- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. 전역 메모리 접근 최적화
- 전역 메모리에 대한 접근은 L2 및 L1 캐시 (사용시)을 통해 이루어짐.
: L2 캐시에 대한 기본 전송 단위 (Cache Line) 크기는 32byte
: L1 캐시에 대한 Cache Line 크기는 128byte
: 각 캐시 라인은 디바이스 메모리에서 크기가 같은 메모리 블록과 대응된다.
1.1 전역 메모리에 대한 접근 최적화를 위해 고려할 특성
-
정렬된 메모리 접근 (Alligned memory access)
: 요청 데이터의 시작점이 캐시에 데이터 블록의 시작 지점과 일치
: Device Mem. 의 데이터블록은 캐시 라인 크기 단위로 분할, 그 경계는 캐시 라인 크기의 배수 -
병합된 메모리 접근 (Coalesced memory access)
: 32개 스레드가 연속적인 메모리 공간의 데이터에 접근.
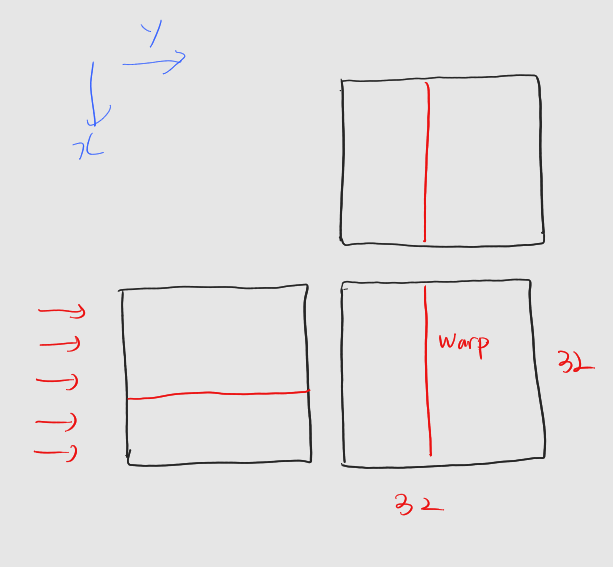
1.2 예제 : 행렬 곱 커널의 스레드 레이아웃
* 결과행렬은 32 x 32
- 행 -> x dimension, 열 -> y dimension
__global__ void MatMul_xRow(int* matA, int* matB, int* matC, int m, int n, int k)
{
int row = blockDim.x * blockIdx.x + threadIdx.x;
int col = blockDim.y * blockIdx.y + threadIdx.y;
if (row >= m || col >= n)
return;
int val = 0;
for (int i = 0; i < k; i++)
val += matA[row * k + i] * matB[i * n + col];
matC[row * n + col, n] = val;
}- 접근 패턴 분석
-
워프는 연속된 스레드로 구성되며, x, y, z차원 순으로 연속성을 가진다.
: 행렬 C의 한 열을 하나의 워프가 처리한다
: 이는 워프 내 스레드가 한 열을 동시에 접근한다는 것.
: 열을 이루는 데이터는 메모리 상 불연속 -> 비효율적 접근 -
행렬 C의 (i, col) 원소를 계산하기 위해서는 행렬 A의 i번째 행과 행렬 B의 col번째 열의 원소를 순차적으로 접근.
: 행렬 B의 열은 col-번째 열로 동일 -> 워프 내 스레드가 동일 데이터로 접근하는 경우, 이는 하나의 데이터 전송으로 처리되고 각 스레드로 broadcasting 된다. B에 대한 접근은 효율적.
: 반면 워프내 스레드는 A의 서로 다른 i번째 행에 접근해야 한다. (같은 열)
: 한 순간에는 행렬 A의 서로 다른 열들에 접근하는 것.
: 즉 불연속적인 메모리 접근 -> 비효율 적.
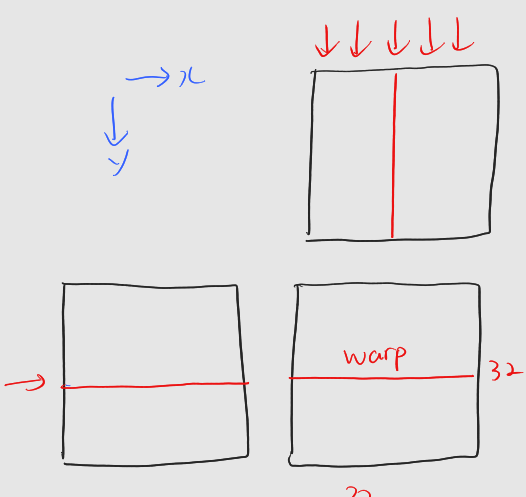
- 행 -> y dimension, 열 -> x dimension
__global__ void MatMul_yRow(int* matA, int* matB, int* matC, int m, int n, int k)
{
int row = blockDim.y * blockIdx.y + threadIdx.y;
int col = blockDim.x * blockIdx.x + threadIdx.x;
if (row >= m || col >= n)
return;
int val = 0;
for (int i = 0; i < k; i++)
val += matA[row * k + i] * matB[i * n + col];
matC[row * n + col, n] = val;
}-
접근 패턴 분석
-
하나의 워프가 행렬 C의 하나의 행을 담당한다
: 워프 내 스레드들이 한 행을 동시에 접근
: 행은 메모리 공간 내에서 연속적으로 배치 -> 효율적인 메모리 접근 -
현재 하나의 워프는 행렬 C의 행 하나를 담당하기 때문에 워프 내 모든 스레드가 동일하게 행렬 A의 동일한 행에 접근
: 따라서 행렬 A에 대한 접근은 한 번의 메모리 전송으로 처리, 스레드들로 broadcast
: 행렬 B의 경우 워프 내 스레드들이 서로 다른 열을 담당
: 한 순간에는 동일한 k번째 행에 접근 -> 효율적인 메모리 접근
1.3 구조체의 배열 vs. 배열의 구조체
- 구조체와 배열의 조합법
- 구조체의 배열 (Array of Structure, AoS)
struct StructElement {
float x;
float y;
};
struct StructElement AoS[N];- 배열의 구조체 (Struct of Array, SoA)
struct Arrays {
float x[N];
float y[N];
};
struct Arrays SoA;-
워프 내 스레드들은 하나의 명령어에 의해 동시에 제어
: 특정 순간에 같은 축의 좌푯값에 접근함을 의미. -
AoS 구조의 경우
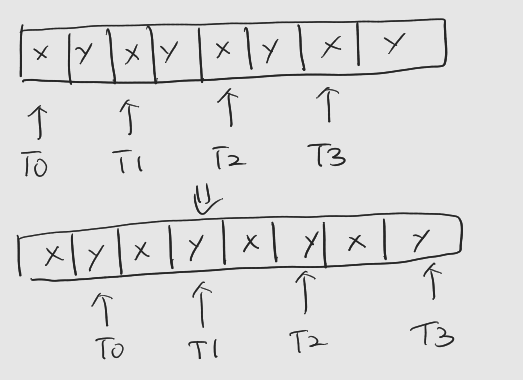
-
SOA 구조의 경우
: 각 차원의 좌푯값이 연속해서 자리를 잡고 있기에 병합된 메모리 접근.
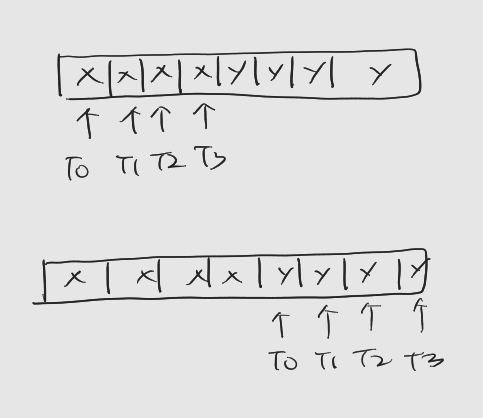
-
각 알고리즘마다 알맞은 데이터 접근 패턴이 다를 수 있으니, 메모리 접근 패턴에 대한 원리를 이해하고 사용
2. 공유 메모리 접근 최적화
2.1 메모리 뱅크
-
공유 메모리는 32개의 메모리 뱅크로 구성
: 메모리 뱅크는 메모리에 대한 접근을 관리하는 모듈, 서로 독립적
: 32개 -> 워프 내 스레드의 개수
: 즉, 워프 내 모든 스레드들이 동시에 공유 메모리의 데이터에 접근할 수 있도록 메모리 뱅크 수를 32개로 맞추어 놓은 것.
: 뱅크의 구성 단위는 8바이트 -
공유 메모리는 32개의 영역으로 나누어져 있다
: 각 영역은 해당 메모리 뱅크 통해서만 접근
: 32개의 스레드가 서로 다른 뱅크 영역에 접근하면 동시에 메모리 접근 수행 -> 뱅크 충돌이 없는 경우. -
여러 스레드가 하나의 뱅크의 메모리 영역에 접근
: 한 스레드씩 순차적으로 공유 메모리에 접근 -> 공유 메모리 접근이 직렬화, 뱅크 충돌
2.2 예제 : 공유 메모리 활용 행렬 곱 커널
-
10장의 공유 메모리를 활용해 성능을 향상시킨 코드
: 행은 x차원__global__ void MatMul_SharedMem(DATA_TYPE* matA, DATA_TYPE* matB, int* matC, int m, int n, int k) { int row = blockDim.x * blockIdx.x + threadIdx.x; int col = blockDim.y * blockIdx.y + threadIdx.y; int val = 0; __shared__ int subA[BLOCK_SIZE][BLOCK_SIZE]; __shared__ int subB[BLOCK_SIZE][BLOCK_SIZE]; int localRow = threadIdx.x; int localCol = threadIdx.y; for (int bID = 0; bID < ceil((float)k / BLOCK_SIZE); bID++) { int offset = bID * BLOCK_SIZE; // load A and B if (row >= m || offset + localCol >= k) subA[localRow][localCol] = 0; else subA[localRow][localCol] = matA[row * k + (offset + localCol)]; if (col >= n || offset + localRow >= k) subB[localRow][localCol] = 0; else subB[localRow][localCol] = matB[(offset + localRow) * n + col]; __syncthreads(); // compute for (int i = 0; i < BLOCK_SIZE; i++) { val += subA[localRow][i] * subB[i][localCol]; } __syncthreads(); } if (row >= m || col >= n) return; matC[row * n + col] = val; } -
행렬 A의 데이터 블록을 그대로 공유 메모리로 복사하는 경우
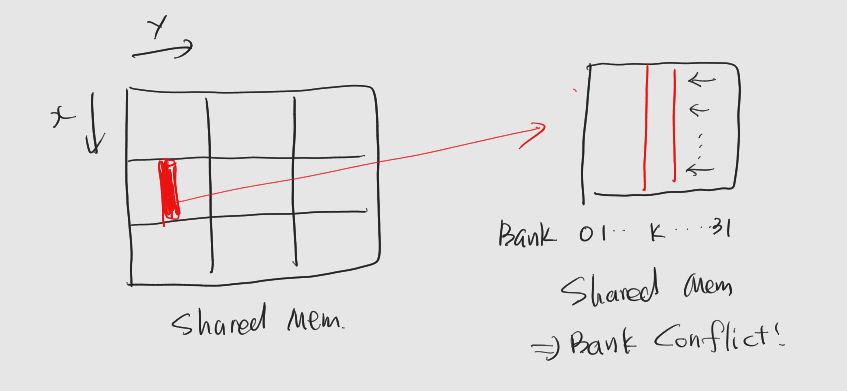
: 행렬을 x차원으로 매칭 -> 하나의 워프는 특정 순간에 행렬 A의 한 열에 접근
: 공유 메모리 입장에서 보면 한 열은 하나의 뱅크의 메모리 영역 -> 뱅크 충돌 -
간단한 해결은 행을 y차원으로 매칭
-
뱅크 충돌만의 영향을 확인하기 위해, 행렬을 전치
: 데이터 블록의 행과 열을 바꾸어 공유 메모리로 옮긴다
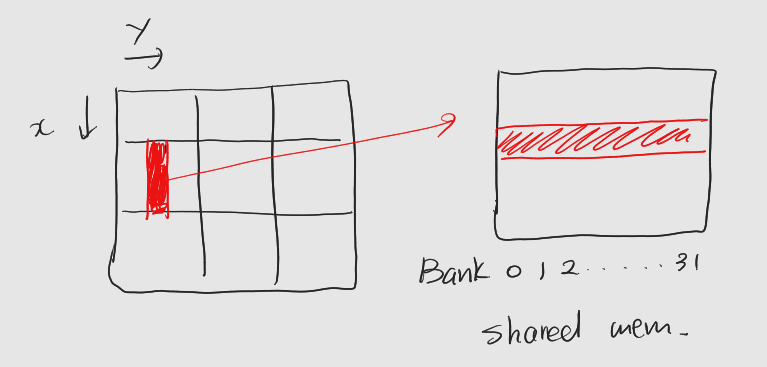
: 전역메모리에서의 Column이 공유 메모리에서 Row로 저장, 해당 Column들이 다른 뱅크로 배정
: 뱅크 충돌 사라진다.
: 코드 상에서subA[localRow][localCol]->subA [localCol][localRow]로,subA[localRow][i]->subA[i][localRow]로 전치.
