변수선택법
- 전진선택법 (Forward Selection)
절편만 있는 상수모형으로부터 시작해 중요하다고 생각되는 설명변수부터 차례대로 모형에 추가
forward.aic = step(lm.mini, scope = list(lower ~ 1,
upper = ~ x1 + x2 + x3 + x4 + x5 + x6),
direction="forward")
- 후진제거법 (Backward Elimination)
모든 독립변수를 포함한 모형에서 출발해 가장 작은 영향을 주는 변수부터 하나씩 제거하면서 더 이상 제거할 변수가 없을 때까지 진행
y~1 : 상수항까지, 설명력이 없는 애들부터 없앰
backward.aic = step(lm.full, y~1, direction="backward")
- 단계선택법 (Stepwise Method)
전진선택법에 의해 변수를 추가하면서 새롭게 추가된 변수에 기반하여, 기존 변수의 중요도가 약화되면 해당 변수를 제거하며, 단계별로 추가 또는 제거되는 변수의 여부를 검토하여 진행
stepwise.aic = step(lm.mini, scope = list(lower ~ 1,
upper = ~ x1 + x2 + x3 + x4 + x5 + x6),
direction="both")
Example
Discription of Variables
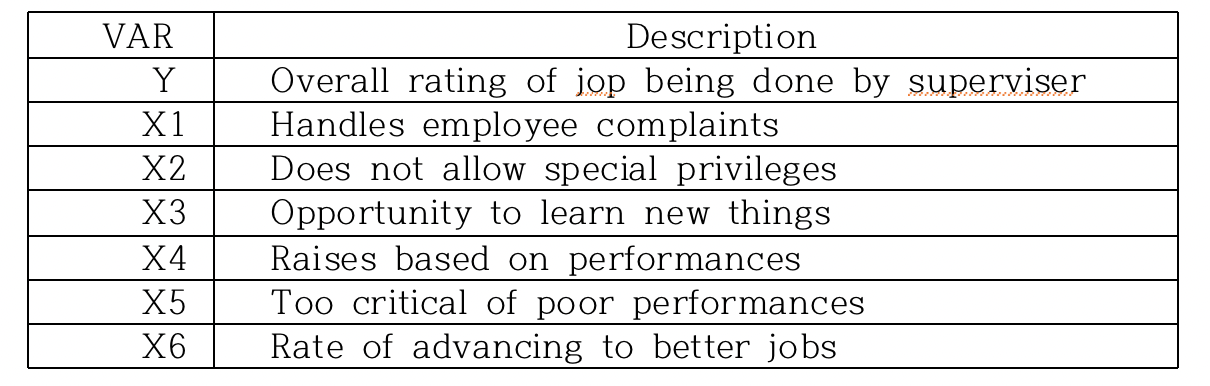
반응변수: Y ; 피고용인들이 고용인에게 갖는 만족도
설명변수:
(1) X1,X2,X5 ; 고용인과 피고용인 간의 관계 변수.
(2) X3,X4 ; 개개인의 성격보다는 전체적으로 업무에 관련된 변수.
(3) X6 ; 고용인과 직접적으로 관련은 없지만 피고용인 자체에 관련된 변수.
각 항목에 대해 만족하는 정도에 따라 1점에서 5점을 부여하였다.
SAS 프로그램
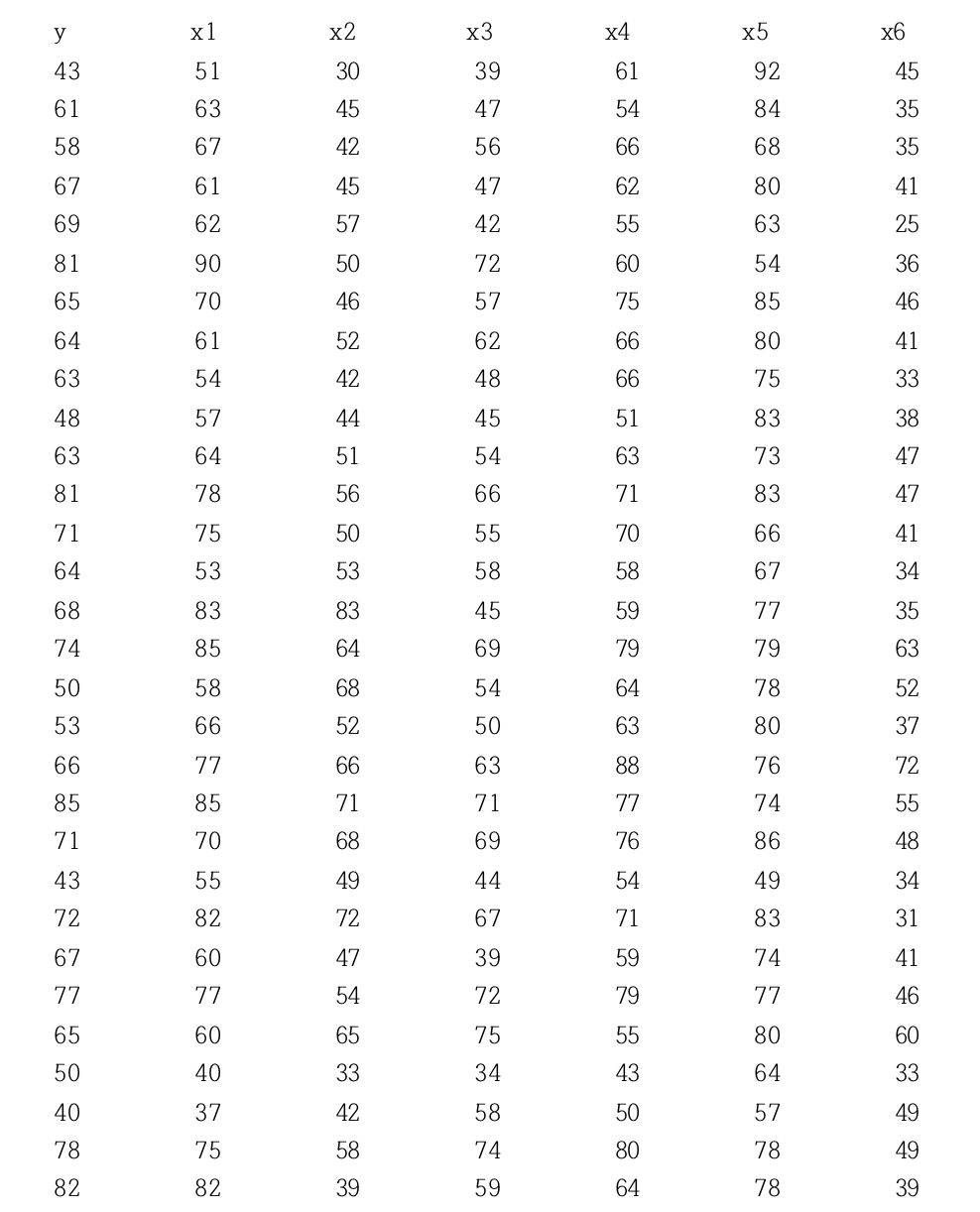
DATA survey;
INPUT y x1 x2 x3 x4 x5 x6 @@;
CARDS;
43 51 30 39 61 92 45 63 64 51 54 63 73 47 71 70 68 69 76 86 48
61 63 45 47 54 84 35 81 78 56 66 71 83 47 43 55 49 44 54 49 34
58 67 42 56 66 68 35 71 75 50 55 70 66 41 72 82 72 67 71 83 31
67 61 45 47 62 80 41 64 53 53 58 58 67 34 67 60 47 39 59 74 41
69 62 57 42 55 63 25 68 83 83 45 59 77 35 77 77 54 72 79 77 46
81 90 50 72 60 54 36 74 85 64 69 79 79 63 65 60 65 75 55 80 60
65 70 46 57 75 85 46 50 58 68 54 64 78 52 50 40 33 34 43 64 33
64 61 52 62 66 80 41 53 66 52 50 63 80 37 40 37 42 58 50 57 49
63 54 42 48 66 75 33 66 77 66 63 88 76 72 78 75 58 74 80 78 49
48 57 44 45 51 83 38 85 85 71 71 77 74 55 82 82 39 59 64 78 39
;
RUN;
/* Full Model */
PROC REG DATA=survey;
MODEL y=x1 x2 x3 x4 x5 x6;
PLOT student.*p. student.*x1 student.*x2 student.*x3
student.*x4 student.*x5 student.*x6; run;
/* Reduced Model */
PROC REG DATA=survey;
MODEL y=x1 x3;
PLOT student.*p. student.*x1 student.*x3;
RUN;
quit ;
PROC REG DATA=survey OUTEST=outsurvey ;
* MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=STEPWISE ;
MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=FORWARD;
MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=BACKWARD ;
MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=STEPWISE;
* MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=FORWARD SLE=0.6;
* MODEL y=x1 x2 x3 x4 x5 x6 /CP SELECTION=ADJRSQ RSQUARE CP AIC BIC ;
/*
MODEL y=x1 x2 x3 x4 x5 x6 /CP SELECTION=CP;
MODEL y=x1 x2 x3 x4 x5 x6 /CP SELECTION=RSQUARE;
MODEL y=x1 x2 x3 x4 x5 x6 /CP SELECTION=ADJRSQ RSQUARE CP AIC BIC ;
MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=BACKWARD SLS=0.3;
MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=FORWARD;
MODEL y=x1 x2 x3 x4 x5 x6 /SELECTION=FORWARD SLE=0.6;
*/
/*SLE : sets criterion for entry into model, significance level for the FORWARD and STEPWISE methods, The defaults are 0.50 for FORWARD and 0.15 for STEPWISE*/
/*SLS : sets criterion for staying in model,significance level for the BACKWARD and STEPWISE methods, The defaults are 0.10 for BACKWARD and 0.15 for STEPWISE*/
RUN; QUIT;
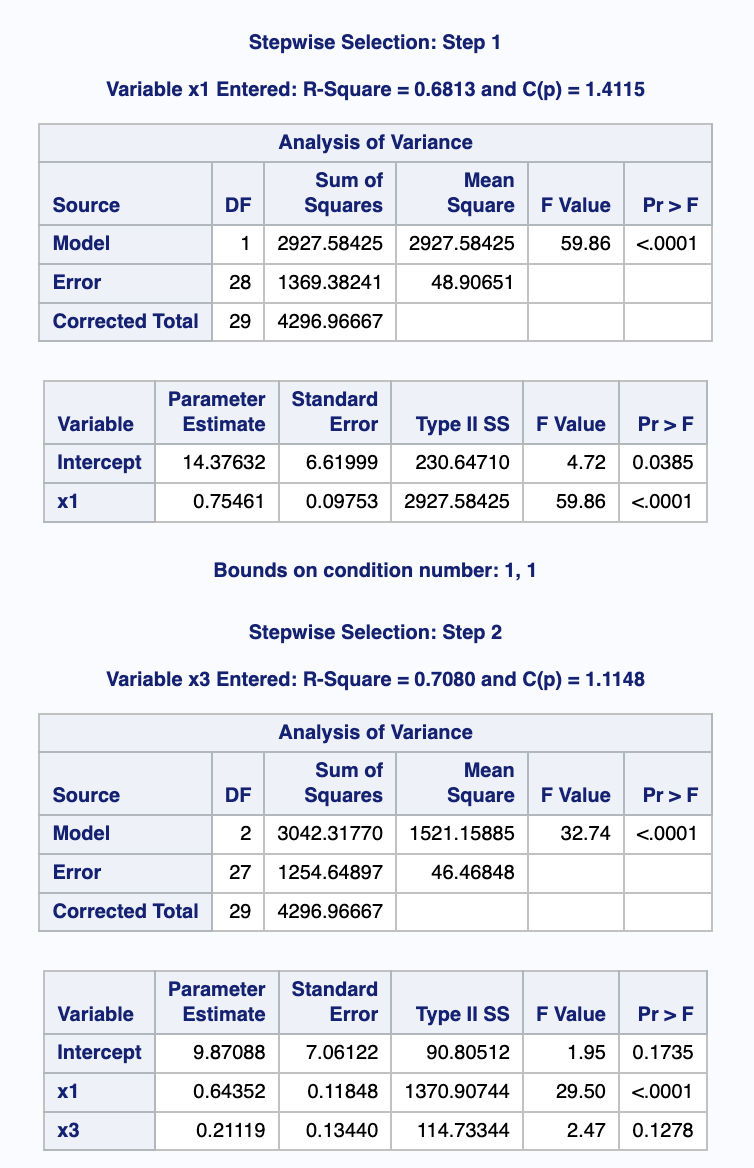
출력 결과
Forward
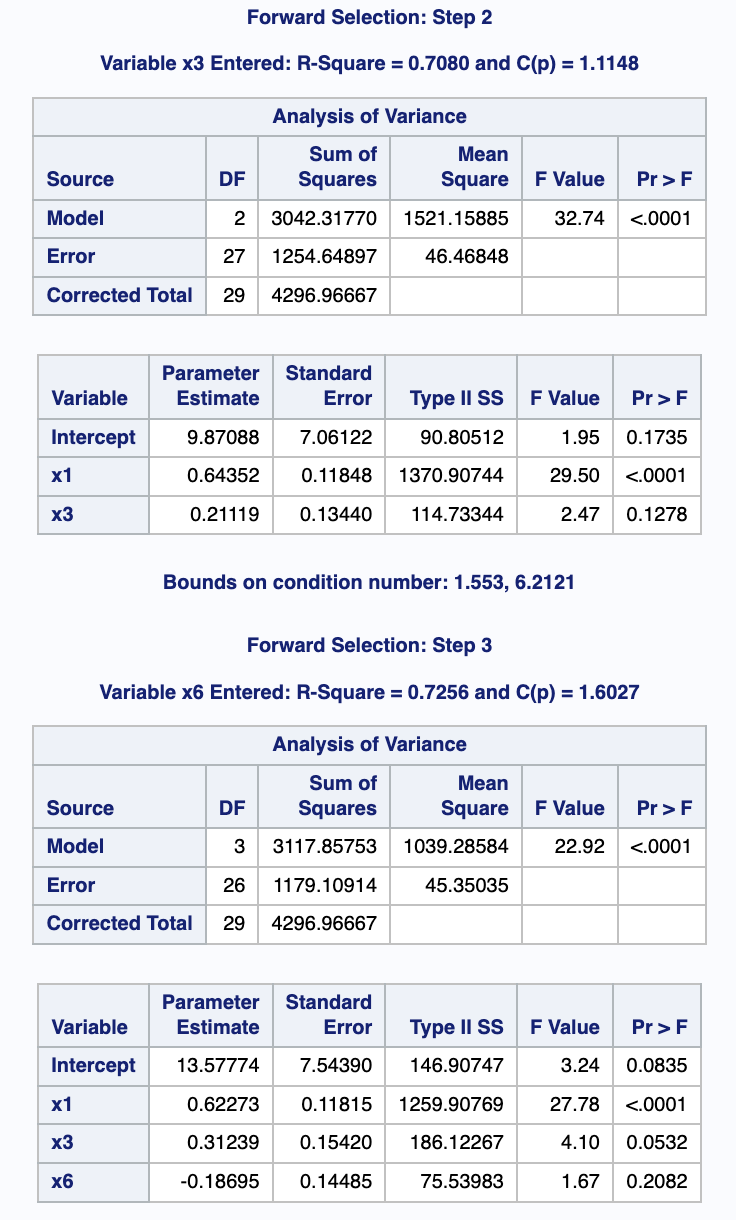
Backward
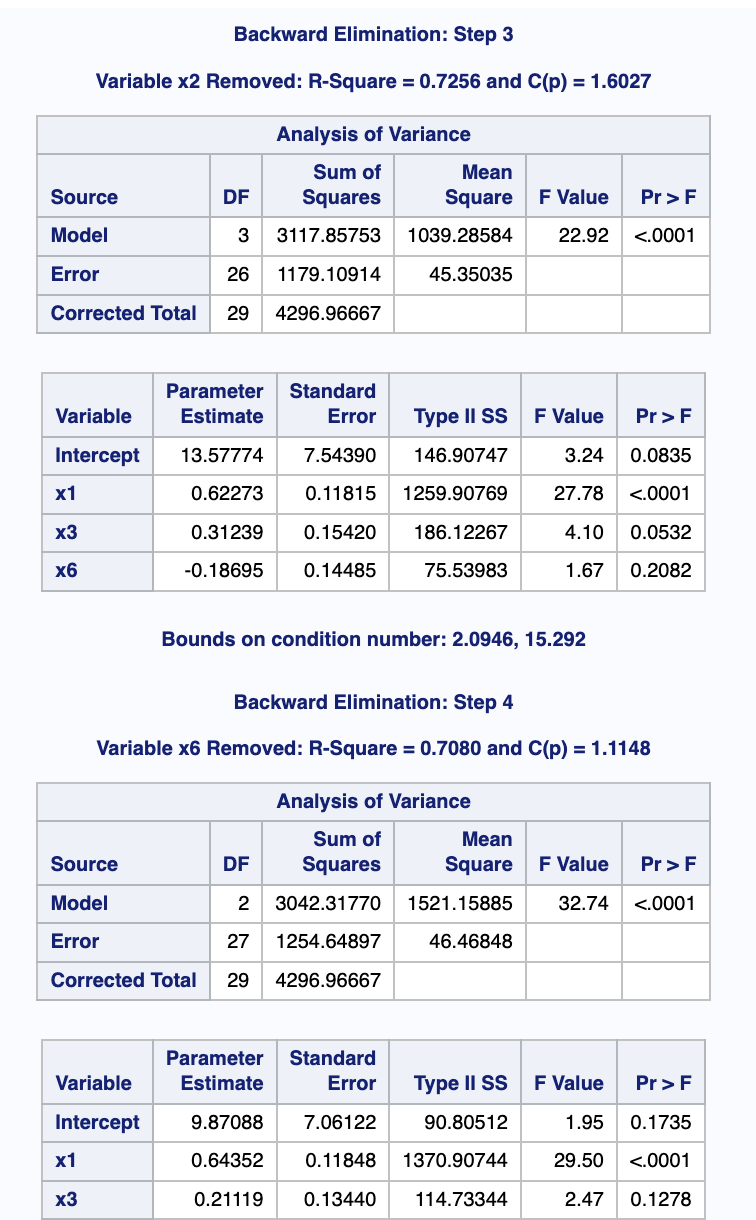
Stepwise
R 프로그램
survey <- read.table("/Users/jaeyeon/Desktop/데이터사이언스를 위한 통계분석/STUDY_R/supervisor_performance.csv",sep=',',header=T)
lm.full <- lm(y ~ . , data = survey)
summary(lm.full)
anova(lm.full)
#y~1 : 상수항까지, 설명력이 없는 애들부터 없앰
backward.aic = step(lm.full, y~1, direction="backward")
summary(backward.aic)
lm.mini <- lm(y ~ 1 , data = survey)
forward.aic = step(lm.mini, scope = list(lower ~ 1,
upper = ~ x1 + x2 + x3 + x4 + x5 + x6),
direction="forward")
summary(forward.aic)
lm.mini <- lm(y ~ 1 , data = survey)
stepwise.aic = step(lm.mini, scope = list(lower ~ 1,
upper = ~ x1 + x2 + x3 + x4 + x5 + x6),
direction="both")
summary(stepwise.aic)
출력 결과
Forward
> forward.aic = step(lm.mini, scope = list(lower ~ 1,
+ upper = ~ x1 + x2 + x3 + x4 + x5 + x6),
+ direction="forward")
Start: AIC=150.93
y ~ 1
Df Sum of Sq RSS AIC
+ x1 1 2927.58 1369.4 118.63
+ x3 1 1671.41 2625.6 138.16
+ x4 1 1496.48 2800.5 140.09
+ x2 1 780.22 3516.7 146.92
<none> 4297.0 150.93
+ x5 1 105.16 4191.8 152.19
+ x6 1 103.35 4193.6 152.20
Step: AIC=118.63
y ~ x1
Df Sum of Sq RSS AIC
+ x3 1 114.733 1254.7 118.00
<none> 1369.4 118.63
+ x4 1 11.102 1358.3 120.38
+ x2 1 7.519 1361.9 120.46
+ x6 1 4.151 1365.2 120.54
+ x5 1 0.010 1369.4 120.63
Step: AIC=118
y ~ x1 + x3
Df Sum of Sq RSS AIC
<none> 1254.7 118.00
+ x6 1 75.540 1179.1 118.14
+ x2 1 30.033 1224.6 119.28
+ x4 1 1.188 1253.5 119.97
+ x5 1 0.002 1254.7 120.00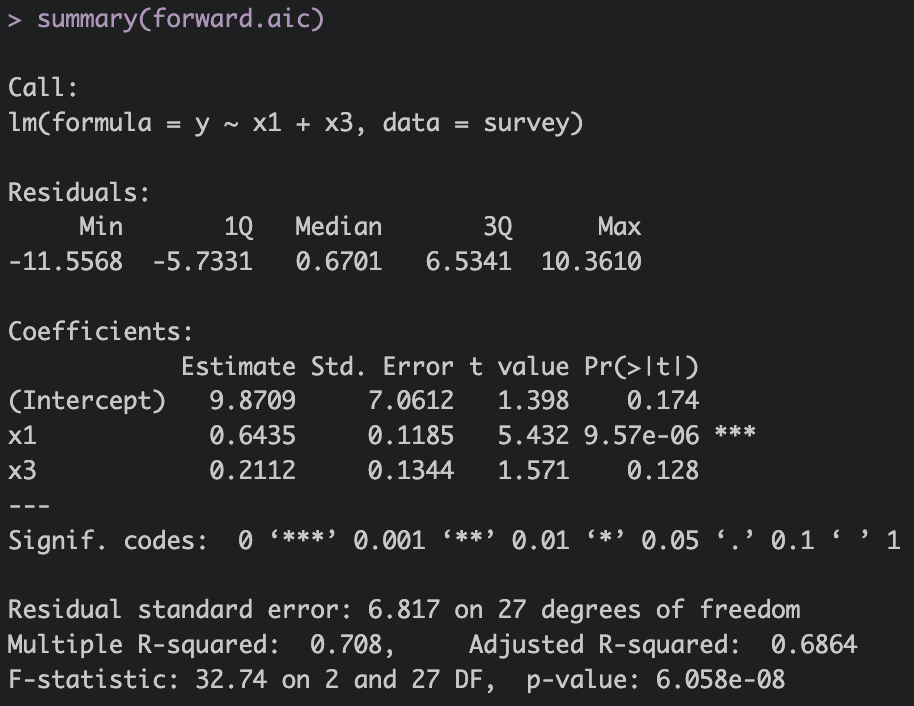
Backward
> backward.aic = step(lm.full, y~1, direction="backward")
Start: AIC=123.36
y ~ x1 + x2 + x3 + x4 + x5 + x6
Df Sum of Sq RSS AIC
- x5 1 3.41 1152.4 121.45
- x4 1 6.80 1155.8 121.54
- x2 1 14.47 1163.5 121.74
- x6 1 74.11 1223.1 123.24
<none> 1149.0 123.36
- x3 1 180.50 1329.5 125.74
- x1 1 724.80 1873.8 136.04
Step: AIC=121.45
y ~ x1 + x2 + x3 + x4 + x6
Df Sum of Sq RSS AIC
- x4 1 10.61 1163.0 119.73
- x2 1 14.16 1166.6 119.82
- x6 1 71.27 1223.7 121.25
<none> 1152.4 121.45
- x3 1 177.74 1330.1 123.75
- x1 1 724.70 1877.1 134.09
Step: AIC=119.73
y ~ x1 + x2 + x3 + x6
Df Sum of Sq RSS AIC
- x2 1 16.10 1179.1 118.14
- x6 1 61.60 1224.6 119.28
<none> 1163.0 119.73
- x3 1 197.03 1360.0 122.42
- x1 1 1165.94 2328.9 138.56
Step: AIC=118.14
y ~ x1 + x3 + x6
Df Sum of Sq RSS AIC
- x6 1 75.54 1254.7 118.00
<none> 1179.1 118.14
- x3 1 186.12 1365.2 120.54
- x1 1 1259.91 2439.0 137.94
Step: AIC=118
y ~ x1 + x3
Df Sum of Sq RSS AIC
<none> 1254.7 118.00
- x3 1 114.73 1369.4 118.63
- x1 1 1370.91 2625.6 138.16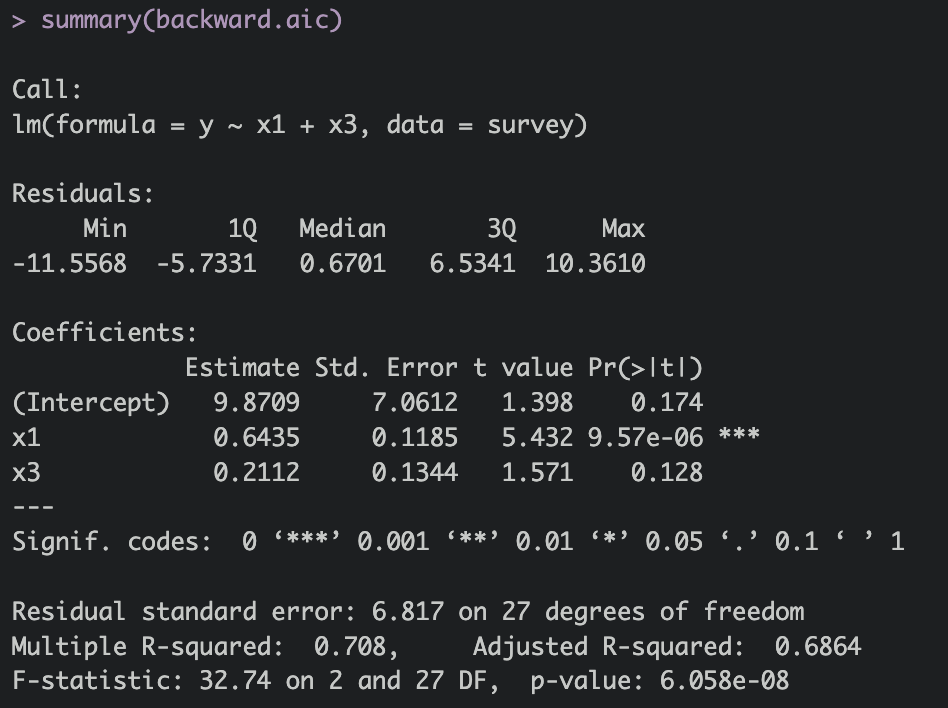
Stepwise
stepwise.aic = step(lm.mini, scope = list(lower ~ 1,
+ upper = ~ x1 + x2 + x3 + x4 + x5 + x6),
+ direction="both")
Start: AIC=150.93
y ~ 1
Df Sum of Sq RSS AIC
+ x1 1 2927.58 1369.4 118.63
+ x3 1 1671.41 2625.6 138.16
+ x4 1 1496.48 2800.5 140.09
+ x2 1 780.22 3516.7 146.92
<none> 4297.0 150.93
+ x5 1 105.16 4191.8 152.19
+ x6 1 103.35 4193.6 152.20
Step: AIC=118.63
y ~ x1
Df Sum of Sq RSS AIC
+ x3 1 114.73 1254.6 118.00
<none> 1369.4 118.63
+ x4 1 11.10 1358.3 120.38
+ x2 1 7.52 1361.9 120.46
+ x6 1 4.15 1365.2 120.54
+ x5 1 0.01 1369.4 120.63
- x1 1 2927.58 4297.0 150.93
Step: AIC=118
y ~ x1 + x3
Df Sum of Sq RSS AIC
<none> 1254.7 118.00
+ x6 1 75.54 1179.1 118.14
- x3 1 114.73 1369.4 118.63
+ x2 1 30.03 1224.6 119.28
+ x4 1 1.19 1253.5 119.97
+ x5 1 0.00 1254.7 120.00
- x1 1 1370.91 2625.6 138.16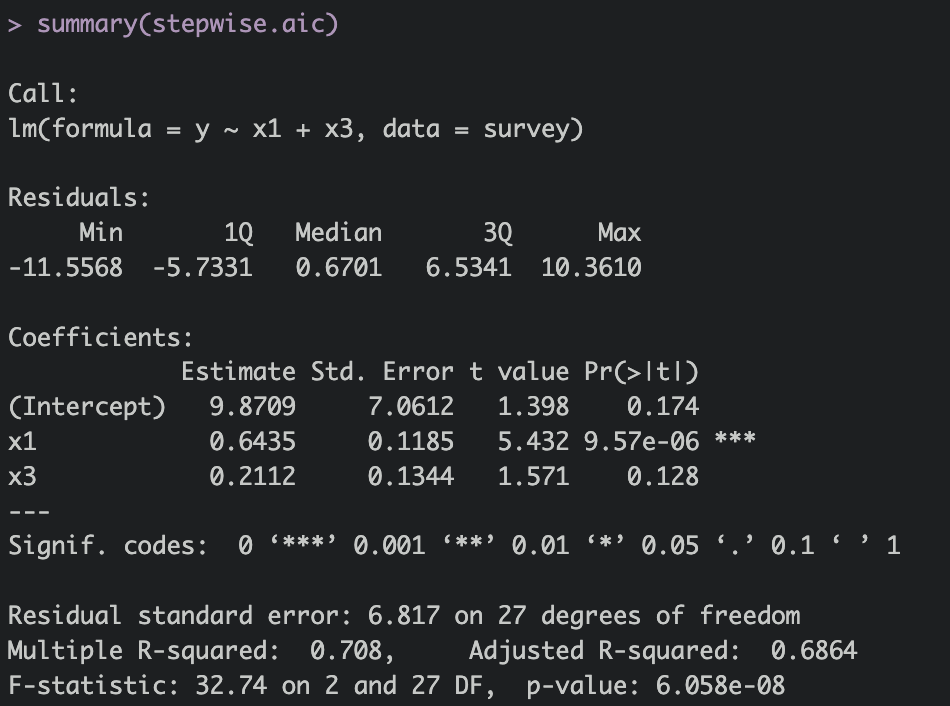
AIC
주어진 데이터에 대한 통계 모델의 상대적인 품질을 평가하는 것
AIC 값은 낮을수록 좋음
AIC = -2 + 2k
여기서 -2은 모형의 적합도를 의미하며, k는 모형의 추정된 파라미터의 개수를 의미하며 해당 모형에 패널티를 주기 위해 사용한다.
Example
SAS 프로그램
DATA survey;
INPUT y x1 x2 x3 x4 x5 x6 @@;
CARDS;
43 51 30 39 61 92 45 63 64 51 54 63 73 47 71 70 68 69 76 86 48
61 63 45 47 54 84 35 81 78 56 66 71 83 47 43 55 49 44 54 49 34
58 67 42 56 66 68 35 71 75 50 55 70 66 41 72 82 72 67 71 83 31
67 61 45 47 62 80 41 64 53 53 58 58 67 34 67 60 47 39 59 74 41
69 62 57 42 55 63 25 68 83 83 45 59 77 35 77 77 54 72 79 77 46
81 90 50 72 60 54 36 74 85 64 69 79 79 63 65 60 65 75 55 80 60
65 70 46 57 75 85 46 50 58 68 54 64 78 52 50 40 33 34 43 64 33
64 61 52 62 66 80 41 53 66 52 50 63 80 37 40 37 42 58 50 57 49
63 54 42 48 66 75 33 66 77 66 63 88 76 72 78 75 58 74 80 78 49
48 57 44 45 51 83 38 85 85 71 71 77 74 55 82 82 39 59 64 78 39
;
RUN;
/* Full Model */
PROC REG DATA=survey;
MODEL y=x1 x2 x3 x4 x5 x6;
PLOT student.*p. student.*x1 student.*x2 student.*x3
student.*x4 student.*x5 student.*x6; run;
/* Reduced Model */
PROC REG DATA=survey;
MODEL y=x1 x3;
PLOT student.*p. student.*x1 student.*x3;
RUN;
quit ;
PROC REG DATA=survey OUTEST=outsurvey ;
MODEL y=x1 x2 x3 x4 x5 x6 /CP SELECTION=ADJRSQ RSQUARE CP AIC BIC ;
RUN; QUIT;출력 결과
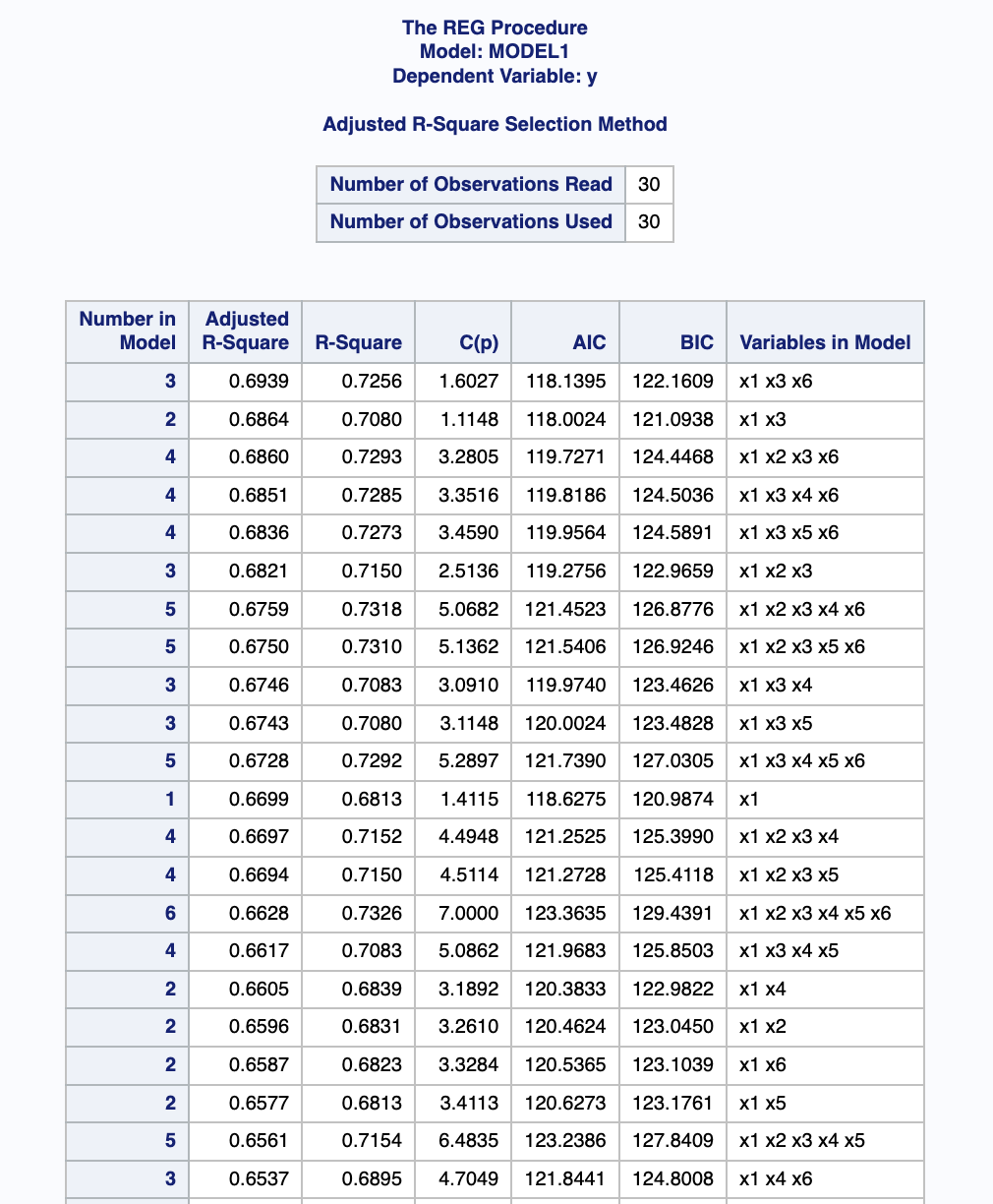
AIC값이 가장 작은 모델을 선택
