- 들어가기에 앞서
: 해당 게시물은 책 'CUDA 기반 GPU 병렬 처리 프로그래밍' (김덕수 지음, 비제이퍼블릭) 을 통해 CUDA 프로그래밍을 공부하면서 정리한 것이다.
0. 학습 내용
: 입력 행렬의 데이터 크기가 공유 메모리보다 큰 경우에 어떤 식으로 최적화를 진행할 지를 학습한다.
1. 문제 해결 전략
-
L1 캐시로 공유 메모리를 사용
: 하드웨어에게 공유 메모리 활용을 맡긴다.
: 이 경우 사용자 관리 캐시로 사용하는 방법만큼 성능 향상 기대하기 어렵다. -
전체 데이터가 아닌 일부 데이터만 올려가며 사용
: 어떤 데이터를 어떤 시점에 공유 메모리에 올리고 내릴지를 사용자가 결정.
2.알고리즘 설계 및 구현.
- 구현 전략
: 행과 열을 블록 단위로 분할하여 공유 메모리에 적재
: 행렬 곱셈 식을 살펴보면...
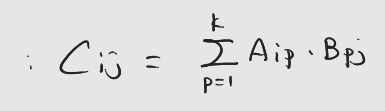
: 즉, 같은 p-번째 원소인 A(i,p)와 B(p,j) 만 특정 시점에 공유 메모리에 있으면 된다는 것.
: 만약 행과 열을 각각 3개의 데이터 블록으로 분할한다고 가정하자. 그러면 다음과 같이 계산할 수 있다.

: 공유메모리 내에 있는 각 블록은 여러번 참조된다.
- 데이터 블록의 크기
: 스레드 블록의 크기와 같게 설정하여 C_block을 위한 스레드 레이아웃을 활용.
#define BLOCK_SIZE 16 // 스레드 블록의 한 축 사이즈
...
__global__ void matMul_SharedMem (int* A, int* B, int* C, int m, int n, int k)
{
__shared__ int subA[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int subB[BLOCK_SIZE][BLOCK_SIZE];
...
}- 공유 메모리로 데이터 블록 복사
: 스레드 블록 내부 지역의 스레드 번호는 (threadIdx.x,threadIdx.y) 로 정의, 이를 각각 localRow와 localCol로 정의
int localRow = threadIdx.x;
int localCol = threadIdx.y; : 실제 읽어와야 하는 전역 메모리상의 위치를 계산 -> 현재 처리중인 데이터 블록의 번호를 bID로 정의 (0,1, ...)
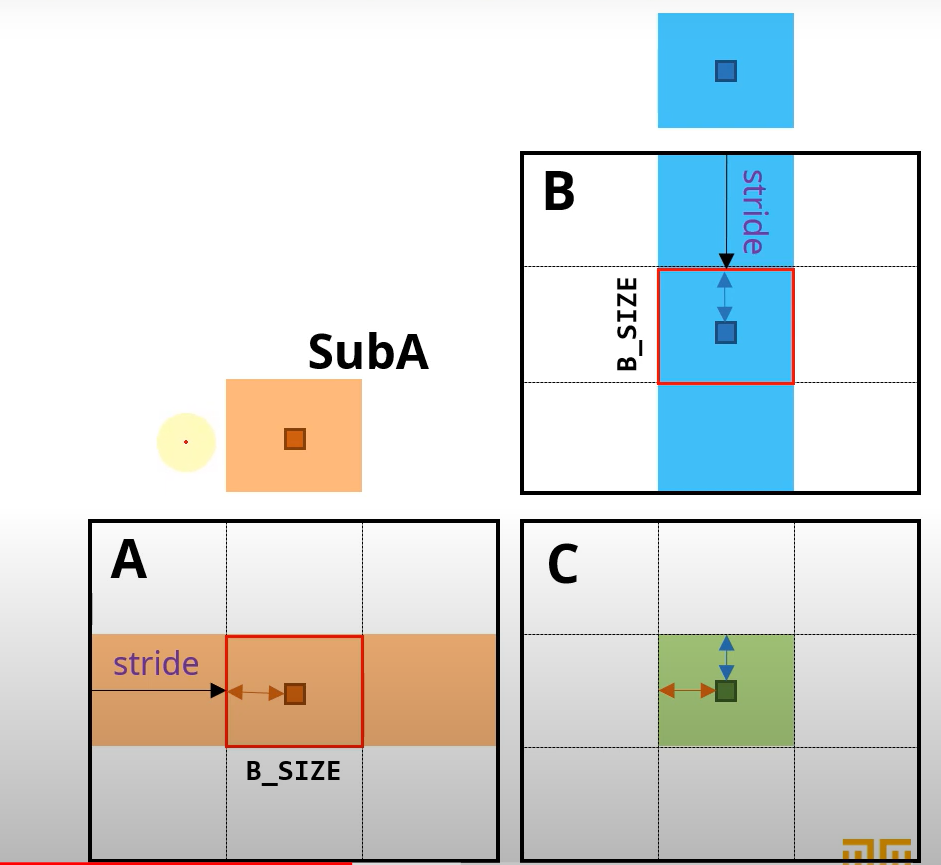
: bID * BLOCK_SIZE = stride 로 정의
SubA[localRow][localCol] = A[row*k + stride + localCol]
SubB[localRow][localCol] = B[(stride + localRow)*n + col]3. 커널 코드
__global__ void MatMul_SharedMem(DATA_TYPE* matA, DATA_TYPE* matB, int* matC, int m, int n, int k)
{
int row = blockDim.x * blockIdx.x + threadIdx.x;
int col = blockDim.y * blockIdx.y + threadIdx.y;
int val = 0;
__shared__ int subA[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int subB[BLOCK_SIZE][BLOCK_SIZE];
int localRow = threadIdx.x;
int localCol = threadIdx.y;
for (int bID = 0; bID < ceil((float)k / BLOCK_SIZE); bID++) {
int offset = bID * BLOCK_SIZE;
// load A and B
if (row >= m || offset + localCol >= k)
subA[localRow][localCol] = 0;
else
subA[localRow][localCol] = matA[row * k + (offset + localCol)];
if (col >= n || offset + localRow >= k)
subB[localRow][localCol] = 0;
else
subB[localRow][localCol] = matB[(offset + localRow) * n + col];
__syncthreads();
// compute
for (int i = 0; i < BLOCK_SIZE; i++) {
val += subA[localRow][i] * subB[i][localCol];
}
__syncthreads();
}
if (row >= m || col >= n)
return;
matC[row * n + col] = val;
}
Hardware Engineer가 되자