- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
1. 공유 메모리 사용 방법
1.1 스레드 블록 내 스레드들의 공유 데이터 보관
-
블록 내 스레드들이 공유하는 데이터 보관
: 공유 메모리에 공간 만들고, 여러 스레드들이 해당 공간에 데이터를 쓰고 읽는 형태로 구현
: 주의할 점 -> 동기화 -
여러 스레드가 동시에 데이터를 쓰거나 읽을 수 있다
: 스레드 사이의 읽고 쓰는 순서에 대한 약속을 지켜야함
: 동기화는 스레드들 사이에 순서를 맞추거나 서로 정보를 교환하는 행위.
: 블록 내 스레드들에 대한 동기화 함수는__syncthreads().
: 모든 스레드가 해당 지점에 도착할 때 까지 다른 스레드들의 진행을 막는다.
1.2 L1 Cache
- 하드웨어에게 관리를 맡기는 L1 Cache 영역으로 사용.
: 워프 내 스레드들의 메모리 접근 패턴에 따라 성능이 크게 달라질 수 있다.
: L1 Cache 활용 시, 워프 내 스레드들이 동일한 또는 인접한 데이터에 접근하도록 스레드 레이아웃 및 알고리즘 설계 -> 성능 향상 기대.
1.3 사용자 관리 캐시
- 알고리즘 특성 기반으로 데이터 접근 패턴 파악, 그에 따라 사용자가 직접 목표 데이터를 공유 메모리 영역으로 가져오거나(load), 내리면서 (write-back) 공유 메모리를 캐시처럼 사용하는 것.
2. 공유 메모리 사용 예제 - 1024 보다 작은 행렬 곱셈
: 결과행렬 C의 크기가 1024보다 작은 행렬을 다루는 커널 사용
-
어떤 데이터를 공유 메모리에 올려놓고 사용할 것인가?
: 입력 행렬 A와 B의 원소들은 각각 COL_SIZE번과 ROW_SIZE번 접근
: 반면 결과 행렬 C는 결과를 쓰기 위해 한번씩 접근.
: 즉 행렬 A와 B가 반복해서 접근하기 때문에 공유 메모리에 올리는 것이 전역 메모리 접근 횟수를 줄일 것이다. -
어떤 메모리를 올리면 좋을지 결정했다면, 공유 메모리에 올릴 수 있는 크기인지 판단.
-
행렬 곱셈 커널 - 공유 메모리 사용 예
__global__ void matMul_kernel_shared(float* _A, float* _B, float* _C)
{
int row = threadIdx.x;
int col = threadIdx.y;
int index = row * blockDim.y + col;
// 공유 메모리 영역에 공간 할당
__shared__ float sA[ROW_SIZE][K_SIZE]; // 32 * 256 * 4 bytes = 16 KB
__shared__ float sB[K_SIZE][COL_SIZE]; // 16 KB
// 전역 메모리에서 공유 메모리로 데이터 복사
// 행렬 B는 col 기준으로 데이터 복사, 각 열에서 하나의 스레드만 데이터 복사에 참여
if (row == 0) { // read matrix B
for (int k = 0; k < K_SIZE; k++)
sB[k][col] = _B[col + k * COL_SIZE];
}
// 행렬 A는 row 기준으로 데이터 복사, 각 행에서 하나의 스레드만 데이터 복사에 참여
if (col == 0 ) { // read matrix A
for (int k = 0; k < K_SIZE; k++)
sA[row][k] = _A[row * K_SIZE + k];
}
// 모든 데이터가 공유 메모리로 복사되었는지 확인
// 즉 모든 스레드가 작업완료를 했는지 확인하는 동기화 작업
__syncthreads(); // wait until all threads load the matrix
float result = 0;
for (int k = 0; k < K_SIZE; k++)
result += sA[row][k] * sB[k][col];
_C[index] = result;
}
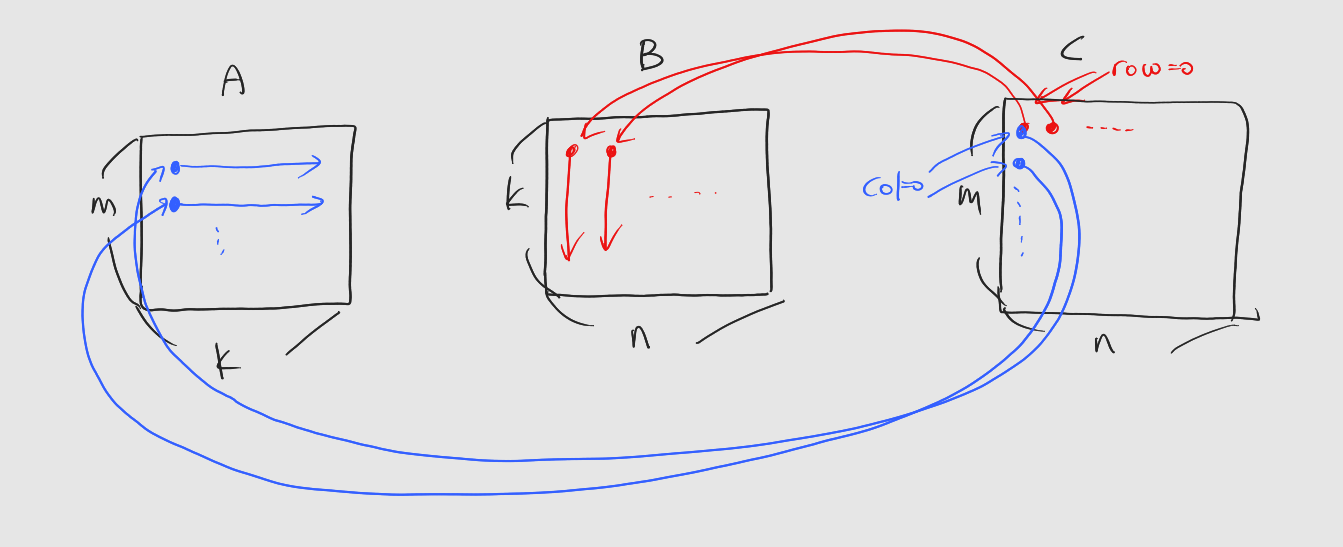
: 데이터 복사 과정을 그림으로 설명하면 다음과 같다.
: 커널의 스레드 인덱싱은 결과행렬을 기준으로 한다는 것을 기억하자.

Hardware Engineer가 되자