Efficient Adaptive Ensembling for Image Classification

Firsh published : 29 August 2023
https://doi.org/10.1111/exsy.13424
Introduction
1.1.
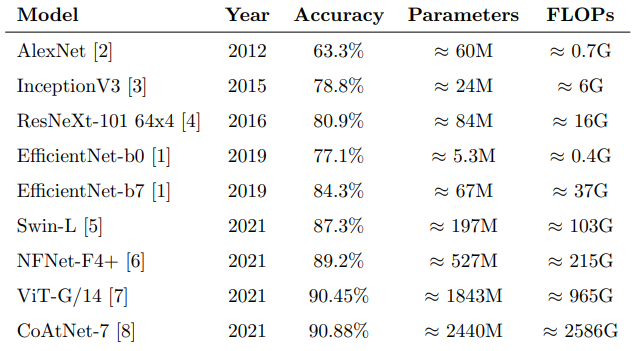
위의 표는 ImageNet classification의 Evolutation of the state-of-the-art를 나타낸다.
표를 살펴보면 모델들의 Accuracy는 조금씩 증가하는 반면, 그 조금을 향상하기 위해 Parameters와 FLOPs가 기하급수적으로 증가하는 추세를 보이는 것을 확인할 수 있다.
** 플롭스(FLOPS, FLoating point Operations Per Second)는 컴퓨터의 성능을 수치로 나타낼 때 주로 사용되는 단위
이는 ImageNet 데이터셋 뿐만 아니라 다른 데이터셋에서도 나타나는 현상이다.(e.g. CIFAR)
1.2.
ensembling기법은 혼자서는 좋은 성능을 내지 못하는 모델을 결합하여 좋은 성능을 내게하는 기법으로 ensemble size(i.e. # of weak learners), ensemble techniques(e.g. bagging, boosting, stacking)등이 중요하다.
ensemble 기법을 활용하기 위해서는 다양한 모델들을 훈련시켜야하기 때문에 모델을 training 하고 validation 하는데 많은 자원이 소요되고, 모델의 복잡성도 ensemble의 크기에 비례하여 증가한다.
따라서 ensembling기법은 시간이 많이 소요되기 때문에 computer vision에서는 실제로 잘 사용되지 않는다.
하지만 본 연구의 방법은 제한된 resources로도 좋은 성능을 내는 것을 보여주고 있다.(모델의 복잡성, validation&training time을 비교하였을 때)
1.3.
본 연구는 잘 정의된 앙상블 전략이 computer vision에서의 성능을 향상시킬 수 있다는 것을 보여 준다. Section 3 에서는 본 연구의 세밀한 전략(model, ensembling strategy, validation)등을 소개할 예정이고, Section 4 에서는 실험결과 와 데이터 설명, 마지막 Section에서는 결과를 다룰 예정
Related Work
최근에 이미지 처리 기반의 지능형 시스템의 수요가 증가했다. 이러한 상황에서 large-scale(대규모)의 이미지 데이터를 처리하는 기술은 비용 효율적이고, 궁극적으로 지속가능하다는 점을 보여야하는 중요한 기술적 과제입니다.
실제로 AI의 탄소영향은 잘 알려진 우려사항(AI 연구를 위해 많은 전기가 소모되고 있다.)으로 친환경 AI 패러다임이 선호되고 있다. 특히 AI의 탄소적 영향을 줄이기 위해 다양한 하드웨어적인 방법들이 있다.
소프트웨어적 방법으로는 AI 모델 자체를 단순화하거나 최적화하는 방법이다. 잘 알려진 방법으로는 parameter quantization & pruning, compressed convolutional filters and matrix
factorization, network architecture search, knowledge distillation 등이 있다. 본 연구에서는 ensembling을 활용하여 더 친환경적인 모델을 만든다.
ensembling은 성능이 낮은 모델을 결합하여 좋은 성능을 내는 모델로 바꾸는 접근이다. 성능이 여기서 사용되는 모델은 동질적 모델(같은 구조의 모델)이 아닐 수도 있다.
잘 알려져 있듯, low-complexity 모델은 training dataset의 복잡한 패턴은 학습하지 못한다.
반대로, very-complex 모델들은 training dataset의 다양한 복잡한 패턴을 잘 학습하지만, 중요하지 않은 패턴들도 학습한다. 따라서 test와 validation과정에서 좋은 성능을 내지 못한다. 특히 이런 문제는 high-variance인 모델에서 많이 나타난다.
ensembling을 대표하는 3가지 기술이 있다.
- bagging : variance 줄이기
- boosting : bias, variance 줄이기
- stacking : bias 줄이기
본 연구에서는 bagging을 활용한다.
Efficient Adaptive Ensembling
3.1. Efficiency
본 연구의 기초는 핵심 모델인 EfficientNet에 있다. EfficientNet은 유사한 성능을 가진 모델들보다 낮은 complexity로 classification 성능을 향상한다. EfficientNet은 미리 정해진 complexity를 기준으로 network scaling을 진행하기 때문에 이런 것이 가능하다.
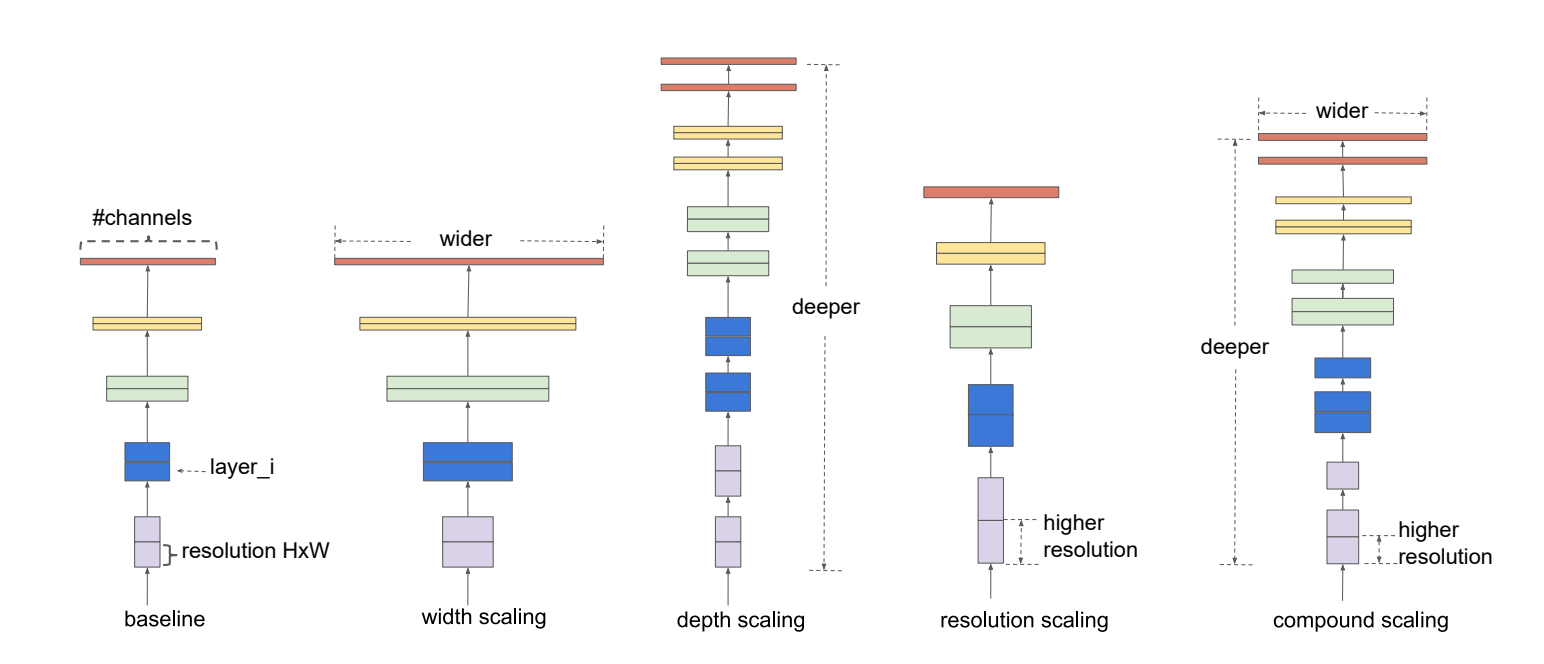
그림을 살펴보면, CNN에는 중요한 3개의 scaling(depth scaling,width scaling, input scaling)이 있다.
- Depth scaling : layers의 수 설정 의미 ★가장 중요 (어느 정도의 수준까지 특성을 감지할 것인가?)
- Width scaling : convolutional kernels의 크기, prarameters, channels의 수 설정(얼마나 많은 특성을 표현할 수 있는 모델을 만들 것인가?)
- Input scaling : size, resolution(해상도) 설정(어느 정도의 추가적인 세부 특성까지 감지할 것인가?)
각각의 scaling들은 직접 수동으로 설정하거나 grid search를 활용하여 설정하는데, 이런 과정에서 보통 모델의 복잡성이 기하급수적으로 증가하는데 비해 성능은 크게 증가하지 않는다.
위의 그림에서 소개된 scaling 방법은 compound scaling이다.
모든 scaling은 서로 의존적이기 때문에 셋을 모두 고려하여 함께 실행하여야 좋은 결과를 낼 수 있다. 따라서 compound coefficient ϕ(모델에 사용 가능한 총 자원)를 활용하여 최적의 scaling 조합을 찾기 위해 아래의 규칙을 제안한다. 네트워크의 총 복잡성은 대략적으로 에 비례한다.
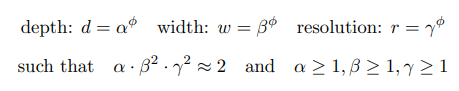
3.2. Adaptivity
- Ensemble by voting
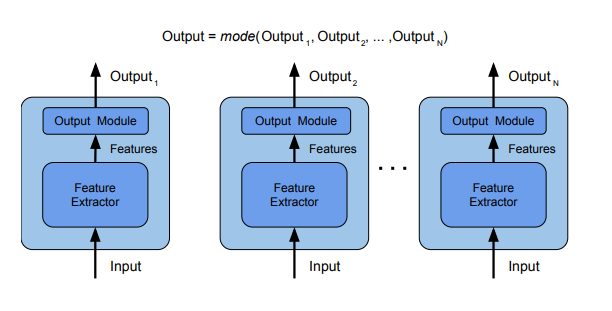
- Ensemble by output combination
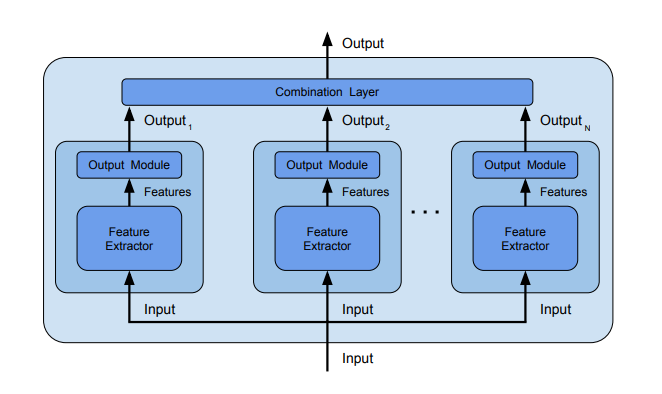
- Our adaptive ensemble method
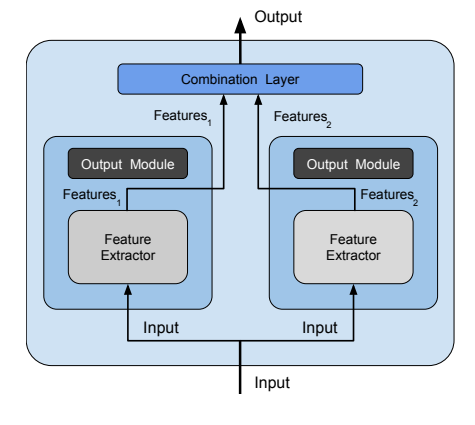
ensembling기법에서 모델을 결합하는 방법으로는 대표적으로 Ensemble by voting 그림에서와 같이 classification - voting/regression - averaging을 활용한다. 각각의 독립된 모델을 학습시켜서 결과를 집계(voting/averging)하여 최종 결과를 내는 모델을 만든다.
그러나 본 연구에서는 Adaptive combination을 수행하는데, Ensemble by output combination 처럼 결과를 결합해서 combination layer로 연결되는 것이 아닌 Our adaptive ensemble method 그림에서 볼 수 있듯 CNN에서 추출된 특성들을 combination Layer로 연결하여 모델을 만들었다.
: 번째 모델에서 추출된 feature vector
: 최종 결합된 feature vector
이 방법을 통해 ensemble의 성능은 유지하면서 complexity를 줄일 수 있었다. 이 방법은 Gradient Boostion의 완전 미분 가능 버전으로 볼 수 있다. 이 방법으로는 tree decision traversal을 수행할 필요없이 features 수준에서 ensemble이 수행된다.
4. Experimental results
본 연구는 파이토치를 기반으로 수행되었다.
4.1. Datasets
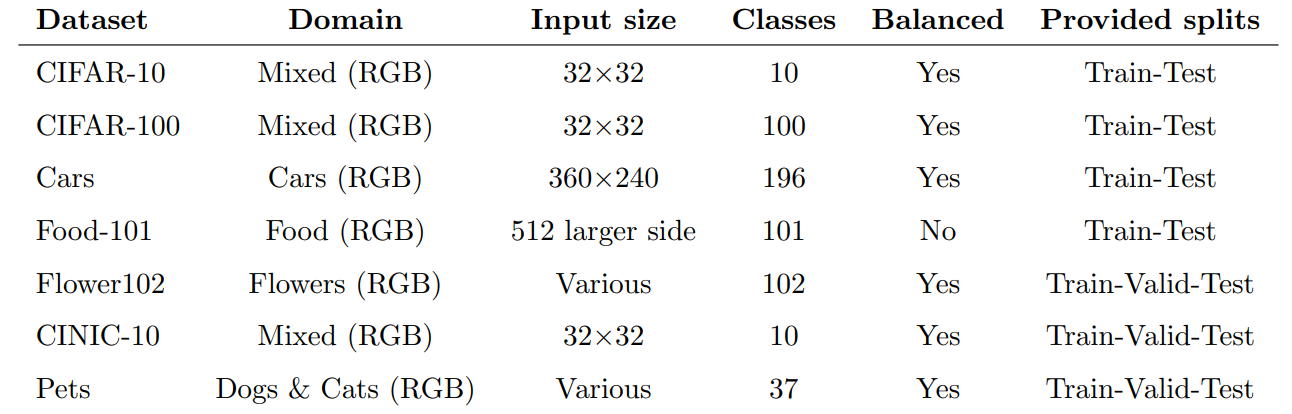
4.2. Input preprocessing
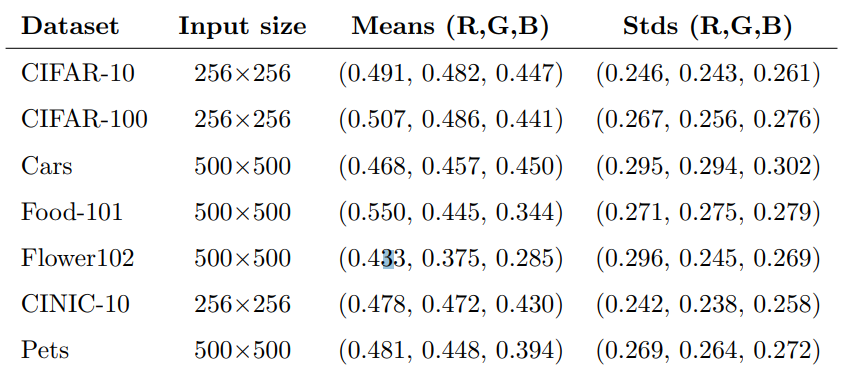
모델 성능 향상을 위한 전처리 2단계(resize, stanmdardization) 수행했다. Augmentation은 '순수한' 모델의 성능을 평가하기 위해 추가하지 않았다.
4.3. Transfer learning
Transfer learning은 weak learners 학습에만 활용 되었다.
4.4. Validation phases
Validation은 2페이즈로 구분
end-to-end weak learner overfitting traning
- ImageNet의 사전 학습된 모델 부터 전이 학습을 시작하고, 새로운 output 모듈을 세팅
- 모델들의 높은 spcialization을 위해서 과적합되도록 훈련
combination layer fine-tuning
- weak learner들로 학습한 output 모듈을 제거하고,(피처들만 학습시킨 상태) combination layer를 학습
2 페이즈에서 모두 AdaBelif optimizer를 활용
AdaBelief parameters : learning rate 5 · 10−4, betas (0.9, 0.999), eps 10−16, using weight decoupling without rectify
4.5. Avoid overfitting
overfitting을 피하기 위해 본 연구에서는 ensemble fine-tuning을 하는 동안 early stopping(patience로 설정해둔 몇 번의 epoch동안 validation set에서 성능 향상이 없으면 training을 종료)을 활용
4.6. Data Splitting
모든 데이터셋은 official train-test 가 분류되있다. 추가로 weak learner들을 end-to-end overfitting training을 위해 다음과 같이 데이터를 분류 :
-
최종 ensemble model의 크기인 설정(i.e. ensembling에 사용될 weak learners의 수) : 실험을 위해 최소 ensemble 크기인 로 설정
-
랜덤하게 training set을 개의 동등한 크기의 subset으로 분류(class 비율 유지)
- Pets dataset에만 예외가 존재(개, 고양이 2개의 subset으로만 구성) -
bagging : 각각의 subset마다 weak learner를 인스턴스화 하고 그 subset에 대해 과적합하도록 훈련.
- 모든 weak learner는 각각의 데이터 부분에 대해 높게 spcialization 하도록 훈련
- basis of preliminary test에서 EfficientNet-b0와 AdaBelief optimizer를 활용한 overfitting 훈련은 imitialization에 관계없이 항상 동일한 최소점으로 수렴(정확도가 거의 항상 100%에 가깝기 때문에 전역 최소점일 확률이 높음)
- 이 방법을 통해 모든 데이터셋에서 단 2번의 train만으로도 충분했다.(1번의 initialization)
4.7. Loss and Metrics
Training Loss
- 모든 데이터 셋이 다중 클래스를 갖고 있으므로, CrossEntropy Loss(예측 값과 실제 값 사이의 차이를 지수적으로 패널티를 주며, 클래스 소속 확률로 표현)를 사용
- 이 때문에 model의 output은 데이터 셋에 따른 지정된 크기(# of class)를 갖게 됨
- 그리고 각각의 는 input sample이 class 에 속할 확률을 의미
Validation and test metrics
- Validation set을 평가하기 위해 Weighted F1-score을 사용
(가중치를 통해 클래스 간의 불균형 문제를 해소하고, 1종오류와 2종오류를 모두 고려하기 위함) - Test set에서는 이전의 연구들과의 비교를 위해 Accuracy를 사용
4.8. Hyperparameters
몇몇의 Hyperparameter들은 이미 이전 section에서 설정(i.e. preprocessing size and standardization, optimizer parameters and ensemble size)
그러므로 total validation 시간을 줄이기 위한 hyperparameter을 설정
- early stopping patience : 10 epochs
- batch size : 500 500 이미지 55(미세 조정 시 200), 256 256 이미지 200(미세 조정 시 700)
Hyperparameter 구성 파일


seed를 제외한 모든 hyperparameter은 미리 설정 되어 있으며, 앙상블 fine-tuning을 위해 5개의 랜덤 seed가 사용되었다.
이 방법을 통해 2번의 end-to-end weak training과 5번의 fine-tuning ensemble training를 수행했다.
5. Results and Discussion
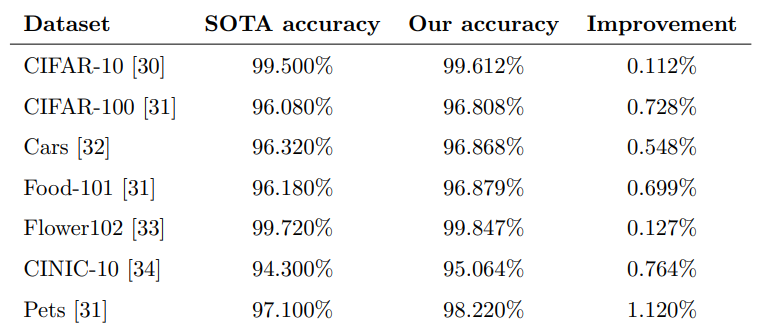
표를 살펴보면 모든 major benchmark 데이터 셋에서 본 연구가 성능을 향상 시켰음을 확인할 수 있다.
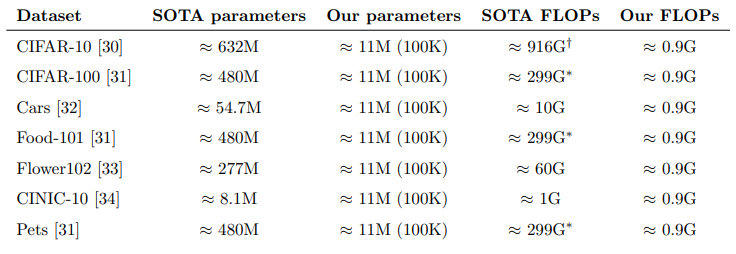
또한 다음의 표를 통해 본 연구의 모델이 모델의 복잡성이 고려된 결과임을 확인할 수 있다. 게다가 combination layer에서 fine-tuning을 하기 때문에 최종 솔루션에의 parameter는 약 100K 정도이다.
본 연구를 강조하기 위해 5개의 서로 다른 weak model로 학습한 ensemble 모델과 비교하였다.
CIFAR-100 데이터 셋의 경우 본 연구의 모델의 정확도는 96.808%, ensemble 모델의 정확도 84.930%
각각의 weak model이 같은 이미지를 같이하지 않도록 작업을 했기때문에 당연한 결과이다.
CIFAR-10 데이터 셋의 경우 본 연구의 모델의 정확도는 99.612%, ensemble 모델의 정확도 96.640%
다음으로는 CIFAR-10과 CIFAR-100 데이터 셋을 가지고 6 EfficientNet-b0 weak model로 Voting 방법을 통해 만든 ensemble과 비교하였다.
CIFAR-10 데이터 셋의 경우 가장 좋은 성능을 내는 weak model은 정확도 97.
37%, 2개의 weak model의 ensemble은 97.54%, 5개의 weak model의 ensemble은 97.66%을 얻었다. (본 연구의 모델은 99.61%)
CIFAR-100 데이터 셋의 경우 가장 좋은 성능을 내는 weak model은 정확도 85.55%, 2개의 weak model의 ensemble은 86.64%, 5개의 weak model의 ensemble은 87.56%을 얻었다. (본 연구의 모델은 96.81%)
또한, 전통적인 weak model들을 본 연구의 앙상블 기법으로 (feature 단계에서 combination layer에 연결) 결합했을 때, 성능이 향상 되는 것도 보여준다.
CIFAR-10의 best adaptive ensembledm의 정확도 97.47%(99.61%과 비교), CIFAR-100 the best adaptive ensemble의 정확도 86.79%(96.81%과 비교)
마지막으로 single task 소요 시간 분석
- : single end-to-end weak learner training 소요 시간
- : single fine-tuning ensemble model training 소요 시간
- : single forward step 소요 시간
- : single backward step 소요 시간
- : simgle optimization update step 소요 시간
single Task, the total time
본 연구의 경우 (2번의 end-to-end training)이고, (5번의 fine-tuning ensemble training)이다.
각각의 end-to-end 훈련 과정을 병렬로 수행할 수 있으므로 batch크기와 시간이 절반으로 단축된다.
또한 모든 fine-tuning 훈련 과정도 병렬로 수행할 수 있다.
그리고 single training 이 각각의 epoch동안의 forward + backward + update steps 로 구성된다고 할 때,
single fine-tuning 훈련 시간은 실제 epoch 수에 따라 비례한다. 따라서 총 시간은()
FLOPs 측면에서 보면,
위의 식은 EfficientNet-b0 구조의 FLOPs를 나타냄
위의 식은 AdaBelief update step()의 FLOPs를 나타냄
이는 하나의 이미지에 대한 전체 파이프라인이 약 1.3GLOPs를 필요한 한다는 것을 의미
앞에서 가장 적은 parameter를 갖는 SOTA 모델로 CINIC-10 데이터 셋의 SOTA 모델은 parameter(8.1M)로 하나의 이미지에 대해 약 1GFLOPs가 필요하면 하지만 우리의 모델은 0.9GFLOPs로 속도 향상이 두드러지는 것을 확인할 수 있음
6. Conclusion and future works
본 연구에서는 image classification문제에서 complexity가 크게 증가하는 반면 성능 향상은 미미한 연구의 Trend를 반전시키기 위한 방법을 제시
2개의 EfficientNet-B0의 weak learner를 사용하여 겹치지 않는 subset집합으로 bagging을 수행하고 각각의 subset에 과적합하도록 하는 훈련하는 방법 활용
본 연구에서는 2개의 weak learner을 사용하여 ensemble의 크기를 작게 진행했으나 5개의 weak learner을 활용하면 더 효율적일 것이다.
다양한 bagging 전략을 활용하면 성능을 더 향상 시킬 수 있을 것으로 예상한다.
이러한 결과들을 다른 분야(Object Detection, Segmentation)에서도 연구할 수 있을 것이다.
나의 생각
ensemble을 활용하여 모델을 병렬로 연결하고 이를 통해 오히려 모델의 학습 시간을 줄일 수 있다는 것이 놀라웠다. 그리고 모델을 병렬로 학습할 때,overfitting하게 훈련하여 최종 모델의 성능을 향상한 것도 재미있었다. overfitting은 항상 문제라고만 생각했는데, 특정된 하나!를 찾는데는 오히려 좋은 방법이 되는 것이 신기했다. 다른 문제에서도 이런 방법을 한번 활용해보고 싶다.
