- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. 행렬 곱셈이란
- 학부과정에서, 혹은 독학으로 선형대수학을 배우다 보면 행렬곱을 하는 방법을 알려준다. 자료구조와 알고리즘에서는 n x n 정사각행렬의 경우, O(n^3)의 시간복잡도(3겹의 반복문)를 가진다고 배운다. 행렬곱셈은 비용이 상당한 연산인 것이다.
: 병렬 처리를 이용하면 하나의 for loop만으로 해결할 수 있다.
: 우선 행렬 곱셈의 수학적 공식은 다음과 같다.
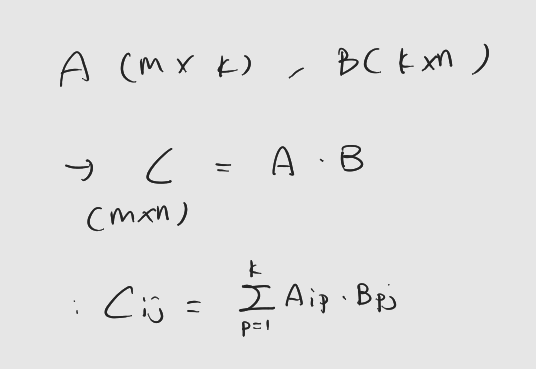
2. 스레드 레이아웃 설정
- 행렬 곱셈의 호스트 코드는 다음과 같다.
for (int r = 0 ; r < m ; r++) for (int c = 0 ; c < n ; c++) for (int i = 0 ; i < k ; i++) C[r][c] += A[r][i] + B[i][c]; - 행렬 A, B에서는 read, 행렬 C에서는 write이 반복된다. 이를 참고해서 스레드 레이아웃을 설정해보자.
2.1 입력 행력 A, B기준 스레드 레이아웃
-
A의 각 행 또는 B의 각 열을 하나의 스레드가 처리.
: 병렬처리에 참여할 수 있는 스레드의 수가 행렬 A의 행 또는 B의 열의 개수로 제한.
: 병렬 처리 정도 (degree of parallelism)이 낮아진다. -
두 입력 행렬을 동시에 고려
: 모든 for loop 의 각 반복을 하나의 스레드가 처리
: m n k개의 스레드를 사용, 대규모 병렬처리
: 하지만 행렬 C의 입장에서는 C(row, col)에 여러 개의 스레드가 동시에 접근해서 값을 갱신 -> 이상한 값이 생성되는 문제가 발생, 이를 해결하기 위해 동기화 기법을 사용하면 스레드들이 직렬화되어 병렬 처리 성능이 크게 낮아진다.
2.2 결과 행렬 C 기준 스레드 레이아웃
- 동기화 문제가 발생하는 연산은 쓰기 연산
: 쓰기 영역을 분할하여 스레드들에게 분배
: 즉, 결과 행렬 C를 기준으로 스레드 레이아웃을 잡는다
: 스레드의 수 = m * n
3. 스레드 인덱싱
3.1 행렬 C의 크기 < 1024
-
하나의 Block만 사용하는 경우,
-
row, col을 다음과 같이 정의한다.
row = threadIdx.x col = threadIdx.y -
결과 행렬 C의 index를 정의한다.
index - row * n + col -
입력 행렬 A, B에 대한 index를 정의한다.
A(row, offset) = row * k + offset B(offset, col) = col + (offset * n)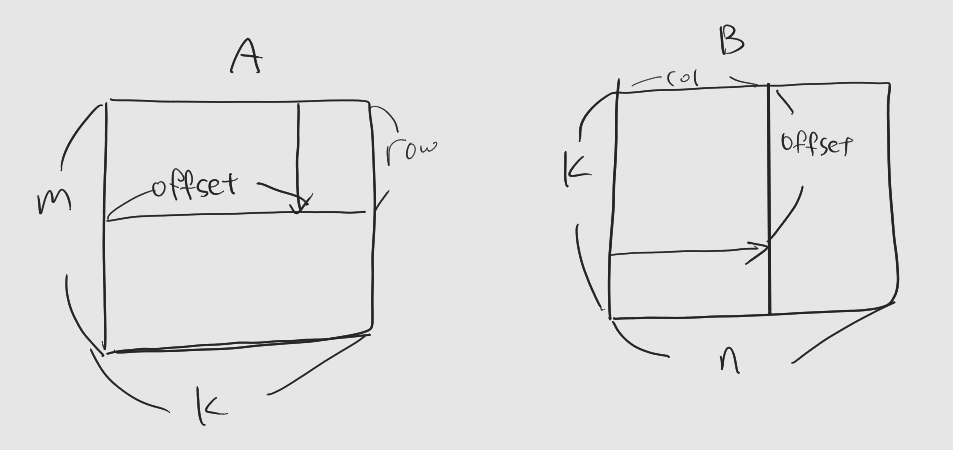
-
행렬 곱셈 커널 작성
__global__ void matMul_kernel (int* A, int* B, int* C, int m, int n, int k) { int row = threadIdx.x; int col = threadIdx.y; int index = row * n + col; C[index] = 0; for (int offset = 0; offset < k; offset++) C[index] += A[row * k + offset] * B[col + offset * n]; }
3.2 행렬 C의 크기 > 1024
-
(2차원 그리드, 2차원 블록) 레이아웃을 사용.
: 결과 행렬 C의 row, col만 잘 설정해주면 된다.row = (blockDim.x * blockIdx.x) + threadIdx.x col = (blockDim.y * blockIdx.y) + threadIdx.y -
행렬 곱셈 커널 작성
__global__ void matMul_kernel (int* A, int* B, int* C, int m, int n, int k) { int row = (blockDim.x * blockIdx.x) + threadIdx.x; int col = (blockDim.y * blockIdx.y) + threadIdx.y; int index = row * n + col; if (row >= m || col >= n) return; (에외처리) C[index] = 0; for (int offset = 0; offset < k; offset++) C[index] += A[row * k + offset] * B[col + offset * n]; }

Hardware Engineer가 되자