- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. 1024보다 큰 벡터의 합 구하기
1.1 스레드 레이아웃 결정
- 블록의 크기 결정 과정
: 블록 크기 결정 -> 데이터의 크기 및 블록 크기에 따라 그리드 크기 결정
: 커널의 성능 특성과 GPU 자원의 제한 고려
1.2 각 스레드가 접근할 데이터의 인덱스 계산
-
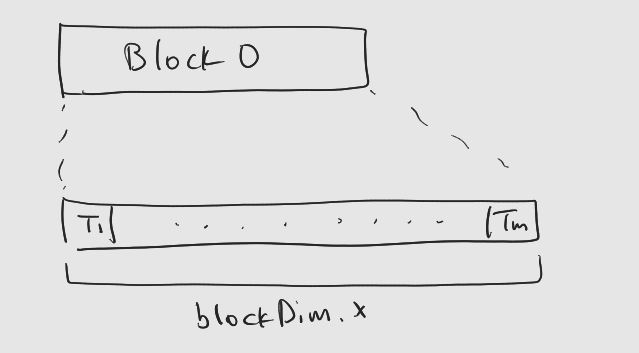
블록이 하나인 경우
: vector[threadIdx.x]
-
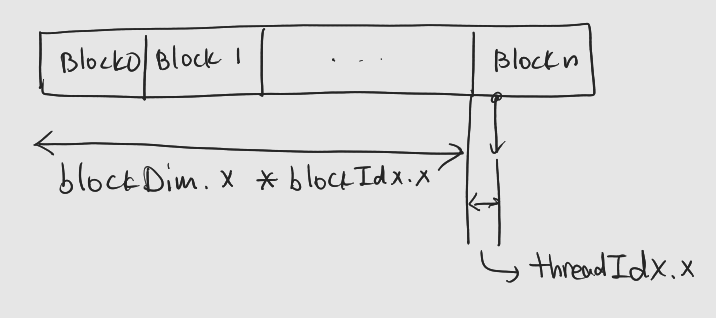
블록이 여러개 인 경우
: vector[blockIdx.x * blockDim.x + threadIdx.x]
1.3 계산된 인덱스를 반영한 커널 작성
-
1.2에서 계산한 vector의 index와 더불어, 담당할 데이터가 없는 스레드들은 연산에 참여하지 않도록 하는 예외처리를 해주는 코드를 포함하는 커널을 작성해보자.
__global__ void vecAdd(int* _a, int* _b, int* _c, int _size) { int tID = blockIdx.x * blockDim.x + threadIdx.x; if(tID < _size) // 예외처리 _c[tID] = _a[tID] + _b[tID]; } -
수정된 커널에 맞는 스레드 레이아웃 및 커널 호출
dim3 dimGrid(ceil((float)NUM_DATA / 256), 1, 1) dim3 dimBlock(256, 1, 1) vecAdd <<<dimGrid, dimBlock>>> (d_a, d_b, d_c, NUM_DATA)
2. 스레드 인덱싱
2.1 메모리 속 배열의 모습
- 메모리에는 차원 개념이 없음
: 저장 공간이 일렬로 나열된 형태.
: 고차원 배열 1차원 형태로 저장.
: 저장 규칙은 낮은 차원 (x-차원) 에서 높은 차원 (y-차원) 순서로 저장.
2.2 스레드 인덱싱 연습 : 스레드의 전역번호
- 커널 내 스레드가 배열 데이터(즉 1차원 데이터)와 1:1로 매칭되는 경우의 스레드 인덱싱 연습
: 스레드마다 하나의 데이터를 담당하는 경우 그리드 내에서 스레드의 전역번호 (global ID)를 만들어 사용
블록 내 스레드의 전역 번호
: 하나의 블록 안에서 스레드의 전역 ID를 계산
-
1차원 블록
: 스레드의 전역 번호는threadIdx.x -
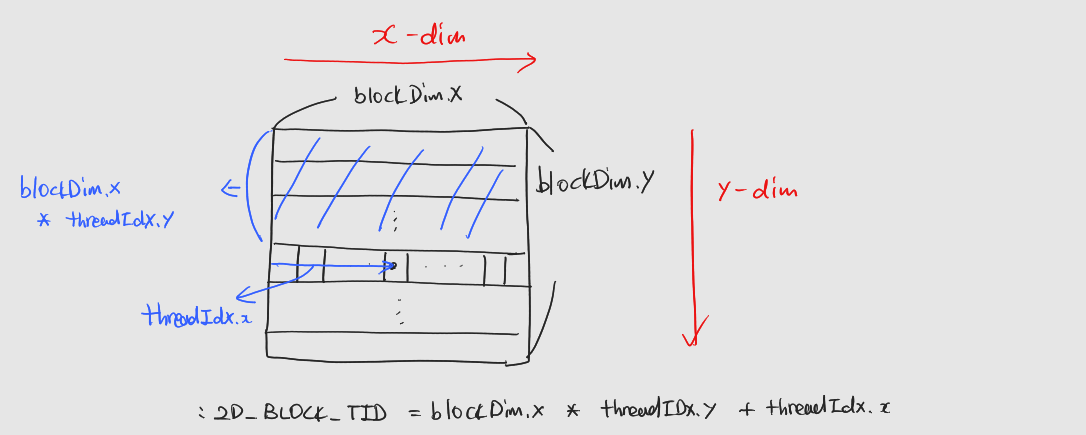
2차원 블록
: 2D_BLOCK_TID = (blockDim.x*threadIdx.y+threadIdx.x)
: 그림으로 설명하면 다음과 같다.
-
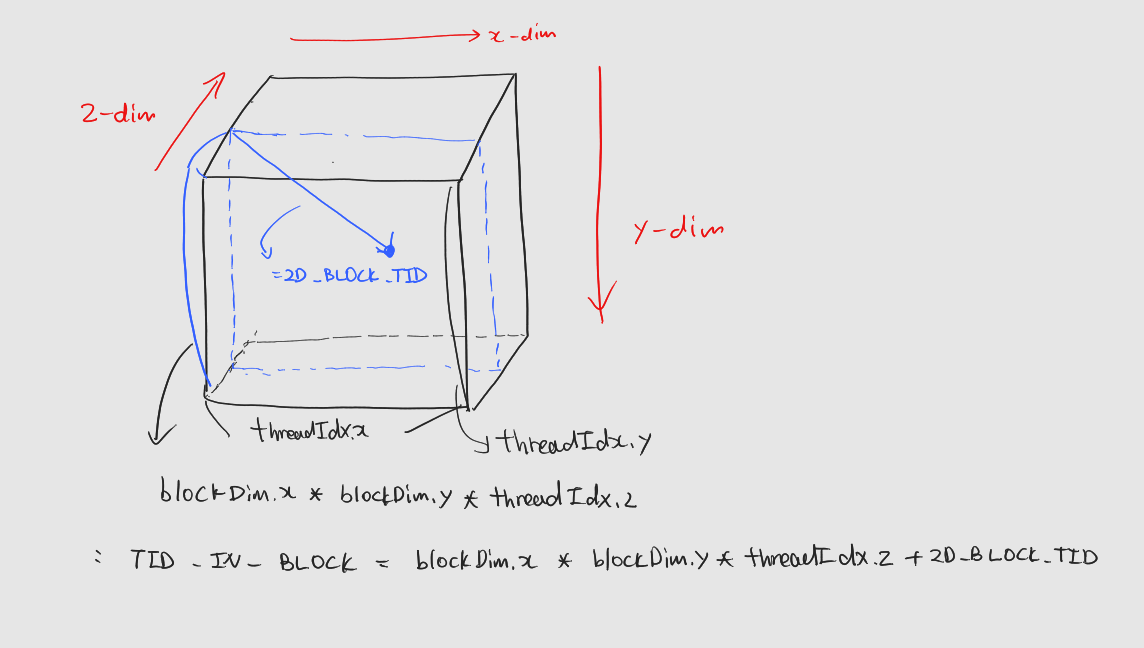
3차원 블록
: TID_IN_BLOCK =blockDim.xxblockDim.yxthreadIdx.z+ 2D_BLOCK_TID
: 그림으로 설명하면 다음과 같다.
그리드 내 스레드의 전역 번호
: 만약 그리드 내 블록이 하나라면 TID_IN_BLOCK이 그리드 내에서 각 스레드의 전역 번호.
: 하지만 만약 블록이 여러 개라면, 다음의 정보가 필요하다.
1) 자신이 속한 블록의 앞 블록까지의 스레드 개수
2) 자신이 속한 블록 내에서 자신이 몇 번째 스레드인지 = TID_IN_BLOCK
-
1차원 그리드
: 자신이 속한 블록의 앞 블록까지의 스레드 개수 =blockIdx.xx NUM_THREAD_IN_BLCOK
: 자신이 속한 블록 내에서 자신이 몇 번째 스레드인지 = TID_IN_BLCOK
: 1D_GRID_TIM = (blcokIdx.xx NUM_THREAD_IN_BLOCK ) + TID_IN_BLOCK -
2차원 그리드
: 2D_GRID_TID = (gridDIm.xxblockDIm.y) x NUM_THREAD_IN_BLOCK + 1D_GRID_TID -
3차원 그리드
: GLOBAL_TID = (gridDim.xxgridDim.yxblockDim.zx NUM_THREAD_IN_BLOCK ) + 2D_GRID_TID
2.3 스레드 인덱싱 연습 : 2차원 데이터에 대한 인덱싱
-
행렬 등 2차원 데이터에 대한 인덱싱 연습
: 2차원 스레드 번호를 사용해 각 스레드가 행렬의 담당 원소를 가리키게 하는 것이 대표적.
: 우선 하나의 블록만 사용하는 2차원 인덱싱 방법이다. -
x차원 스레드 번호를 행렬의 열, y차원 스레드 번호를 행렬의 행에 대응.
: col = threadIdx.x
: row = threadIdx.y -
행렬을 포함한 고차원 데이터도 메모리에는 1차원 형태로 저장
: index(row, col) = row xblockDim.x+ col =threadIdx.yxblockDim.x+threadIdx.x -
다음은 예제코드이다.
__global__ void matAdd_2D_index (float* _dA, float* _dB, float* _dC) { unsigned int col = threadIdx.x; unsigned int row = threadIdx.y; unsigned in index = row * blockDim.x + col; _dC[indxe] = _dA[index] + _dB[index]; } // kernel call dim3 blockDim(COL_SIZE, ROW_SIZE) matAdd_2D_index <<<1, blockDim>>> (dA, dB, dC)
3. CUDA 기반 대규모 행렬 합 프로그램
- 행과 열의 크기가 각각 1024보다 큰 두 행렬 A, B를 더해서 행렬 C에 저장
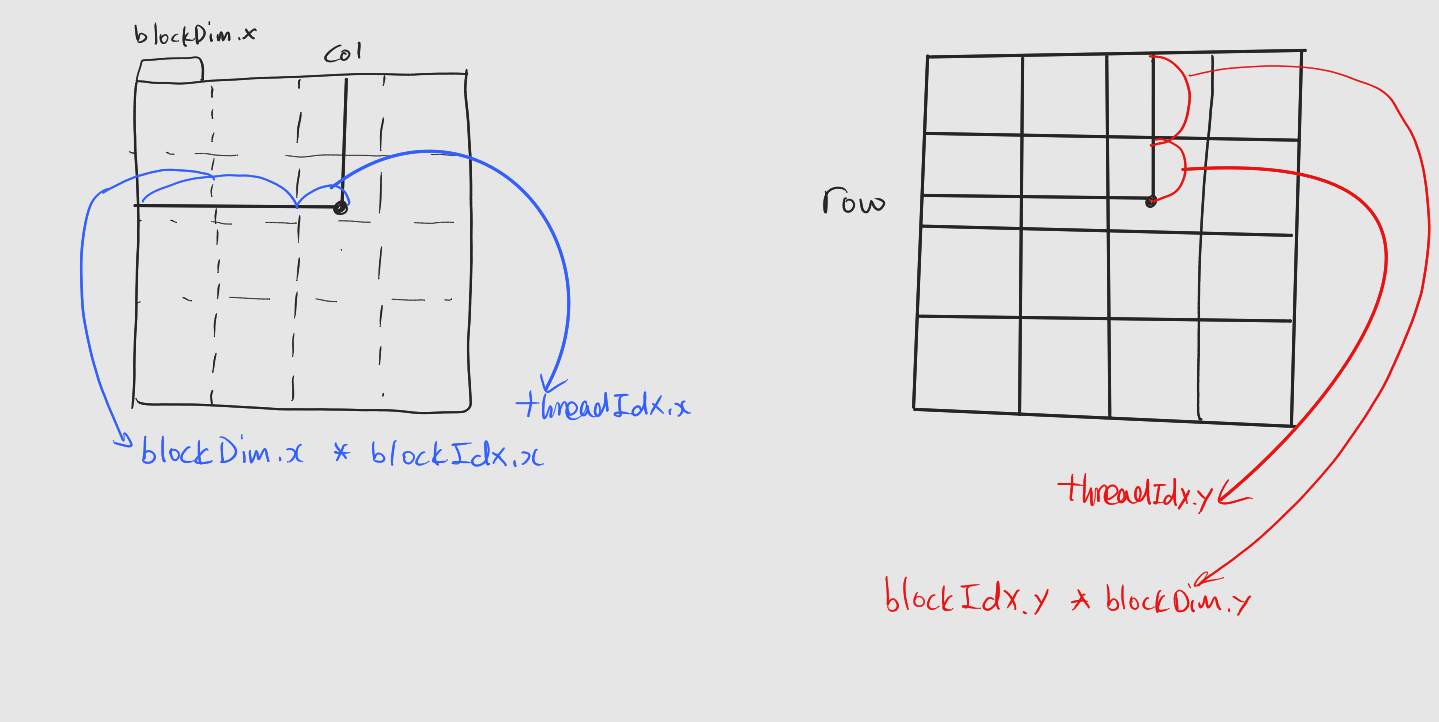
3.1 2차원 그리드, 2차원 블록 레이아웃
-
x차원 번호를 column, y차원 번호를 row로 매칭.
: col = (blockDim.xxblockIdx.x) +threadIdx.x
: row = (blockDim.yxblockIdx.y) +threadIdx.y
: 그림으로 설명하면 다음과 같다.
-
행렬이 메모리상에서는 1차원 배열 형태로 나열되는 것을 고려하면 행렬의 (row, col) 위치는 메모리상에서 다음과 같이 계산
: index (row, col) = row * COL_SIZE + col -
커널 코드 작성
__global__ void MatAdd_G2D_B2D (float* matA, float* matB, float* matC, int ROW_SIZE, int COL_SIZE) { unsigned int col = threadIdx.x + blockIdx.x * blockDim.x; unsigned int row = threadIdx.y + blockIdx.y * blockDim.y; unsigned int index = row * COL_SIZE + col; if (col < COL_SIZE && row < ROW_SIZE) MatC[index] = MatA[index] + matB[index]; } -
커널 호출
: 블록 크기를 (32, 32)로 잡고 커널을 호출해보자dim3 blockDim(32, 32); dim3 gird Dim(ceil((float)ROW_SIZE / blockDim.x), ceil((float)ROW_SIZE / blockDim.y)); MatAdd_G2D_B2D <<<girdDim, blockDim>>> (A, B, C, ROW_SIZE, COL_SIZE);
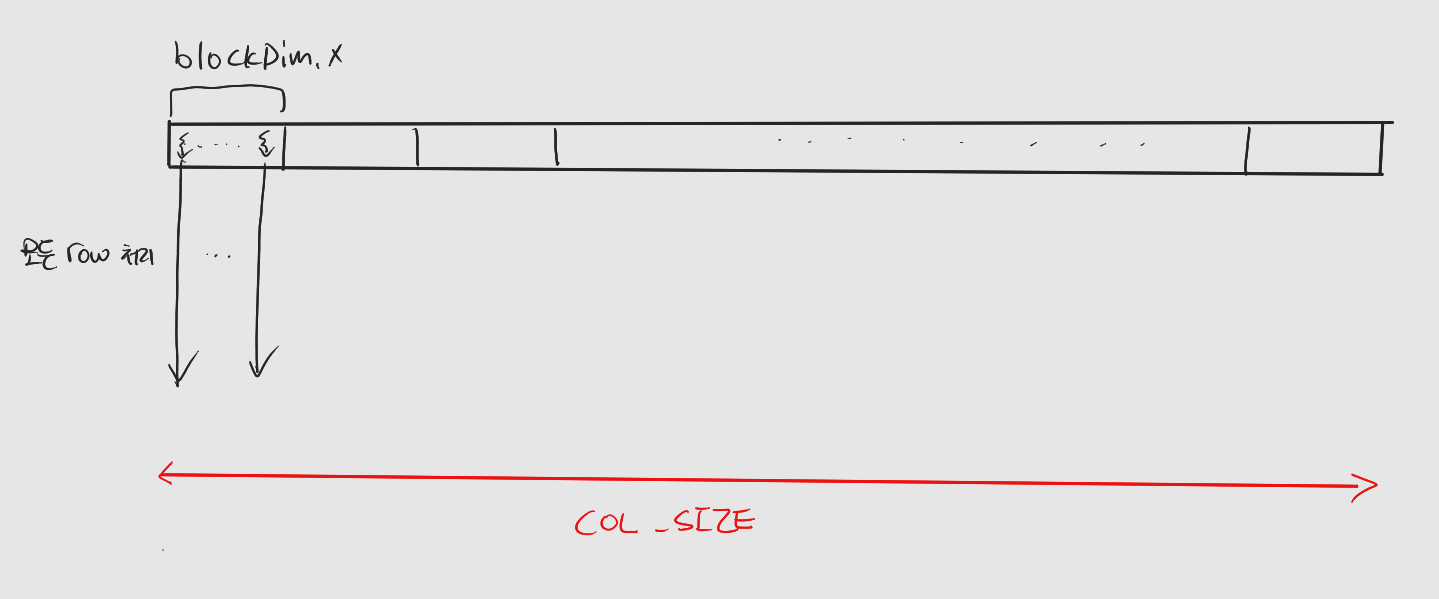
3.2 1차원 그리드, 1차원 블록 레이아웃
-
스레드 개수가 행렬 크기 (전체 원소 개수)와 같도록 블록과 그리드의 크기를 잡는다.
: x차원 전역 번호를 행렬의 열로 매칭하면 스레드 번호로는 행을 구분할 수 없다
: 이는 각 스레드가 본인 담당 열에 대한 모든 행을 처리하도록 하는 방법으로 해결.
: 그림으로 설명하면 다음과 같다.
-
커널 코드 작성
__global__ void MatAdd_G1D_B1D (float* matA, float* matB, float* matC, int ROW_SIZE, int COL_SIZE) { unsigned int col = threadIdx.x + blockIdx.x * blockDim.x; if (col < COL_SIZE) { for (int row = 0; row < ROW_SIZE; row++) // 한 thread에서 모든 row에 대해 처리 { int index = row * COL_SIZE + col; MatC[index] = MatA[index] + MatB[index]; } } } -
커널 호출
: 블록 크기를 (32)로 잡고 커널 호출dim3 blockDim(32); dim3 girdDim(ceil((float)COL_SIZE / blockDim.x)); MatAdd_G1D_B1D <<< gridDim, blockDim>>> (A, B, C, ROW_SIZE, COL_SIZE);
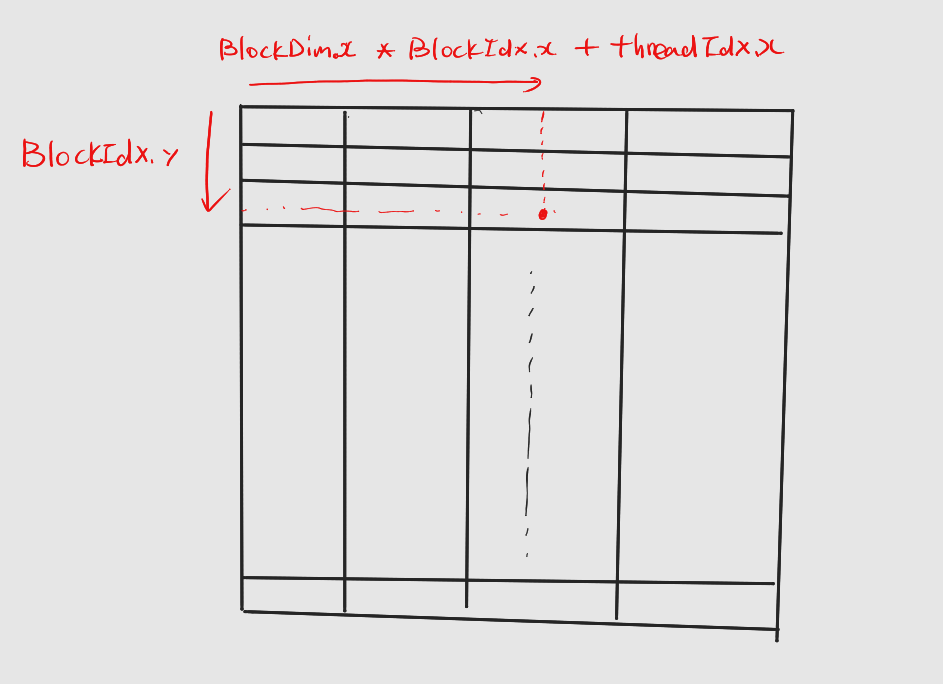
3.3 2차원 그리드, 1차원 블록 레이아웃
-
x차원 번호를 행렬의 열, y차원 번호를 행으로 매칭
: col =blockIdx.xxblockDim.x+threadIdx.x
: row =blockIdx.y
: 그림으로 설명하면 다음과 같다.
-
커널 코드 작성
__global__ void MatAdd_G2D_B1D (float* matA, float* matB, float* matC, int ROW_SIZE, int COL_SIZE) { unsigned int col = threadIdx.x + blockIdx.x * blockDim.x; unsigned int row = blckIdx.y; unsigned int index = row * COL_SIZE + col; if (col < COL_SIZE && row < ROW_SIZE) MatC[index] = MatA[index] + MatB[index]; } -
커널 호출
: 블록 크기를 (32)로 잡고 커널 호출dim3 blockDim(32) dim3 gridDim(ceil((float)COL_SIZE / blockDIm.x), ROW_SIZE); MatAdd_G2D_B1D <<<gridDim, blockDim>>> (A, B, C, ROW_SIZE, COL_SIZE);
