- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. CUDA 스레드 계층 구조
1.1 CUDA 스레드 계층
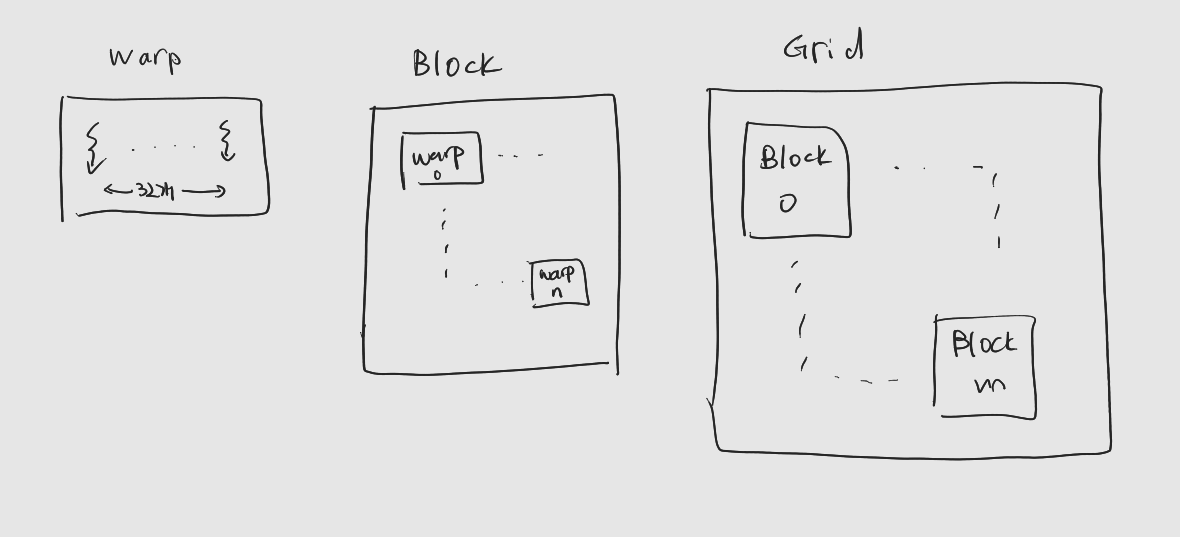
스레드 (Thread)
- CUDA에서 연산을 수행하거나 CUDA 코어를 사용하는 기본 단위.
: 커널 코드는 모든 스레드에 공유, 각 스레드가 독립적으로 커널 코드를 수행.
워프 (Warp)
- 32개의 스레드를 하나로 묶은 것, CUDA의 기본 수행 단위.
: 한 워프 내의 thread들은 하나의 제어 장치에 의해 제어. - SIMT의 Multiple Thread (MT) 의 단위가 되는 것
: 하나의 Instruction에 따라 32개의 Thread가 동시에 움직인다.
블록 (Block)
-
Warp의 상위 스레드 그룹, 워프들의 집합.
-
하나의 블록에 포함된 각 스레드는 자신만의 고유한 스레드 번호 (Thread ID)를 가진다.
: 서로 다른 블록에 포함된 스레드들은 같은 스레드 번호를 가질 수 있다. -
각 블록은 자신만의 고유한 block ID가 존재
: 스레드를 정확히 지칭하기 위해서는 block ID와 thread ID를 모두 사용해야 한다. -
블록 내 스레드는 1차원, 2차원, 3차원 형태로 배치될 수 있다.
그리드 (Grid)
-
가장 상위 계층
: 블록들의 그룹. -
그리드 내 블록 또한 1차원, 2차원, 3차원 형태로 배치될 수 있다.
-
커널이 호출되면 그리드가 생성.
: 하나의 그리드는 하나의 커널 호출과 1:1 대응.
1.2 CUDA 스레드 계층을 위한 내장 변수들
- 그리드 및 블록의 형태와 각 스레드가 자신이 속한 블록 번호, 그리고 자신의 스레드 번호를 확인할 수 있는 내장변수 (Built-in variable)을 제공.
: 내장 변수의 값은 커널이 실행될 때 결정, 각 스레드는 자신에게 할당된 내장 변수 갑을 참조 가능.
gridDim
- 그리드의 형태 정보를 담고있는 구조체.
: 각 차원의 크기를 담고 있다.
: 사용하지 않는 차원의 크기는 1
: 커널 내 모든 스레드가 공유
blockIdx
- 현재 스레드가 속한 블록의 번호를 담고 있는 구조체.
blockDim
-
블록의 형태 정보를 담고 있는 구조체.
: 각 차원의 크기를 담고 있다.
: 사용하지 않는 차원의 크기는 역시 1 -
커널이 실행될 때 그리드 및 블록 형태가 결정, 한 그리드 내 모든 블록은 동일한 형태를 가진다.
:blockDim은 그리드 내 모든 스레드가 공유.
threadIdx
- 블록 내에서 현재 스레드가 부여받은 스레드 번호
스레드 번호와 워프의 구성
-
Warp는 연속된 32개의 스레드로 구성
: 연속성은 x, y, z 순으로 결정.
: 즉, 우선적으로 (0,0,0)~(31,0,0) 스레드가 하나의 워프를 구성한다.
: 만ㅇ갹 x차원의 길이가 워프의 크기보다 작다면, (0,0,0)~(0,31,0) 스레드가 하나의 워프를 이루게 된다. -
커널의 성능에 큰 영향을 미치는 요소 중 하나인 메모리 접근 패턴을 이해하려면 워프를 구성하는 스레드를 정확히 인지하는 것이 중요.
: 워프 수준에서 스레드 사이의 작업을 분배할 때도 중요하다.
1.3 그리드 및 블록의 최대 크기 제한
그리드의 크기
-
x차원 최대 길이는 2^31 -1
: 제한 없다고 생각해도 됨 -
y, z차원의 경우 최대 길이는 2^16-1
블록의 크기
-
x, y 차원 최대 크기는 2^10, z차원 최대 크기는 2^6
-
한 블록이 가질 수 있는 최대 스레드의 개수는 1024개.
2. CUDA 스레드 구조와 커널 호출
2.1 스레드 레이아웃 설정 및 커널 호출
-
스레드 레이아웃
: 스레드의 배치 형태, 그리드와 블록의 형태로 정의
: 커널 호출 시 설정,<<<>>>실행 구성 문법을 통해 전달.kernel<<<그리드의 형태, 블록의 형태>>>():
<<<1, n>>>의 의미는 (1,1,1) 크기의 그리드를 사용, (n,1,1) 크기의 블록 사용. -
dim3
: x, y, z 멤버 변수를 가지는 구조체, 각 차원의 크기를 담는 역할.
: 일반적으로<<<>>>안에dim3구조체를 사용해서 전달.dim3 dimGrid(4, 1, 1); dim3 dimBlock(8, 1, 1); kernel<<<dimGrid, dimBlock>>>();
2.2 스레드 레이아웃 설정 및 확인 예제
- 예제 코드는 다음과 같다.
%%cu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
__global__ void checkIndex(void)
{
printf("threadIdx : (%d %d %d) blockIdx : (%d %d %d) threadDim : (%d %d %d) gridDim : (%d %d %d)\n", threadIdx.x, threadIdx.y, threadIdx.z, blockIdx.x, blockIdx.y, blockIdx.z, blockDim.x, blockDim.y, blockDim.z, gridDim.x, gridDim.y, gridDim.z);
}
int main(void)
{
dim3 dimBlock(3, 1, 1);
dim3 dimGrid(2, 1, 1);
printf("dimGrid.x = %d dimGrid.y = %d dimGrid.z = %d\n", dimGrid.x, dimGrid.y, dimGrid.z);
printf("dimBlock.x = %d dimBlock.y = %d dimBlock.z = %d\n", dimBlock.x, dimBlock.y, dimBlock.z);
checkIndex<<<dimGrid, dimBlock>>>();
cudaDeviceSynchronize();
return 0;
}- 실행 결과는 다음과 같다.
dimGrid.x = 2 dimGrid.y = 1 dimGrid.z = 1
dimBlock.x = 3 dimBlock.y = 1 dimBlock.z = 1
threadIdx : (0 0 0) blockIdx : (1 0 0) threadDim : (3 1 1) gridDim : (2 1 1)
threadIdx : (1 0 0) blockIdx : (1 0 0) threadDim : (3 1 1) gridDim : (2 1 1)
threadIdx : (2 0 0) blockIdx : (1 0 0) threadDim : (3 1 1) gridDim : (2 1 1)
threadIdx : (0 0 0) blockIdx : (0 0 0) threadDim : (3 1 1) gridDim : (2 1 1)
threadIdx : (1 0 0) blockIdx : (0 0 0) threadDim : (3 1 1) gridDim : (2 1 1)
threadIdx : (2 0 0) blockIdx : (0 0 0) threadDim : (3 1 1) gridDim : (2 1 1): 각 스레드가 자신의 threadIdx와 blockIdx, blockDim, gridDim을 출력한다.
3. 큰 벡터에 대한 벡터 합 CUDA 프로그램 - 스레드 레이아웃
- 3장에서의 벡터 합 예제 코드를 갖고왔다.
%%cu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// The size of the vector
#define NUM_DATA 1024
// Simple vector sum kernel
__global__ void vecAdd(int* _a, int* _b, int* _c)
{
int tID = threadIdx.x;
_c[tID] = _a[tID] + _b[tID];
}
int main(void)
{
int* a, * b, * c, * hc;
int *da, *db, *dc;
int memSize = sizeof(int) * NUM_DATA;
printf("%d elements, memSize = %d bytes\n", NUM_DATA, memSize);
// memory allocation on the host_side
a = new int[NUM_DATA]; memset(a, 0, memSize);
b = new int[NUM_DATA]; memset(b, 0, memSize);
c = new int[NUM_DATA]; memset(c, 0, memSize);
hc = new int[NUM_DATA]; memset(hc, 0, memSize);
// Data generation
for (int i = 0 ; i < NUM_DATA; i++)
{
a[i] = rand() % 10;
b[i] = rand() % 10;
}
//Vector sum on the host
for (int i = 0 ; i < NUM_DATA ; i++)
hc[i] = a[i] + b[i];
// Memory allocation on te device-side
cudaMalloc(&da, memSize); cudaMemset(da, 0, memSize);
cudaMalloc(&db, memSize); cudaMemset(db, 0, memSize);
cudaMalloc(&dc, memSize); cudaMemset(dc, 0, memSize);
// Data copy : Host -> Device
cudaMemcpy(da, a, memSize, cudaMemcpyHostToDevice);
cudaMemcpy(db, b, memSize, cudaMemcpyHostToDevice);
// Kernel call
vecAdd <<<1, NUM_DATA>>> (da, db, dc);
// Copy results : Device -> Host
cudaMemcpy(c, dc, memSize, cudaMemcpyDeviceToHost);
// Release device Memory
cudaFree(da);
cudaFree(db);
cudaFree(dc);
// Check results
bool result = true;
for (int i = 0 ; i < NUM_DATA ; i++)
{
if (hc[i] != c[i])
{
printf("[%d] The result is not matched! (%d, %d)\n", i, hc[i], c[i]);
result = false;
}
}
if (result)
printf("GPU works well!\n");
// Release host memory
delete[] a;
delete[] b;
delete[] c;
return 0;
}-
NUM_DATA가 1024보다 크다면?
: 블록의 최대 thread수가 1024개이기 때문에, 스레드 레이아웃을 잡아줘야 한다.
: 블록을 2차원, 3차원으로 늘리는 방법은 쓸 수 없다. 최대 1024개의 스레드만 가질 수 있기 때문. -
1차원 그리드, 1차원 블록을 사용한다고 가정해보자. 우리는 커널
vecAdd()를 호출할 때 다음과 같이 호출해야 한다.vecAdd <<<ceil(NUM_DATA/1024), 1024>>> (da, db, dc);:
ceil()은 올림연산을 수행하는 함수. -
NUM_DATA가 4224인 경우
: 마지막 블록 뒤쪽의 스레드들은 담당할 데이터가 없다.
: 그 스레드들은 연산에 참여하지 않도록 하는 조치가 필요하다. (다음 장에서 배움)
: 스레드 레이아웃을 그림으로 그려보면 다음과 같다.
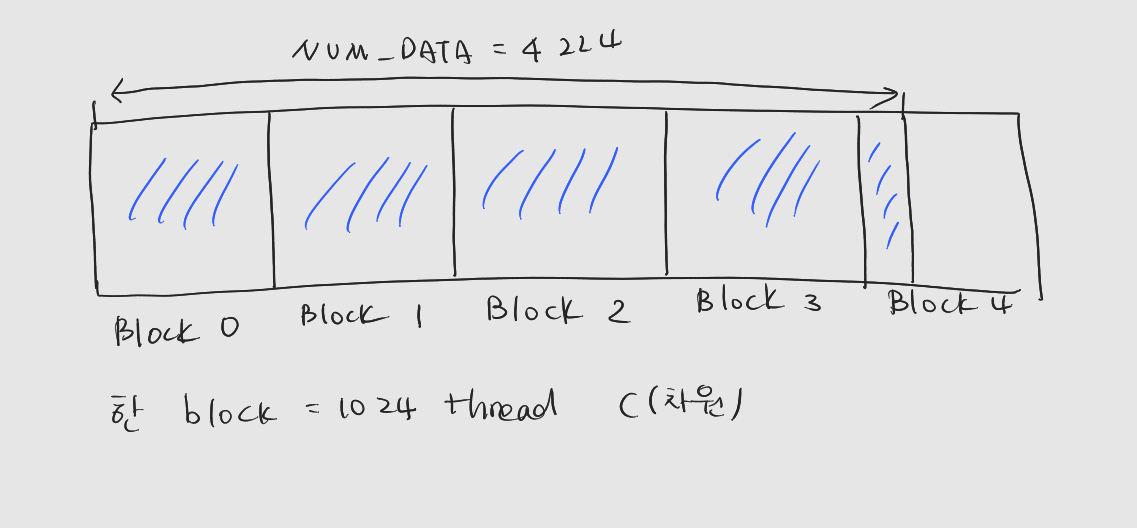
-
스레드 레이아웃을 적용한 상태에서 프로그램을 실행시키면 다음과 같다.
NUM_DATA는 1030으로 설정한 후 실행.1030 elements, memSize = 4120 bytes [1024] The result is not matched! (11, 0) [1025] The result is not matched! (3, 0) [1026] The result is not matched! (13, 0) [1027] The result is not matched! (12, 0) [1028] The result is not matched! (13, 0) [1029] The result is not matched! (13, 0): 어디가 문제일까?
-
문제는
vecAdd()커널에 있다. 다음은 3장에서 작성한vecAdd()커널이다.// Simple vector sum kernel __global__ void vecAdd(int* _a, int* _b, int* _c) { int tID = threadIdx.x; _c[tID] = _a[tID] + _b[tID]; }: 한 블록 내에서는 모든 스레드가 서로 다른 번호를 갖지만, 다른 블록에는 동일한 번호를 갖는 스레드가 있다.
: 이 커널 함수에는 블록을 고려하지 않았따.
: 스레드가 속한 블록 번호를 고려해 담당할 데이터의 번호를 결정해야함. 이를 스레드 인덱싱이라고 한다.
