회귀분석
변수 간의 서로 영향을 주는지에 대해 확인하는 분석 방법이다.
확률 변수들 사이의 함수 관계를 추구하는 통계적 방법
Y = F(x)
회귀분석에서는 먼저 독립변수와 종속변수로 나누어진다.
독립변수 (예측변수, 설명변수) : 결과에 영향을 미치는 변수
종속변수 (반응변수) : 결과 값
독립변수가 1개 : 단순 회귀 모델
독립변수가 2개 : 다중 회귀 모델
종속변수가 1개 : 단 변량 회귀 모델
종속변수가 2개 : 이변량 회귀 모델
종속변수가 그 이상 : 다변량 회귀 모델
선형 회귀 분석
선형 회귀 분석이란 주어진 데이터가 이루는 하나의 선을 찾는 것
Y = a + bx
위 식에서 x는 독립변수(설명변수), y는 종속변수(반응변수) 이다.
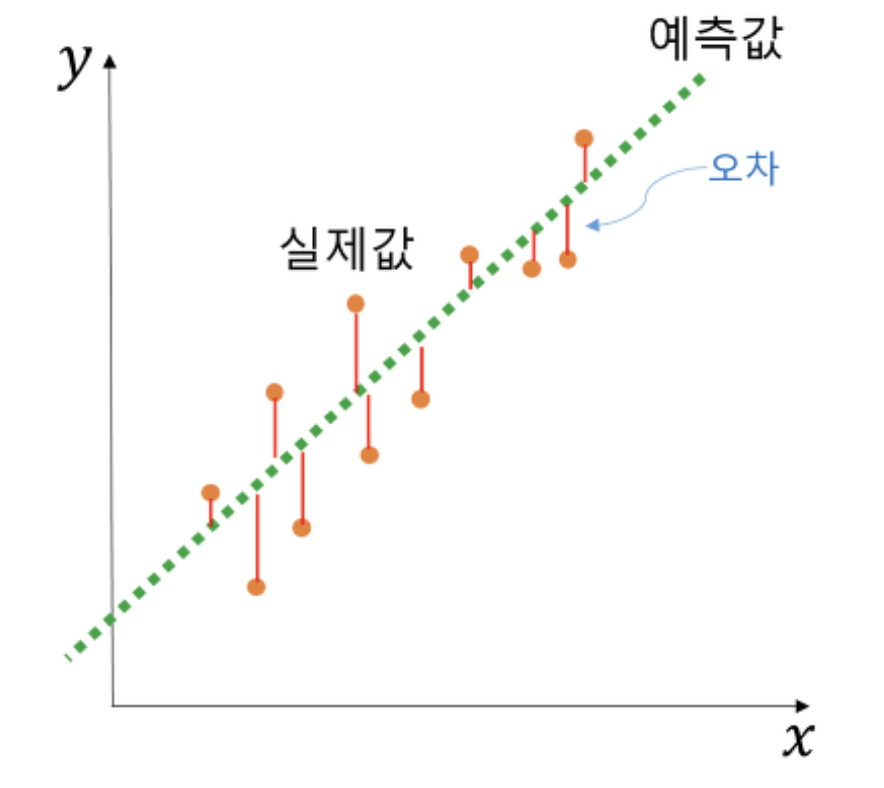
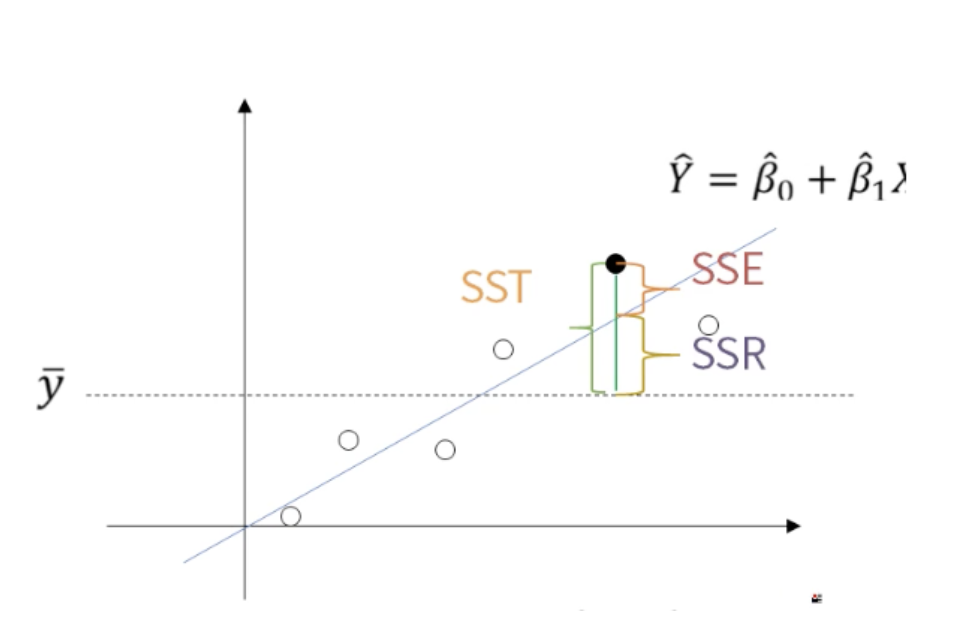
오차는 초록색 선(회귀선) 위의 값(=추정된 예측값) 과 실제값(주황색 점)들 간의 차이를 말한다.
회귀분석은 오차를 최소화하는 회귀선을 추정해 a와 b값을 찾는데, 이 방법을 최소제곱법(least squares)이라고 한다.
최소제곱법으로 회귀 계수 구하는 방법은 다음과 같다.

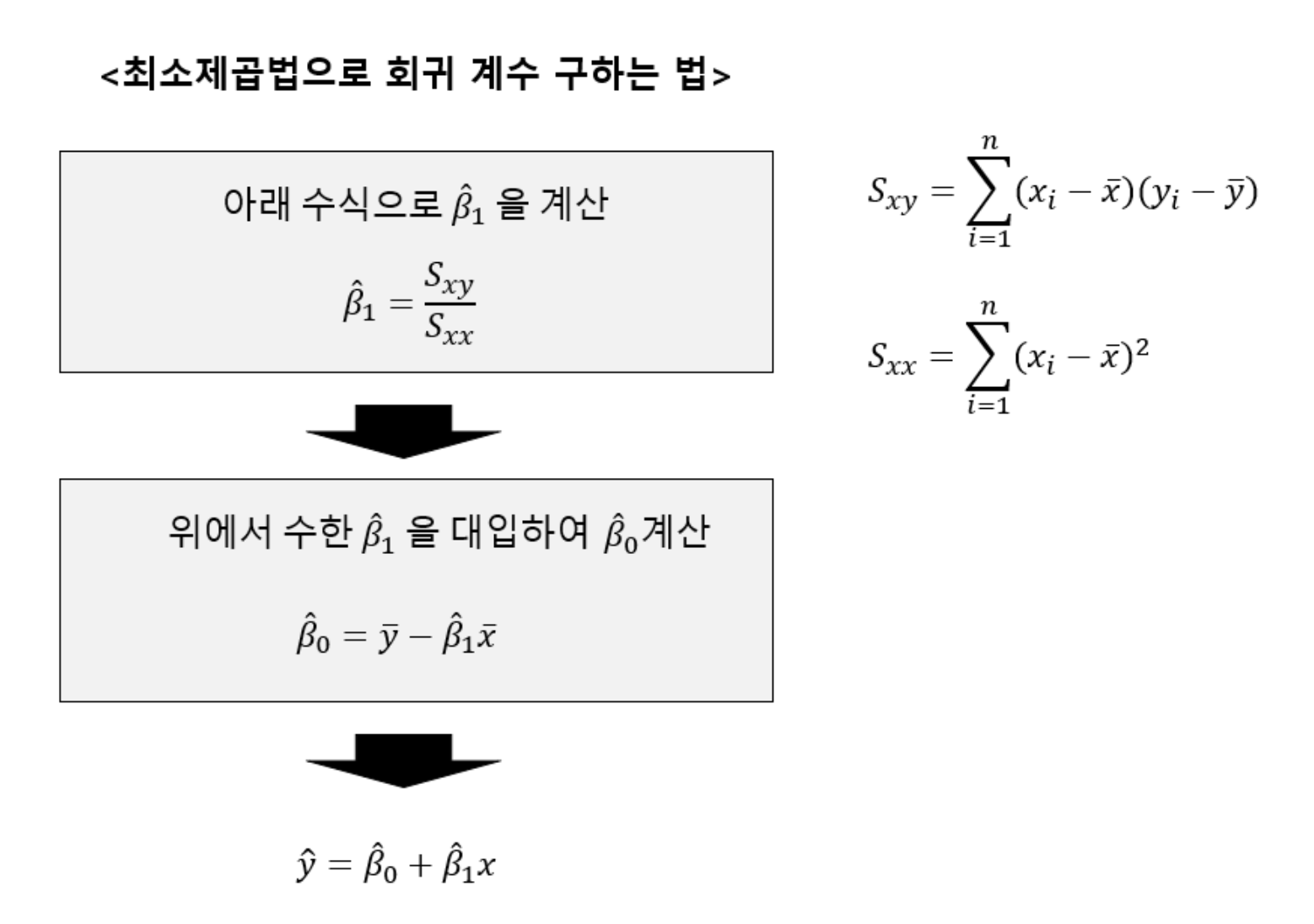
선형 회귀의 정확도 평가
선형 회귀는 잔차의 제곱합(SSE : Error sum of squares )을 최소화하는 방법으로 회귀 계수를 추정
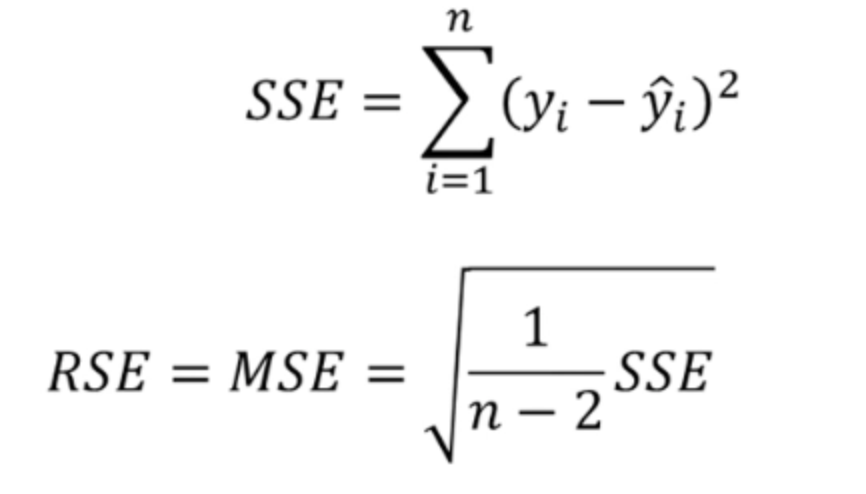
-
SST ( Total sum of squares )
SSE + SSR의 합
Y의 총 변동(SST)은 직선으로 설명 불가능한 변동 SSE와 직선으로 설명 가능한 변동 SSR로 되어있다.
전체(Total)에 대한 변동성은 SST -
SSE ( Error sum of squares )
회귀선에 위치한 값(추정 값)과 실제값의 차이(오차)의 제곱
직선으로 설명이 불가능한 변동
오차(Error)에 대한 변동성 -
SSR ( Regression sum of squares )
회귀선에 위치한 값(추정값) 과 Y의 평균을 뺀 값의 제곱
직선으로 설명이 가능한 변동
직선(Regression)에 대한 변동성
자유도 (Degree of freedom)
- 분산의 자유도는 N-1 이기 때문에 Total의 자유도와 같다.
- SSE의 자유도는 SST - SSR 이기 때문에 N-2 가 된다.
- Mean Square 은 변동성을 자유도로 나누어 준 것
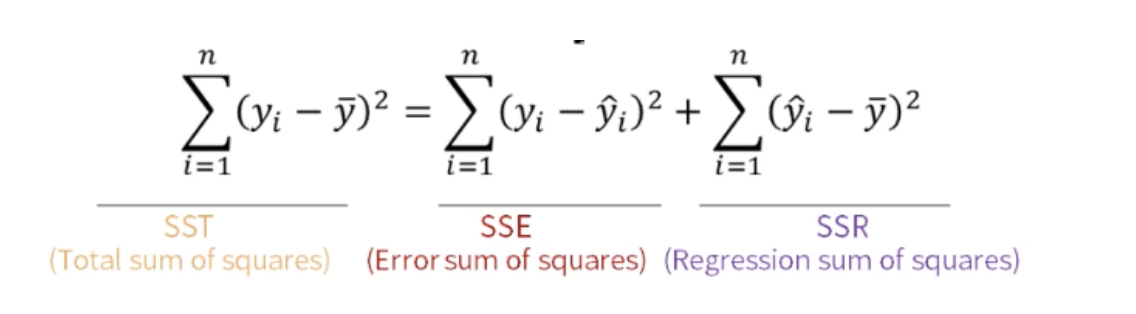
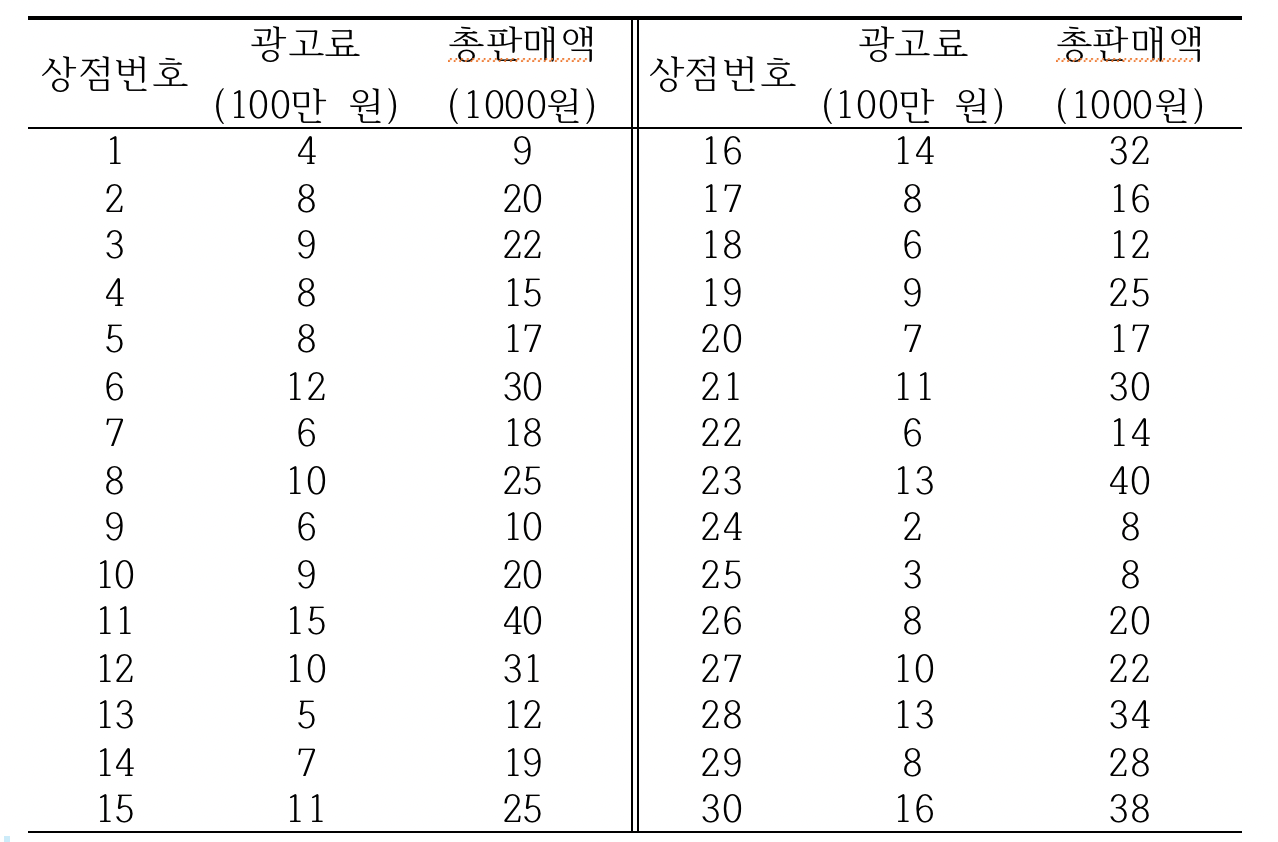
예 8.3 (단순회귀분석)
광고가 판매량에 미치는 관계를 알아보기 위하여 비슷한 여건하에 있는 많은 상점들 중에서 랜덤하게 30개의 상점을 표본으로 추출하여 이 상점들의 연간 광고료와 총판매량을 조사한 결과 다음과 같이 나타났다. 광고료와 총판매액간의 산점도를 그리고, 상관계수를 구하여 보자. 또한 5% 유의수준에서 두 변수간의 상관관계가 유의한지를 알아보자.
SAS 프로그램 (상관분석)
/* ADV.SAS : 상관분석 */
OPTIONS PS=40 LS=70; /* 출력의 크기 지정 */
DATA COR;
INPUT ADV TOTAL @@; /* 변수 읽기 */
CARD;
4 9 8 20 9 22 8 15 8 17
12 30 6 18 10 25 6 10 9 20
15 40 10 31 5 12 7 19 11 25
14 32 8 16 6 12 9 25 7 17
11 30 6 14 13 40 2 8 3 8
8 20 10 22 13 34 8 28 16 38
;
PROC PLOT DATA=COR; /* 산점도 */
PLOT TOTAL*ADV;
RUN;
PROC CORR DATA=COR; /*상관계수*/
VAR ADV;
WITH TOTAL;
RUN;출력 결과
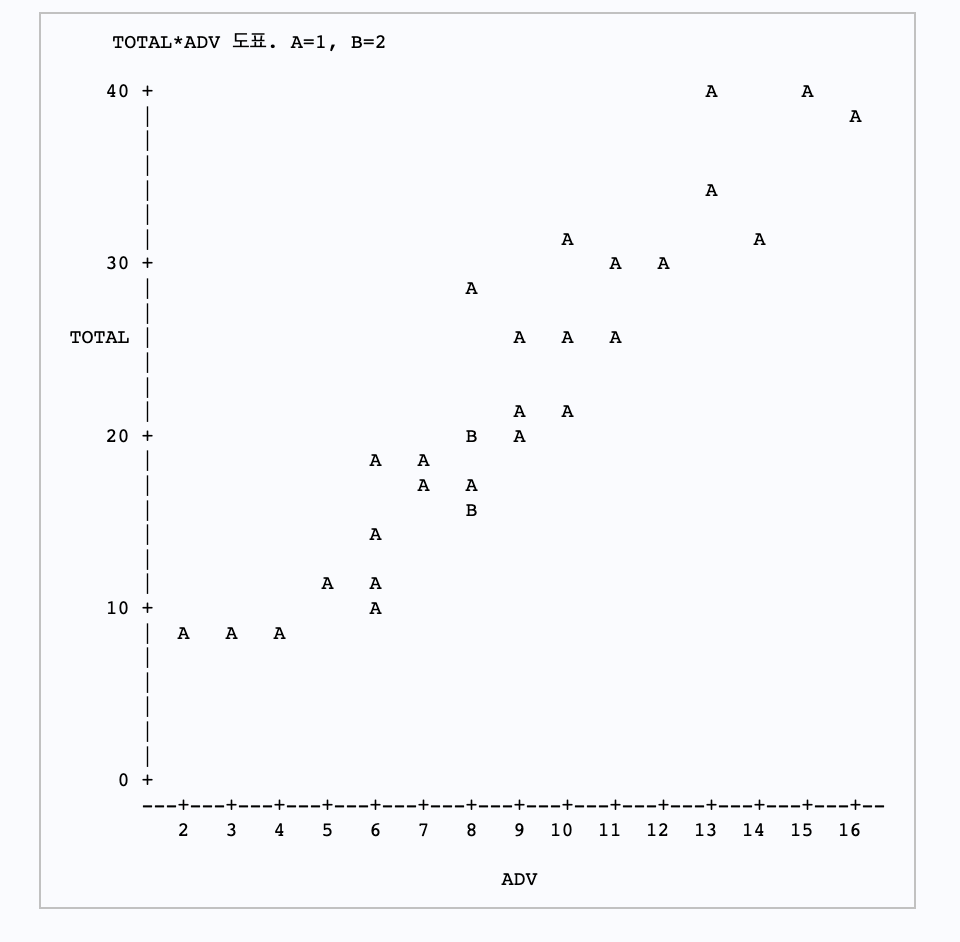
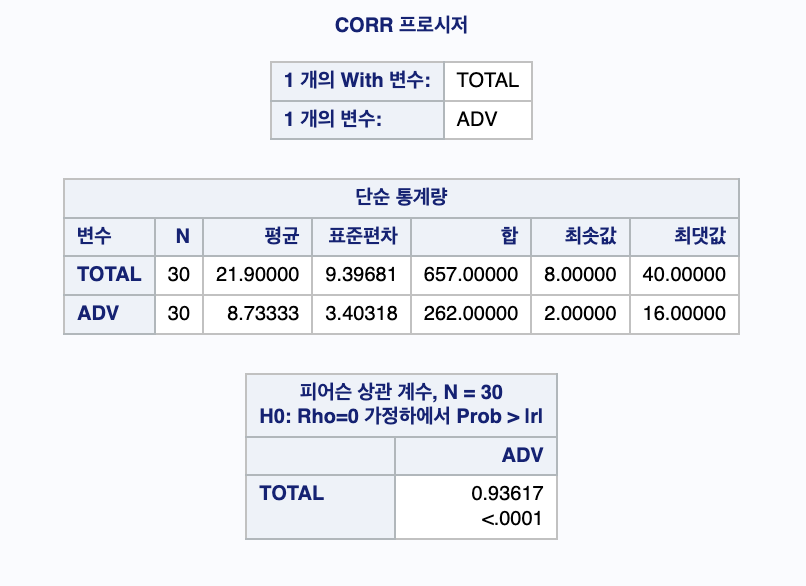
출력 결과에 의하면, 산점도에서 광고비가 많을수록 총판매액이 증가함을 알 수 있고 광고비와 총판매액간의 표본상관계수는 0.93617로서 매우 강한 상관관계가 있음을 알 수 있다. 또한 유의확률은 0.0001로 5% 유의수준에서 귀무가설을 기각하여 두 변수간에 상관관계가 매우 유의하다는 결론을 내릴수 있다.
예 8.4 (회귀분석)
예 8.3에서 사용했던 광고비와 매출액 자료를 이용하여 단순회귀분석을 실시하여 보자. 광고비에 따른 매출액의 정도가 관심사항이기 때문에 두 변수 중 매출액은 종속변수가 되고 광고비는 독립변수로 한다. 우리가 고려하는 모형은 다음과 같다.

회귀직선의 적합과 그에 따른 여러 가지 검정을 해보고, 모형의 타당성을 알아보기 위해 잔차를 검토해 보자.
SAS 프로그램
/* ADVREG.SAS : 단순회귀분석과 잔차분석 */
OPTIONS PS=40 LS=75;
DATA COR;
INPUT ADV TOTAL @@;
CARD;
4 9 8 20 9 22 8 15 8 17
12 30 6 18 10 25 6 10 9 20
15 40 10 31 5 12 7 19 11 25
14 32 8 16 6 12 9 25 7 17
11 30 6 14 13 40 2 8 3 8
8 20 10 22 13 34 8 28 16 38
;
TITLE; /* 이전에 준 타이틀을 취소 */
PROC REG DATA=COR; /* 회귀분석 */
MODEL TOTAL=ADV; /* 모형 설정 */
OUTPUT OUT=RES RESIDUAL=RED STUDENT=STRED L95M=L95 U95M=U95;
/* OUTPUT 데이터세트, 잔차 및 신뢰구간을 저장할 변수 지정 */
RUN;
PROC PRINT DATA=RES; /* 신뢰구간 및 잔차 출력 */
RUN;
PROC PLOT DATA=RES; /* 스튜던트화 잔차도 */
PLOT STRED*ADV /VREF=-2 0 2;
RUN;
QUIT; 출력 결과
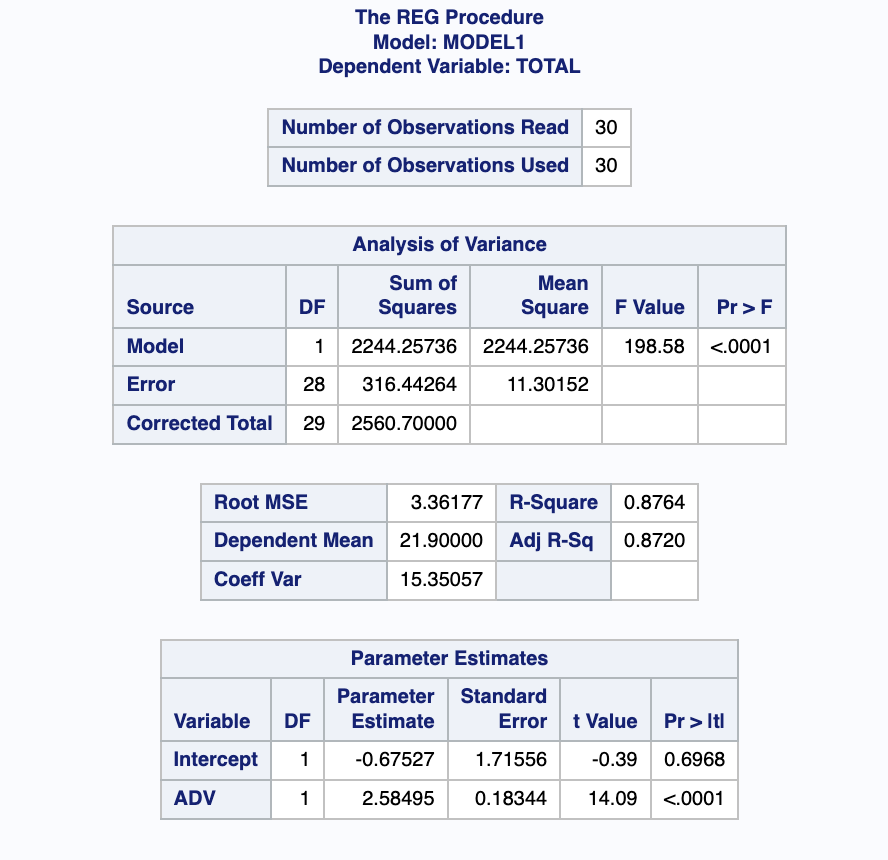
출력 결과에 의하면, 적합된 회귀직선은 y=-0.67527+2.58495x 이 된다. 결정계수는 0.8764로 총제곱합 중에서 회귀직선에 의하여 설명되는 비율이 약 88%암을 알 수 있다. 또한, 분산분석표에서 모형에 대한 유의확률이 0.0001로 모형이 매우 유의함을 알 수 있다.
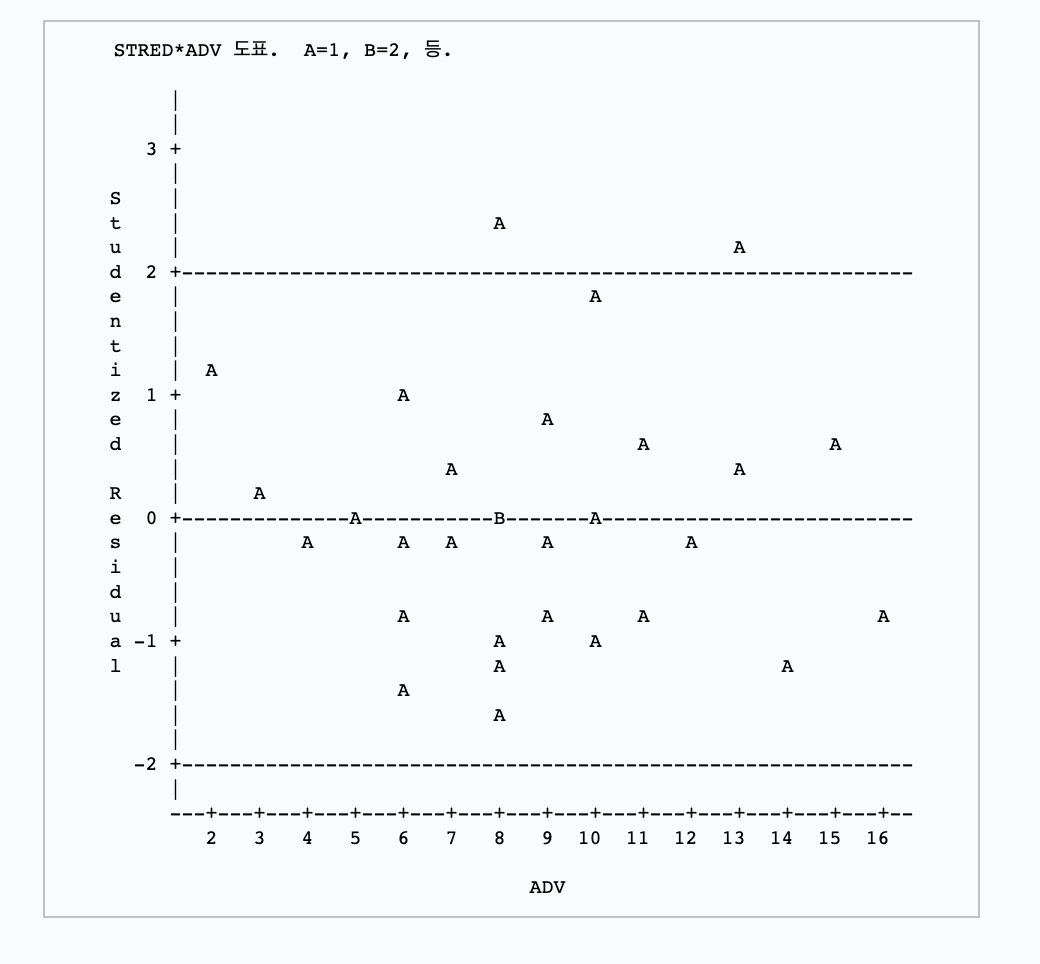
위의 그림은 광고비에 따른 스튜던트화 잔차의 산점도로서, 전체적으로 어떤 경향도 발견되지 않으며 0을 중심으로 랜덤하게 퍼져있으므로 등분산성의 가정을 만족하고 있음을 알 수 있다.
스튜던트화 잔차들 가운데 2개가 2의 범위를 벗어나고 있으며, 이들 자료의 관측과정을 재검토 할 필요가 있다. 그러나, 전체적으로 정규성 가정을 위배했다는 뚜렷한 증거를 발견할 수는 없다.
R 프로그램
adv <- read.table("/Users/jaeyeon/Desktop/데이터사이언스를 위한 통계분석/9주차_단순회귀분석1/adv.txt", header = T)
adv <- as.data.frame(adv)
plot(adv$total ~ adv$adv)
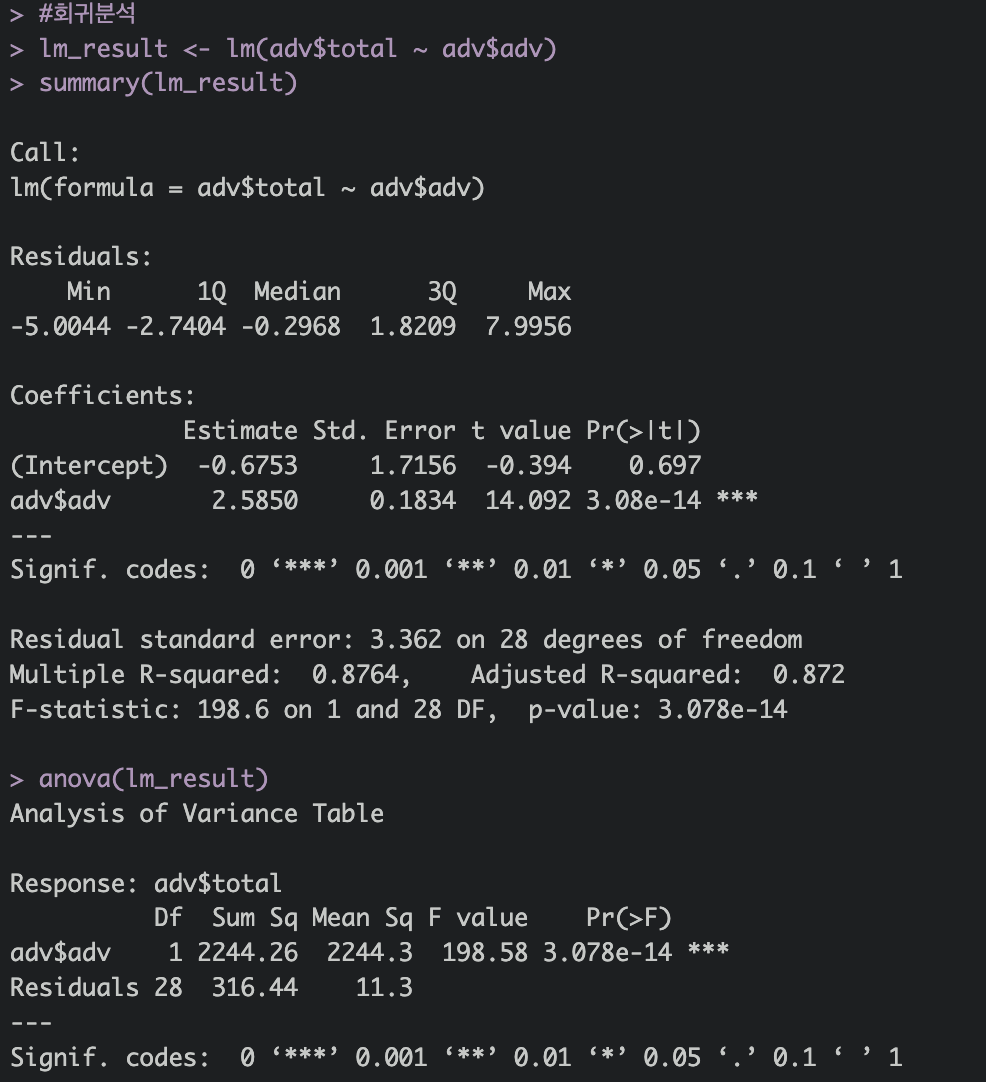
#회귀분석
lm_result <- lm(adv$total ~ adv$adv)
summary(lm_result)
anova(lm_result)
abline(a=-0.6753, b= 2.5850, col="red")
# ssr,sse,sst 직접 구하기
adv$yhat <- -0.6753 + 2.5850 * adv$adv
adv$residual <- adv$total - adv$yhat
n <- nrow(adv)
ybar <- mean(adv$total)
sse <- sum(adv$residual * adv$residual)
sse1 <- sd(adv$residual)^2 * (n-1)
ssr <- sum((adv$yhat - ybar)*(adv$yhat - ybar))
ssr1 <- sd(adv$yhat - ybar)^2 * (n-1)
sst <- ssr + sse
sst1 <- sum((adv$total - ybar)*(adv$total - ybar))
sst2 <- sd(adv$total - ybar)^2 * (n-1)
#regression coefficients, b0, b1
xbar <- mean(adv$adv)
ybar <- mean(adv$total)
adv$x_cen <- adv$adv - xbar
adv$y_cen <- adv$total - ybar
sxx <- sum(adv$x_cen * adv$x_cen)
sxy <- sum(adv$x_cen * adv$y_cen)
syy <- sum(adv$y_cen * adv$y_cen)
b1 <- sxy/sxx
b0 <- ybar - b1 * xbar
adv$yhat <- b0 + b1*adv$adv
adv$resid <- adv$total -adv$yhat
points(adv$adv,adv$yhat, pch =2,col="blue",bg="red")
plot(adv$resid ~ adv$adv)
출력 결과
예 8.5 (다중회귀분석)
밀가루의 수분흡수율과 여러 가지 특성과의 관계를 알아보고자 하는 실험이 있다. 아래 표는 밀가루의 수분흡수율(y: 단위 %), 밀단백질의 함유율(x1: 단위 %)과 끈적거림의 정도(x2: 단위 Farrand)를 나타낸 자료이다. 밀단백질의 함유율과 끈적거림의 정도가 수분흡수율에 끼치는 영향을 다중회귀분석으로 알아보자.
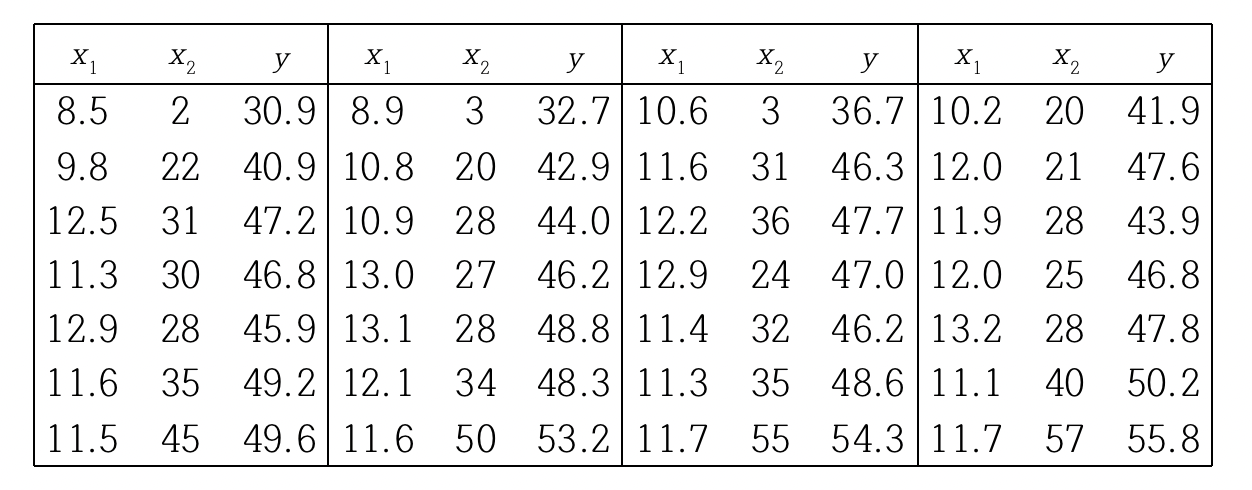
종속변수는 수분흡수율이고 독립변수는 밀단백질의 함유율과 끈적거림의 정도이다. 이 예의 모형은 다음과 같다.
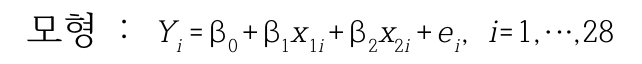
SAS 프로그램
/* PROTEIN.SAS : 다중회귀분석의 예 */
OPTIONS PS=30 LS=70; /* 출력의 크기 지정 */
DATA MULTI;
INPUT PROTEIN STARCH ABSOR @@; /* 변수 읽기 */
CARDS;
8.5 2 30.9 8.9 3 32.7 10.6 3 36.7 10.2 20 41.9
9.8 22 40.9 10.8 20 42.9 11.6 31 46.3 12.0 21 47.6
12.5 31 47.2 10.9 28 44.0 12.2 36 47.7 11.9 28 43.9
11.3 30 46.8 13.0 27 46.2 12.9 24 47.0 12.0 25 46.8
12.9 28 45.9 13.1 28 48.8 11.4 32 46.2 13.2 28 47.8
11.6 35 49.2 12.1 34 48.3 11.3 35 48.6 11.1 40 50.2
11.5 45 49.6 11.6 50 53.2 11.7 55 54.3 11.7 57 55.8
;
PROC PLOT DATA=MULTI; /* 산점도 */
PLOT ABSOR*PROTEIN;
PLOT ABSOR*STARCH;
RUN;
PROC REG DATA=MULTI; /* 회귀분석 */
MODEL ABSOR=PROTEIN STARCH; /* 모형설정 */
OUTPUT OUT=RES PREDICTED=PRED STUDENT=STRED;
/* output 데이터 세트 및 저장할 변수 지정 */
RUN;
PROC PLOT DATA=RES; /* 스튜던트화 잔차도 */
PLOT STRED*PRED /VREF=-2 0 2;
RUN;
QUIT;출력 결과
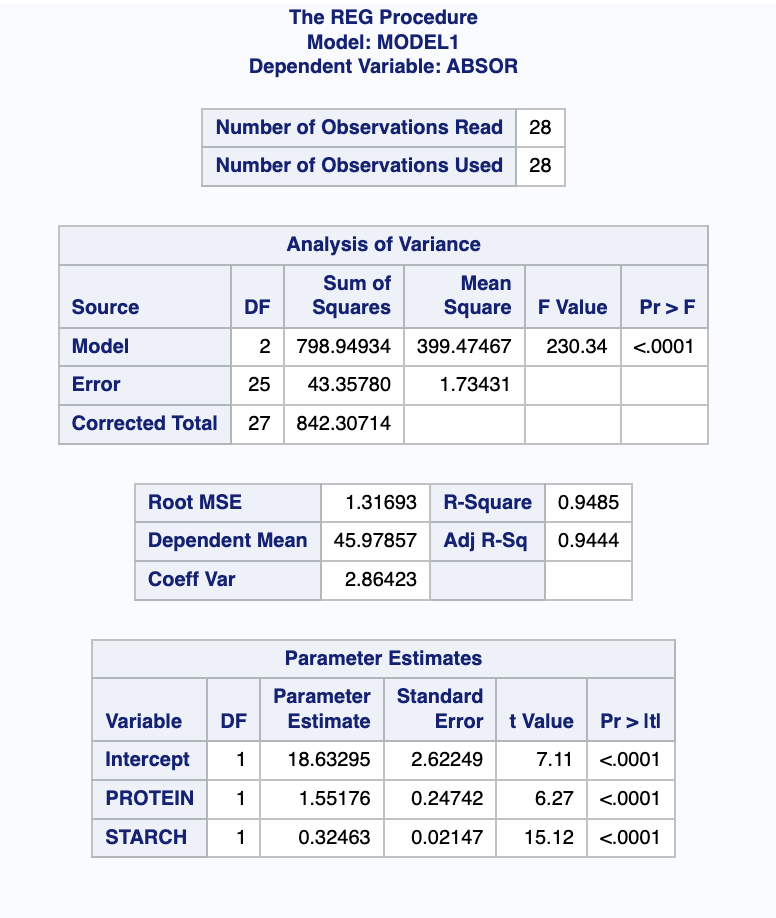
정된 회귀식은 y = 19.440 + 1.442x1 + 0.336x2이 됨을 알 수 있다.결정계수는 0.9645로 종속변수의 총변동 중에서 회귀직선에 의해 설명되는 비율이 약 96%임을 알 수 있다. 또한 분산분석표에서 모형과 각 변수에 대한 유의확률이 0.0001로 모형과 변수들이 매우 유의함을 알 수 있다.
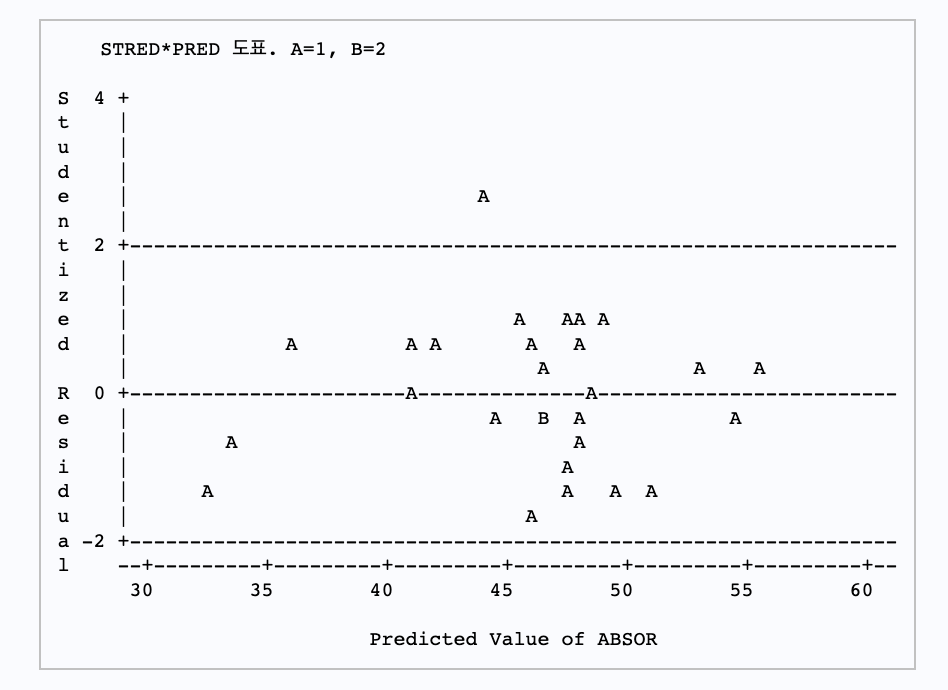
추측값(예측값)에 따른 스튜던트화 잔차도를 살펴보면, 전체적으로 어떤 경향도 발견되지 않으며 0을 중심으로 랜덤하게 퍼져있음을 알 수 있으므로 등분산성의 가정을 만족시키고 있음을 알 수 있다. 또 스튜던트화 잔차들이 모두 ±2의 범위내에 있으며 대체로 정규성 가정을 만족시킨다고 할 수 있다.
R 프로그램
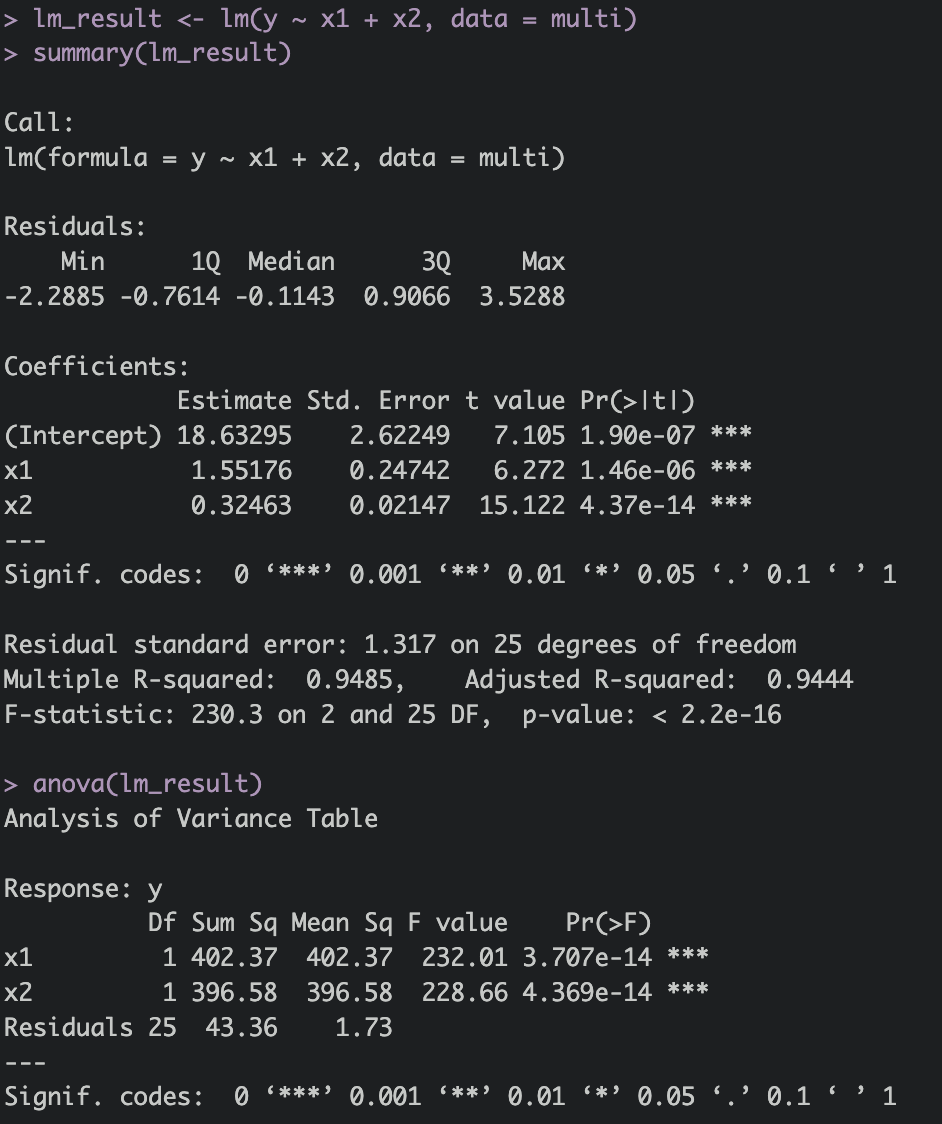
multi <- read.csv("/Users/jaeyeon/Desktop/데이터사이언스를 위한 통계분석/14주차_다중회귀분석2/multi.csv", header = T)
lm_result <- lm(y ~ x1 + x2, data = multi)
summary(lm_result)
anova(lm_result)
y <- multi[,3]
y <- as.matrix(y)
x <- multi[,-3]
x <- cbind(1,x)
x <- as.matrix(x)
b <- solve(t(x) %*% x) %*% t(x) %*% y
p <- x %*% solve(t(x) %*% x) %*% t(x)
yhat1 <- x %*% b
yhat2 <- p %*% y
check1 <- (yhat1 -yhat2)
error <- y - yhat1
sse1 <- t(error) %*% error
sse2 <- sum(error*error)
check2 <- (sse1 -sse2)출력 결과