- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. NVIDIA GPU Architecture
- 2010년 발표한 Fermi Architecture 부터, 2020년에 발표한 Ampere Architecture, 2022년 발표된 Hopper (데이터센터 전용 GPU Microarchitecture), Ada Lovelace (RTX 40시리즈가 이 아키텍처기반으로 만들어졌다.) 까지 계속해서 발전해오고 있다.
- Fermi 아키텍처는 CUDA 관점에서 구조가 정립된 첫번째 아키텍처이다. 최신 아키텍처들과 큰 틀에서는 변하지 않았다.
: 최신 아키텍처들을 공부할 때는 NVIDIA White paper를 이용하면 좋다.
: 이 책에서는 Fermi 기반으로 공부한다.
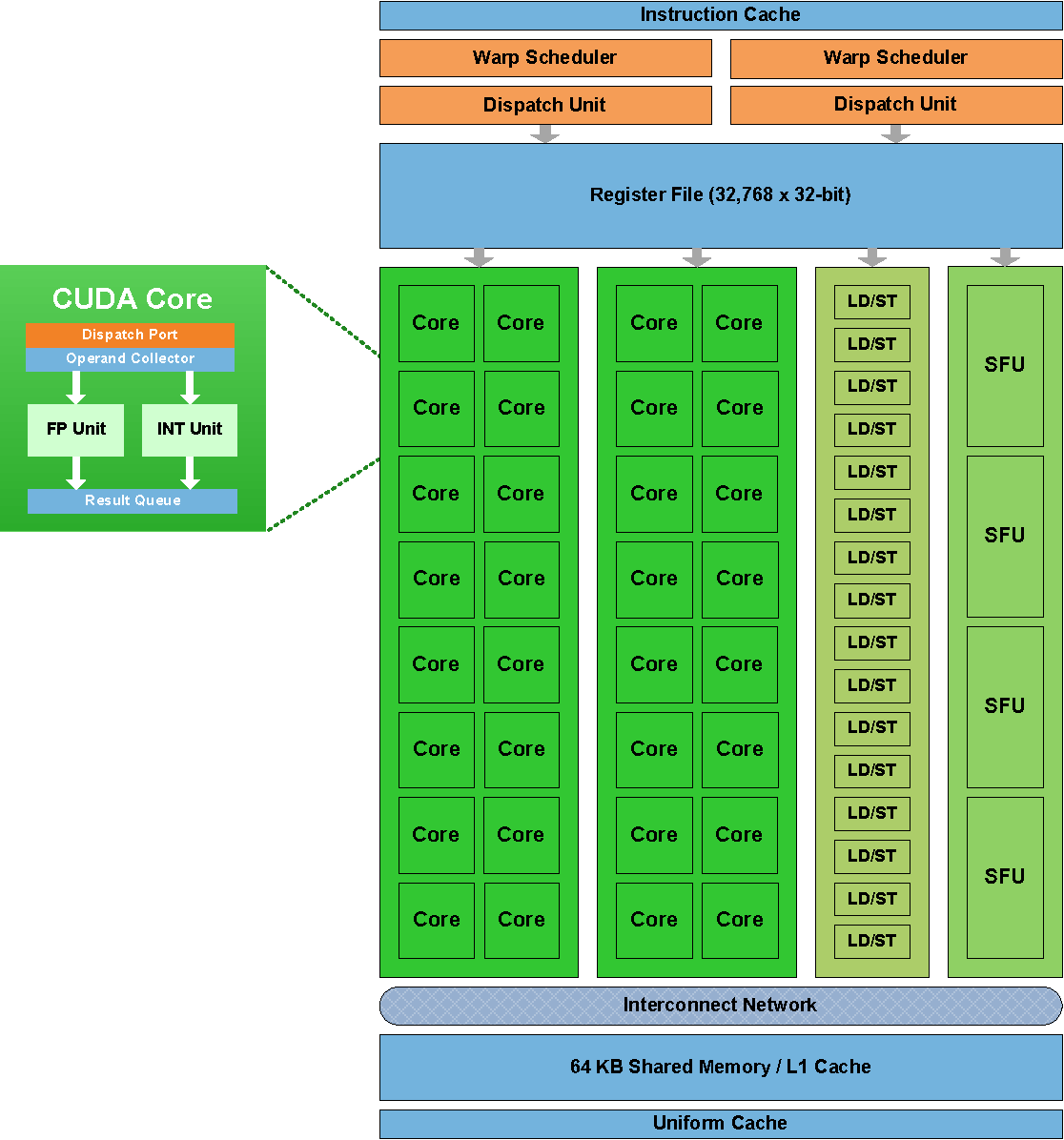
1.1 SM (Streaming Multiprocessor)
- 하나의 GPU는 여러 SM을 포함한다.
: Fermi의 경우 하나의 SM에 32개의 CUDA코어를 가지고 있다.
1.2 CUDA 코어
-
CUDA 코어는 GPU의 가장 기본적인 프로세싱 유닛이다.
: 간단히는 CUDA 코어 하나가 스레드 하나를 처리한다. 정수연산 처리 유닛과 실수 연산 (floating point 연산) 처리 유닛이 하나의 core를 이룬다. -
다음은 Fermi SM의 구조이다.
2. CUDA 스레드 계층과 GPU 하드웨어
2.1 그리드 -> GPU
- 그리드는 GPU를 사용하는 단위
: 하나의 그리드는 한 GPU에서 실행
: 하나의 GPU가 여러 그리드를 처리할 수 있다.
2.2 스레드 블록 -> SM
- 스레드 블록은 그리드가 배정된 GPU속 SM에 의해 처리
: 스레드 블록들은 SM에 순차적으로 균등하게 분배되어 처리
: 스레드 블록 할당 예시
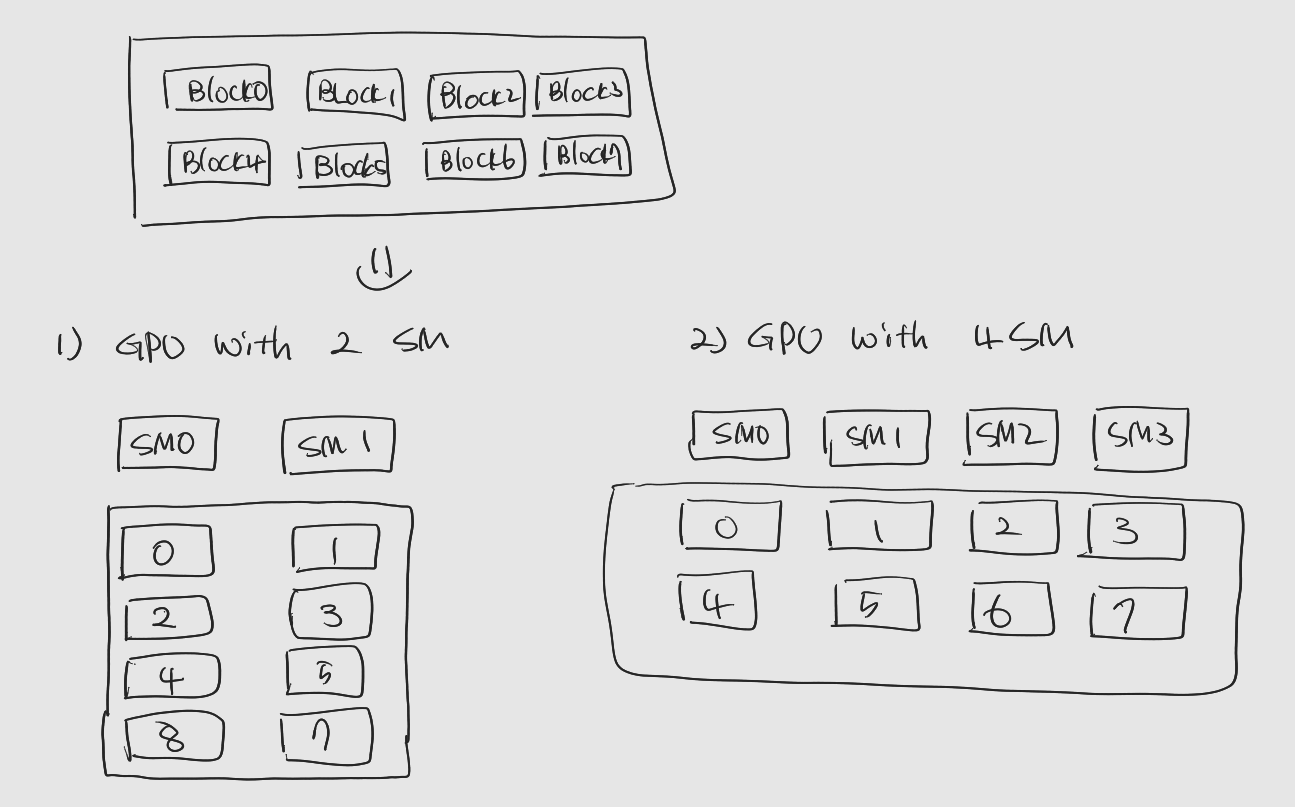
: 하나의 SM에 여러 블록이 할당될 수도 있음
; SM에 할당된 블록 중 현재 필요한 자원을 모두 할당받고 실행할 수 있는 상태인 스레드블록을 active block이라고 함.
2.3 워프 & 스레드 -> SM속의 CUDA 코어
-
스레드 블록에 포함된 스레드들은 워프로 분할, 각 스레드는 CUDA 코어 하나에서 처리
: SM내부의 CUDA 코어 개수는 대체로 32배수, 이는 워프가 32개의 스레드로 구성되어있기 때문. -
워프는 하나의 명령어에 의해 움직임
: 워프 속 스레드들은 하나의 명령어로 제어 -> SIMT
: 다음 그림을 보자
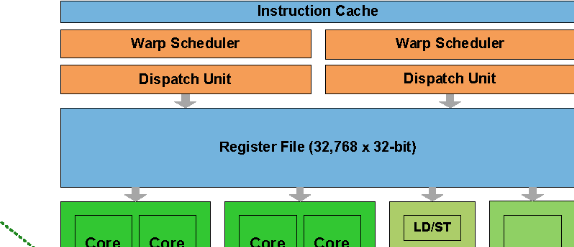
: Warp Scheduler와 Dispatch Unit들이 다음에 처리할 워프를 결정하거나 명령을 내리고, 각 CUDA코어는 명령어에 따라 스레드의 작업을 처리. -
스레드의 실행 문맥
: 각 스레드들은 독립적으로 처리 -> 각 스레드는 자신만의 실행 문맥 (execution context)를 갖는다. 실행 문맥은 작업 상태에 대한 기록.
: 실행 문맥은 레지스터로 관리
: 중요한 점은 스레드 블록 내 모든 스레드가 SM내부 레지스터 파일을 나누어서 사용.
: 예를들어, 블록 내 512개의 스레드가 있다면 레지스터 파일이 512등분되고, 스레드들이 이를 하나씩 사용. 만약 레지스터 파일 내 레지스터의 개수가 5120개라면, 각 스레드는 10개의 레지스터를 사용.
: 이는 무비용 문맥 교환과 워프 분기라는 중요한 두가지 특성 가질 수 있도록 한다.
2.4 Zero Context Switch Overhead
-
문맥 교환 (Context Switching)은 프로세스를 교체하는 과정을 말한다. 문맥 교환은 다음 과정을 거쳐서 이루어진다.
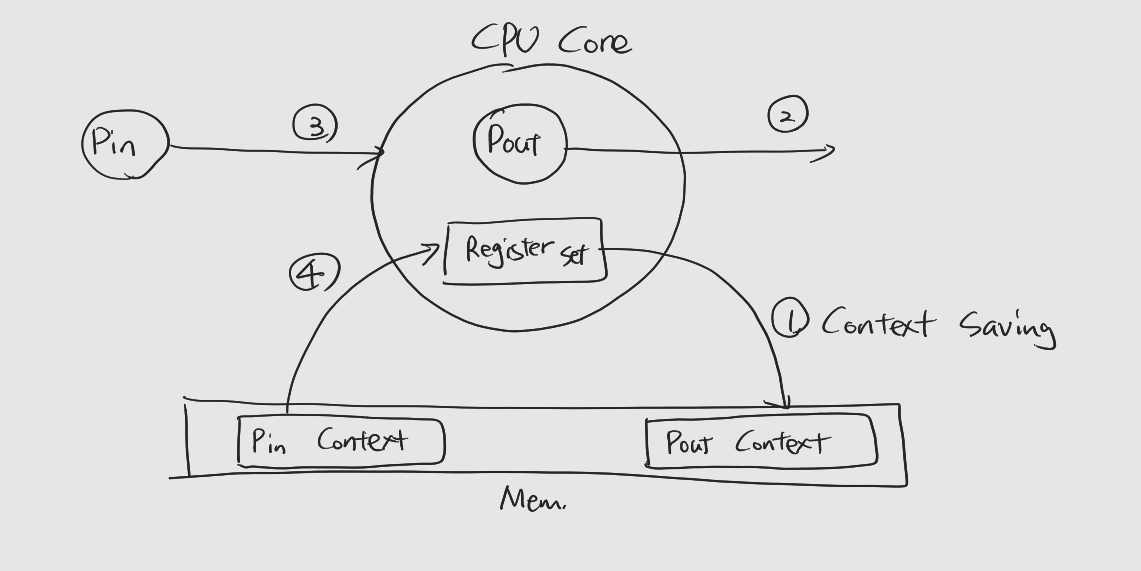
1) 교체될 프로세스 (Pout)은 문맥을 메모리에 저장 (Context Saving)
2) Pout은 나온다
3) Pin은 들어온다
4) 교체한 프로세스 (Pin)은 문맥을 메모리에서 복원 (Context Restoring) -
이렇듯 문맥 교환은 메모리에 저장하고 메모리에서 값을 읽는, 메모리 접근 과정을 거치게 되는데, 이는 많은 overhead를 요구한다.
-
하지만 스레드마다 자신만의 Context를 저장하기 위한 Register가 있다면, 문맥을 메모리에 복사하거나 메모리에서 읽어오는 작업은 불필요하다.
: Context Swithcing에 드는 Overhead가 0에 가깝다.
: 이를 무비용 문맥 교환이라고 함
: thread와 memory사이의 데이터이동에서 발생하는 latency를 숨기기 위해 많은 수의 스레드를 사용하는 전략에서 활용.
2.5 Warp Divergence (워프 분기)
-
Branch가 있는 커널에서 워프 내 스레드들이 서로 다른 길을 가야한다면...
: 한쪽 분기를 따르는 스레드들을 먼저 처리한 후 다른 분기를 따르는 분기를 이어서 처리.
: 문제는 한쪽 분기를 처리하는 동안 다른 분기의 스레드들은 아무것도 하지 않고 대기 -> 연산 자원의 낭비. -
두 가지 분기 경로가 있다면 분기가 없는 경우 대비 2배 느려진다.
: 한 워프 내에서 최악의 경우 32개의 경우가 모두 다른 분기를 수행, 이 경우 최대 32배 연산속도가 느려진다. -
CUDA 프로그램에서 분기는 성능을 크게 떨어드린다. (CPU 연산도 마찬가지이긴 하다.) 따라서 분기를 최대한 피하는 것이 중요.
3. 메모리 접근 대기 시간 숨기기 전략
-
Memory Access Latency
: 메모리 접근 작업이 끝날 때까지 연산 코어가 대기하는 시간. -
GPU는 CPU 대비 최신 메모리, 즉 높은 대역폭의 메모리를 사용
: trade off로 CPU대비 메모리 크기가 작다. -
Memory Access Latency를 감추기 위한 SW적 전략은 CUDA코어 수보다 많은 수의 스레드를 사용, 한 스레드가 메모리 대기하는 동안 다른 스레드가 CUDA코어를 사용하게끔 하는 것
: 즉 CUDA코어가 쉬지 않고 일할 수 있게 하는 것
:이런 전략이 가능한 이유는 GPU의 무비용 문맥 교환 특성 덕분
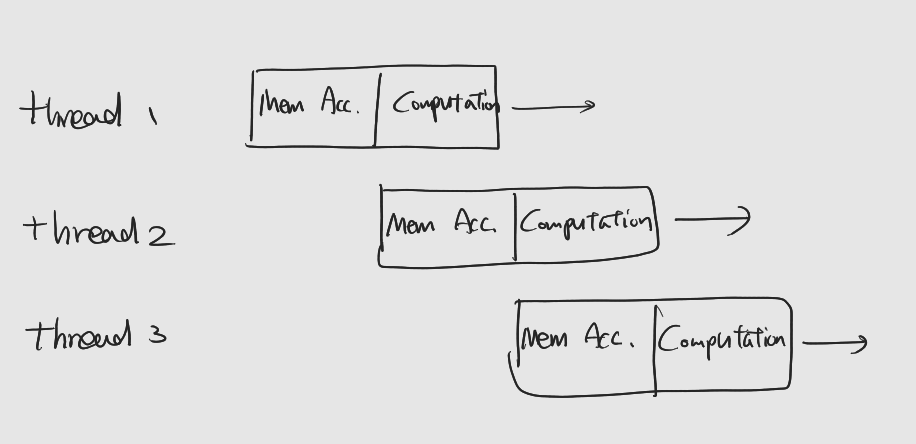
-
알고리즘에 따른 스레드의 수
: 데이터 접근이 잦은 (IO-bounded)알고리즘의 경우, 스레드의 수를 늘리는 편이 좋다.
: 반면 한번 읽은 데이터를 반복적으로 사용하거나, 복잡한 수식을 연한하는 경우 (계산 집약적, compute-bounded) 너무 많은 스레드를 사용하면 성능에 악영향.
: GPU가 갖는 CUDA 코어 수의 10배 내외를 기준으로 코드를 작성한 후 정상적으로 동작하는지 확인, 스레드 수 등을 튜닝하는 것을 추천.
4. GPU 정보 확인하기
-
cudaDeviceProp
: CUDA에서 GPU의 속성 값을 담기 위해 사용하는 구조체.
: 주요 멤버변수는 다음과 같다.char name[255] // GPU의 이름 int major // Compute capability major 버전 int minor // Compute capability minor 버전 int multiProcessorCount // GPU가 가진 SM수 int totalGlobalMem // GPU의 디바이스 메모리 크기 (byte단위) -
cudaGetDeviceProperties()
: GPU의 정보를 얻어서cudaDeviceProp구조체에 넣어주는 CUDA APIcudaError_t cudaGetDeviceProperties ( cudaDeviceProp* prop, int deviceID):
prop는 얻어온 정보를 저장
:deviceID는 정보를 얻어올 GPU 번호 -
cudaGetDeviceCount()
: 시스템 내부 GPU의 개수를 알려주는 함수cudaError_t cudaGetDeviceCount(int *count):
count는 GPU의 개수를 저장할 int형 변수의 주소.
