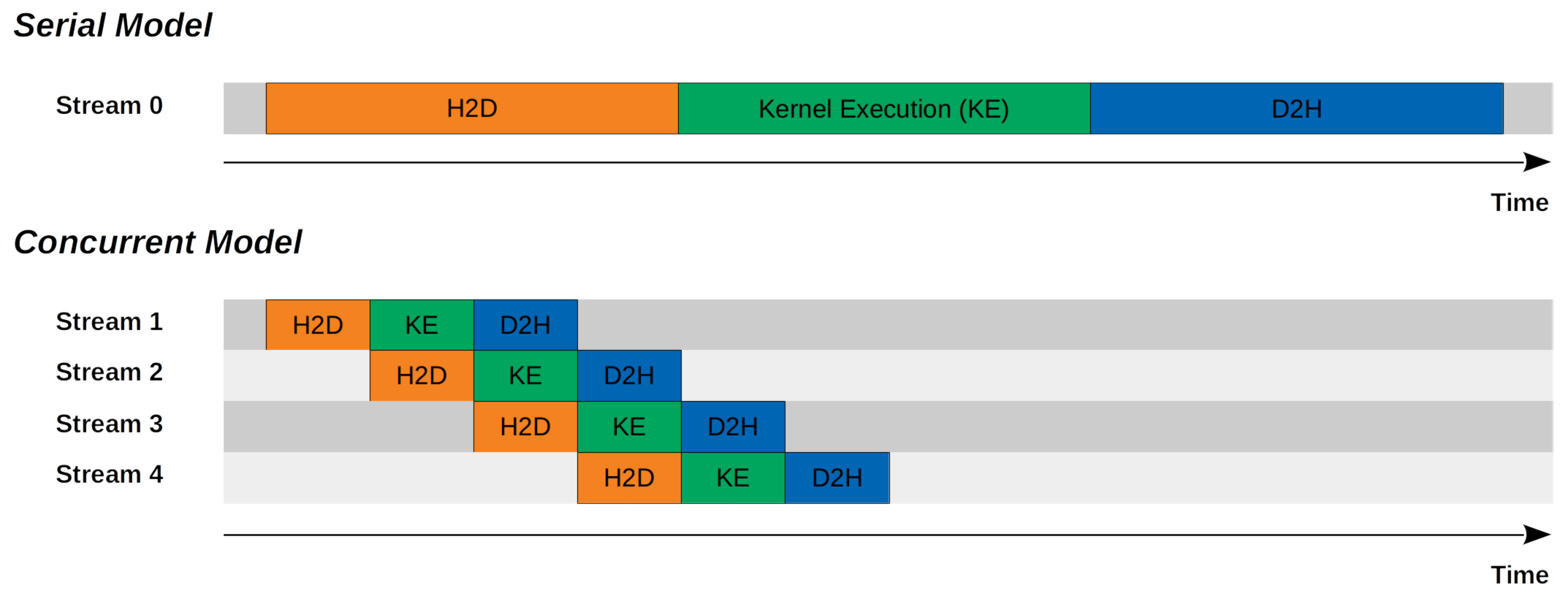
동기적 실행의 비효율성
: 데이터 복사 시간 동안 H와 D는 유휴상태
: 커널 수행 시간동안 데이터 전송 통로인 PCI버스는 유휴 상태 -
다중 스트림 사용 전략
: 데이터 전송과 디바이스 연산을 중첩
: 처리할 데이터들이 서로 독립적인 경우, 일부 데이터가 준비되면 전체 데이터 복사를 기다리지 않고 바로 연산 시작 -
단일 스트림과 다중 스트림 비교
- 커널 실행과 데이터 통신의 중첩은 여러 개의 Non-NULL 스트림 사용, 중첩할 작업들을 서로 다른 스트림에 넣어주는 방법으로 구현
: 스트림에 들어 있는 명령 중 동기적으로 실행되는 명령이 있다면 ㅎ당 명령을 수행하는 동안에는 다른 명령이 종료될 때까지 대기
: 대표적으로cudaMemcpy()
: 데이터 중첩 전략을 사용하기 위해서는 비동기적 데이터복사 API를 사용
2.2.1 비동기적 메모리 복사와 핀드 메모리
// 비동기적 메모리 복사를 위한 CUDA API
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t size,
enum cudaMemcpyKind, cudaStream_t stream = 0)
// 마지막 인자로 명령을 전달할 스트림 지정
// 해당 인자를 주지 않으면 defaul : NULL스트림 사용* Async라는 접미어가 붙는 함수는 비동기적으로 동작한다는 의미를 갖고있다.
-
비동기적 데이터 복사를 위한 조건
: Host Memory가 pinned memory여야 한다 -
핀드 메모리
: CPU의 메모리 - 보조기억장치 Caching 방법인 Virtual Memory에서 페이지 교체가 되지 않고, 물리 메모리에 상주하는 메모리
: 비동기적 실행의 경우, 데이터 복사 명령을 내린 후 호스트가 바로 다음 호스트 코드로 진행 -> 호스트 입장에서는 대상 메모리 영역의 사용이 끝난 것으로 판단 -> 비동기적 데이터 통신이 진행되는 동안에도 대상 호스트 메모리 영역이 운영체제에 의해 가상 메모리로 내려질 수 있다.
:cudaMemcpyAsync()도 호스트 메모리가 핀드 메모리가 아니라면 데이터 통신은 동기적으로 동작.
2.2.2 핀드 메모리 할당 및 해제
cudaError_t cudaMallocHost (void ** ptr, size_t size)
cudaError_t cudaFreeHost (void* ptr)2.3 데이터 전송 부하 숨기기 예제코드
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "DS_timer.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define NUM_BLOCK (128*1024)
#define ARRAY_SIZE (1024*NUM_BLOCK)
#define NUM_STREAMS 4
#define WORK_LOAD 256
__global__ void myKernel(int* _in, int* _out)
{
int tID = blockDim.x * blockIdx.x + threadIdx.x;
int temp = 0;
int in = _in[tID];
for (int i = 0; i < WORK_LOAD; i++) {
temp = (temp + in * 5) % 10;
}
_out[tID] = temp;
}
// 특별한 의미 없는 커널
void main(void)
{
int* in = NULL, * out = NULL, * out2 = NULL;
// 호스트 핀드 메모리 할당, 초기화
cudaMallocHost(&in, sizeof(int) * ARRAY_SIZE);
memset(in, 0, sizeof(int) * ARRAY_SIZE);
cudaMallocHost(&out, sizeof(int) * ARRAY_SIZE);
memset(out, 0, sizeof(int) * ARRAY_SIZE);
cudaMallocHost(&out2, sizeof(int) * ARRAY_SIZE);
memset(out2, 0, sizeof(int) * ARRAY_SIZE);
// 디바이스 메모리 할당
int* dIn, * dOut;
cudaMalloc(&dIn, sizeof(int) * ARRAY_SIZE);
cudaMalloc(&dOut, sizeof(int) * ARRAY_SIZE);
for (int i = 0; i < ARRAY_SIZE; i++)
in[i] = rand() % 10;
// Single stram version
cudaMemcpy(dIn, in, sizeof(int) * ARRAY_SIZE, cudaMemcpyHostToDevice);
myKernel <<<NUM_BLOCK, 1024>>> (dIn, dOut);
cudaDeviceSynchronize();
cudaMemcpy(out, dOut, sizeof(int) * ARRAY_SIZE, cudaMemcpyDeviceToHost);
// Multiple stream version
// Non-NULL stream 생성
cudaStream_t stream[NUM_STREAMS];
for (int i = 0; i < NUM_STREAMS; i++)
cudaStreamCreate(&stream[i]);
// 데이터 분할
int chunkSize = ARRAY_SIZE / NUM_STREAMS;
// H2D 복사, 복사 시작 위치는 offset으로 조절
for (int i = 0; i < NUM_STREAMS; i++)
{
int offset = chunkSize * i;
cudaMemcpyAsync(dIn + offset, in + offset, sizeof(int) * chunkSize, cudaMemcpyHostToDevice, stream[i]);
}
// 커널 실행
// 스레드 레이아웃 : 처리할 데이터가 변하면 스레드 레이아웃도 바뀌어 줘야함
for (int i = 0; i < NUM_STREAMS; i++)
{
int offset = chunkSize * i;
myKernel << <NUM_BLOCK / NUM_STREAMS, 1024, 0, stream[i] >> > (dIn + offset, dOut + offset);
}
// D2H 복사
for (int i = 0; i < NUM_STREAMS; i++)
{
int offset = chunkSize * i;
cudaMemcpyAsync(out2 + offset, dOut + offset, sizeof(int) * chunkSize, cudaMemcpyDeviceToHost, stream[i]);
}
cudaDeviceSynchronize();
for (int i = 0; i < ARRAY_SIZE; i++)
{
if (out[i] != out2[i])
printf("!");
}
for (int i = 0; i < NUM_STREAMS; i++)
cudaStreamDestroy(stream[i]);
cudaFree(dIn);
cudaFree(dOut);
cudaFreeHost(in);
cudaFreeHost(out);
cudaFreeHost(out2);
}- 너무 많은 스트림 사용시
: 스트림 관리 시 부하가 커질 수 있다
: 적절한 스트림은 네 개 정도
: 데이터 조각을 더 잘게 잘라서 더 많은 연산과 데이터 통신 중첩을 유도하고 싶다면, 정해진 수의 데스트림을 사용하면서 데이터 조각을 번갈아 할당하는 것.
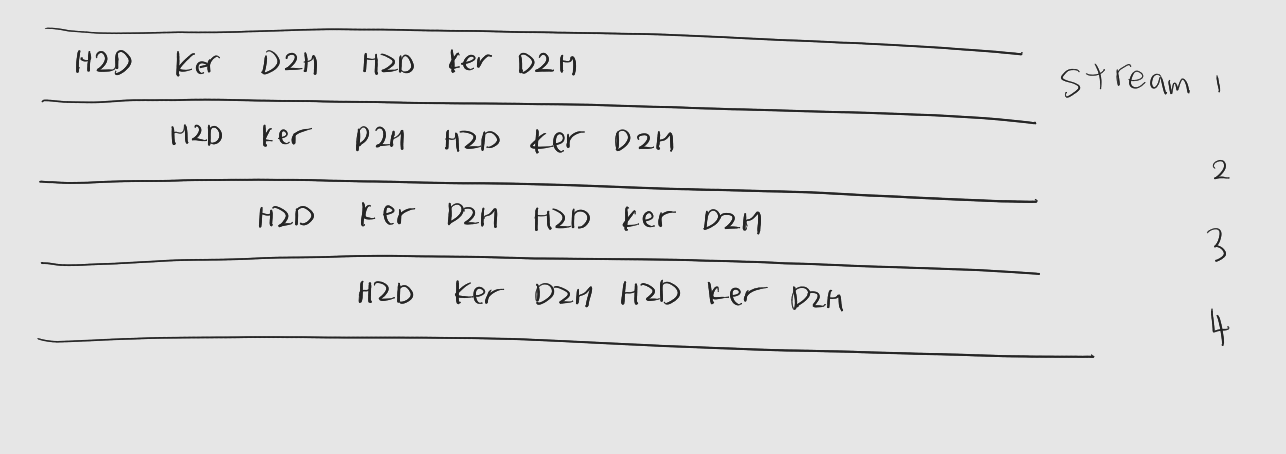
2.4 스트림 동기화
- 스트림 사이에 동기화가 필요한 경우
// 모든 스트림을 동기화
cudaError_t cudaDeviceSynchronize()
// 인자로 전달한 스트림에 대한 동기화
cudaError_t cudaStreamSynchronize(cudaStream_t)- 스트림의 현재 상태를 확인
cudaError_t cudaStreamQuery (cudaStream_t)
// 인자로 전달한 스트림의 현재 상태 확인
// 스트림 내 모든 작업이 완료된 경우 cudaSuccess (=0) 반환
// 남은 작업이 있는 경우 cudaErrorNotReady (=600) 반환- 암묵적으로 스트림을 동기화하는 경우
: 호스트에서 핀드 메모리 할당시
: 디바이스 메모리 할당 시
: 디바이스 메모리 값 초기화시
: 같은 메모리 위치에 데이터 복사하려 할 때
: NULL스트림에 있는 명령이 수행될 때
: L1 캐시/공유 메모리 설정 변경이 발생할 시
3. CUDA 이벤트
: 스트림 내 명령들 사이에 끼워 놓을 수 있는 일종의 표식
3.1 CUDA 이벤트 API
- CUDA 이벤트 생성 및 제거
// 이벤트 생성
cudaError_t cudaEventCreate (cudaEvent_t* event)
// 이벤트 제거
cudaError_t cudaEventDestroy (cudaEvent_t event)- CUDA 이벤트 기록
: 생성한 CUDA 이벤트를 스트림에 넣는 것
cudaError_t cudaEventRecord (cudaEvent_t event, cudaStream_t stream=0)- 스트림 동기화 및 상태 확인
: 호스트를 특정 CUDA 이벤트가 발생할 때 까지 대기하게 한다.
cudaError_t cudaEventSynchronize (cudaEvent_t evnet)- 이벤트 발생 여부 확인
cudaError_t cudaEventQuery (cudaEvent_t event) - CUDA 이벤트 사이 소요 시간 측정
: 서로 다른 두 CUDA 이벤트가 발생한 시간의 간격을 계산해주는 함수
cudaError_t cudaEventElapsedTime (float *ms, cudaEvent_t start,
cudaEvent_t stop);
// 계산된 시간은 첫 번째 인자에 ms단위로 반환3.2 CUDA 이벤트를 이용한 커널 및 스트림별 수행시간 측정
: CUDA 이벤트는 스트림 내 작업 흐름에 따라 정확한 시점에 발생 -> 정확한 시간 측정 가능
- CUDA 이벤트를 이용한 커널 수행 시간 측정
: 커널 수행 직전과 직후에 start와 stop 이벤트를 심어두었다.
// create two CUDA events
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop;
// record 'start' event
cudaEventRecord(start);
kernel<<<grid, block>>>(arguments);
// record 'stop' event
cudaEventRecord(stop);
// wait 'stop' event
cudaEventSynchronize(stop);
// caculate the elapsed time btw. two events
float time;
cudaEventElapsedTime(&time, start, stop);
// clean up the events
cudaEventDestroy(start);
cudaEventDestroy(stop);- 스트림별 수행시간 측정 예제
cudaStream_t stream[NUM_STREAMS];
cudaEvent_t start[NUM_STREAMS], end[NUM_STREAMS];
// 스트림 생성과 함께 이벤트도 생성
for (int i = 0; i < NUM_STREAMS; i++) {
cudaStreamCreate(&stream[i]);
cudaEventCreate(&start[i]); cudaEventCreate(&end[i]);
}
int chunkSize = ARRAY_SIZE / NUM_STREAMS;
int offset[NUM_STREAMS] = { 0 };
for (int i = 0; i < NUM_STREAMS; i++)
offset[i] = chunkSize * i;
for (int i = 0; i < NUM_STREAMS; i++) {
cudaEventRecord(start[i], stream[i]);
cudaMemcpyAsync(dIn + offset[i], in + offset[i], sizeof(int) * chunkSize, cudaMemcpyHostToDevice, stream[i]);
}
for (int i = 0; i < NUM_STREAMS; i++)
myKernel <<<chunkSize / 1024, 1024, 0, stream[i] >> > (dIn + offset[i], dOut + offset[i]);
// D2H 복사가 끝나고 이벤트 기록도 함께 진행
for (int i = 0; i < NUM_STREAMS; i++) {
cudaMemcpyAsync(out + offset[i], dOut + offset[i], sizeof(int) * chunkSize, cudaMemcpyDeviceToHost, stream[i]);
cudaEventRecord(end[i], stream[i]);
}
cudaDeviceSynchronize();
for (int i = 0; i < NUM_STREAMS; i++) {
float time = 0;
cudaEventElapsedTime(&time, start[i], end[i]);
printf("Stream[%d] : %f ms\n", i, time);
}4. 다중 GPU 및 이종 병렬 컴퓨팅
: 다중 GPU를 사용하는 CUDA 프로그램 작성 방법과 CPU와 GPU를 동시에 활용하는 코드 작성법
4.1 다중 GPU 사용
- 다중 GPU를 사용하는 방법은 CUDA API를 사용하기 전에 사용할 GPU를 선택해 주는것
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void main(void) {
int ngpus;
cudaGetDeviceCount(&ngpus);
// 시스템 내 GPU의 수를 npgpu 변수에 얻어온다.
// 각 GPU의 정보를 얻어와 출력
for (int i = 0; i < ngpus; i++) {
cudaDeviceProp devProp;
// GPU의 속성을 얻어온다
cudaGetDeviceProperties(&devProp, i);
printf("Device[%d](%s) compute capability : %d.%d.\n"
, i, devProp.name, devProp.major, devProp.minor);
}
}- 명령을 수행할 GPU 지정 API
cudaError_t cudaSetDevice (int deviceID)- 다중 GPU 사용 예시
cudaSetDevice(0);
cudaMemcpy(...);
kernel0 <<<...>>> (...);
cudaMemcpy(...);
cudaSetDevice(1);
cudaMemcpy(...);
kernel1 <<<...>>> (...);
cudaMemcpy(...);-
대상 GPU의 변경은 신중히 선택
: 현재 연산을 수행할 GPU가 대상 데이터를 갖고 있는지 잘 체크 -
특정 코드 지점에서 대상 GPU를 확인하는 CUDA API
cudaError_t cudaGetDevice (int *deviceID)4.2 이종 병렬 컴퓨팅
-
이종 구조 (heterogeneous architecture)
: 둘 이상의 서로 다른 연산 자원으로 구성된 시스템 구조
: CPU와 GPU를 동시에 가지는 일반적인 컴퓨터
: 서로 다른 종류의 GPU를 가진 다중 GPU 시스템 -
이종 컴퓨팅 (heterogeneous computing)
: 이종의 연산 자원을 동시에 사용해서 하나의 문제를 해결 -
실제 프로그램 개발시
: 호스트 코드와 디바이스 코드를 분리해서 작성해야 유지/보수 및 각 코드에 적합한 컴파일 수행에 유리
: 호스트 코드는 gcc 컴파일러 사용, CUDA 코드는 nvcc 컴파일러 사용 -
예제 코드
// kernelCall.h
// 커널 호출을 위한 함수 선언을 헤더파일에 작성, 디바이스 코드 및 호스트 코드에서 include해서 사용
#pragma once
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
void kernelCall(void);
// DeviceCode.cu
// 커널의 정의와 커널 호출 함수를 작성
#include "KernelCall.h"
__global__ void kernel(void)
{
printf("Device code running on the GPU\n");
}
void kernelCall(void)
{
kernel <<<1, 10>>> ();
}
// main.cpp
#include "kernelCall.h"
void main() {
kernelCall();
printf("Host code running on CPU\n");
cudaDeviceSynchronize();
}- 헤더파일에 대한 정리는 https://programfrall.tistory.com/20 를 참고
