Supervised Learning Foundation
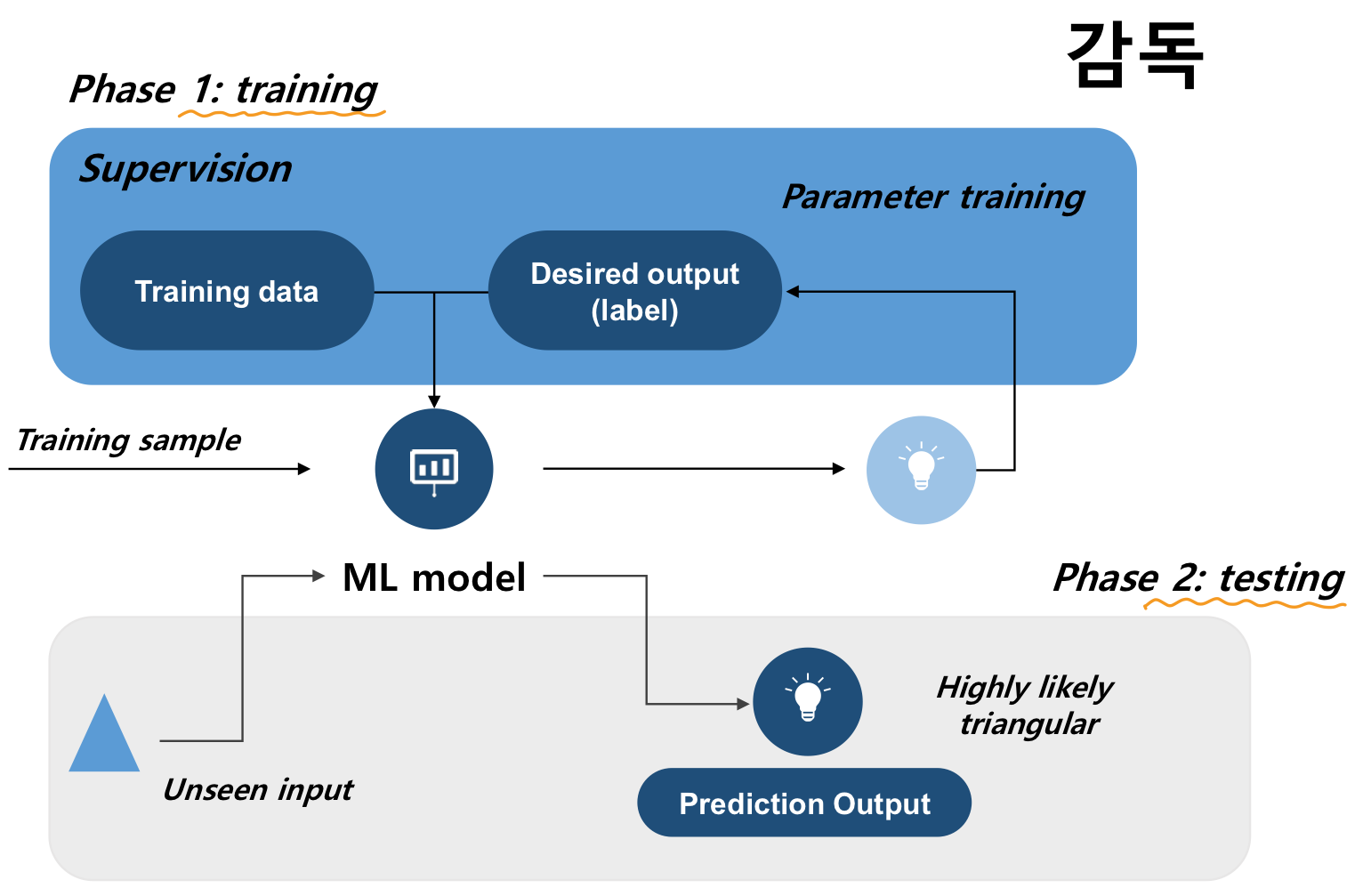
Learning model
- Goal: target function
→목표함수 찾기
입력 데이터(X)를 출력 데이터(Y)로 매핑하는 역할을 합니다. 이를 통해 우리는 새로운 입력 데이터가 주어졌을 때 출력 데이터를 예측할 수 있게 됩니다. - learning model 학습모델
- Feature selection 특성 선택:
우리는 입력 데이터에서 중요한 특성을 선택하여 학습에 사용합니다. 이 과정은 데이터를 이해하고, 불필요한 정보를 제거하고, 중요한 정보를 강조하는 데 도움이 됩니다. - Model selection 모델 선택:
우리는 학습 알고리즘을 선택합니다. 이것은 신경망, 결정 트리, 서포트 벡터 머신 등 다양한 형태가 될 수 있습니다. - Optimization 최적화:
학습 알고리즘은 최적의 모델 파라미터를 찾기 위해 데이터를 사용합니다. 이 최적화 과정은 손실 함수를 최소화하는 방향으로 이루어집니다.
- Feature selection 특성 선택:
- Hypothesis/Evaluation 가설/평가:
학습 후, 우리는 가설 함수(g)를 얻습니다. 이 함수는 목표 함수(f)를 근사하려는 시도입니다. 즉, 라는 것은 학습된 모델(g)이 실제 원하는 함수(f)에 가깝다는 것을 의미합니다. 이를 평가하기 위해 우리는 검증 데이터를 사용하여 모델의 성능을 측정합니다.
하지만, 머신러닝은 Data의 결핍으로 인한 불확실성을 포함 할 수 밖에 없다.
Model generalization
따라서 일반화가 중요하다.
- Learning is an ill-posed problem; data is limited to find a unique solution
- Generalization(Goal): a model needs to perform well on unseen data
- Generalization error ; the goal is to minimize this error, but it is impractical to compute in the real world
Learning from data → Learning from error (supervision)
- Use training/validation/test set errors for the proxy
모델의 정확도를 올리려면
- bias ↓
- 모델 일반성 ↑
- variance ↓
Bias-variance Trade-off
- Split into two objectives:
- Objective 1: make
- Failure: overfitting → high variance and low bias
- If a model is too complex
- Objective 2: make
- Failure: underfitting → high bias and low variance
- If a model is too simple
→ The two objectives have trade-off between approximation and generalization w.r.t model complexity
Avoid overfitting
- (Problem) In today's ML problems, a complex model tends to be used to handle high-dimensional data (and relatively insufficient number of data); prone to an overfitting problem
오늘날의 머신러닝 문제에서는 고차원의 데이터를 처리하기 위해 복잡한 모델이 주로 사용됩니다. 하지만, 이러한 복잡한 모델은 데이터의 수가 상대적으로 부족한 상황에서 과적합 문제에 취약하다는 문제점이 있습니다.
과적합이란 모델이 학습 데이터에 너무 잘 맞아버려 새로운 데이터에 대한 예측력이 떨어지는 현상을 말합니다. 다시 말해, 모델이 학습 데이터의 노이즈까지 학습해버려 일반화 능력을 잃어버린 상태입니다. - (Curse of dimension) Will you increase the dimension of the data to improve the performance of the data to improve the performance as well as maintain the density of the examples per bin? If so, you need to increase the data exponentially.
차원의 저주 = 데이터의 차원을 늘려 성능을 향상시키고, 예시당 데이터 밀도를 유지하려고 하나요? 만약 그렇다면, 데이터를 기하급수적으로 늘려야 합니다.
데이터의 차원을 늘리는 것은 종종 모델의 성능을 향상시키는 데 도움이 됩니다. 하지만 동시에 예시당 데이터 밀도를 유지하려면, 데이터의 양을 기하급수적으로 늘려야 합니다. 이것이 바로 '차원의 저주'라고 불리는 문제입니다.
차원의 저주는 데이터의 차원이 증가할수록 해당 공간의 부피가 기하급수적으로 증가하는 현상을 말합니다. 이로 인해 특성 공간이 점점 희소해지고, 데이터 간의 거리도 증가하게 됩니다. 이는 모델이 복잡해지고, 과적합을 일으키는 경향이 있어 학습이 어려워지는 문제를 야기합니다.
예를 들어, 한 변의 길이가 1인 단위 정육면체를 생각해봅시다. 이 정육면체 내에 무작위로 점 10개를 생성하면, 이 점들은 서로 가까운 위치에 분포할 가능성이 높습니다. 하지만 이 정육면체의 차원을 10차원으로 늘리면, 각 점들은 서로 멀리 떨어진 위치에 분포하게 됩니다. 이는 모델의 학습을 어렵게 만들며, 이를 해결하기 위해서는 기하급수적으로 많은 양의 데이터가 필요하게 됩니다.
따라서, 차원의 저주를 피하려면 차원 축소 기법을 사용하는 것이 좋습니다. PCA(주성분 분석)나 t-SNE와 같은 기법들이 이에 해당합니다. 이러한 기법들은 데이터의 차원을 줄이면서도 데이터의 중요한 정보를 최대한 보존하는 데 도움이 됩니다. - (Remedy)
- Data augmentation
- Regularization to penalize complex models (variance reduction); make a model not too sensitive to noise or outliers (e.g. drop-out, LASSO)
- Ensemble: average over a number of models
Data Augmentation: 데이터의 수를 늘려주는 것은 과적합을 방지하는 가장 기본적인 방법입니다. 더 많은 데이터는 모델이 다양한 패턴을 학습하는 데 도움이 됩니다.
Regularization: 모델의 복잡도를 제한하여 과적합을 방지하는 방법입니다. L1 정규화, L2 정규화 등 다양한 정규화 기법이 있습니다.
Drop-out: 신경망에서 사용되는 방법으로, 일부 뉴런을 임의로 비활성화하여 모델의 복잡도를 줄이는 기법입니다.
Early Stopping: 검증 오류가 증가하기 시작할 때 학습을 중단하는 방법입니다. 이는 모델이 과적합되기 시작하는 시점을 감지하는 데 도움이 됩니다.
Cross-Validation (CV)
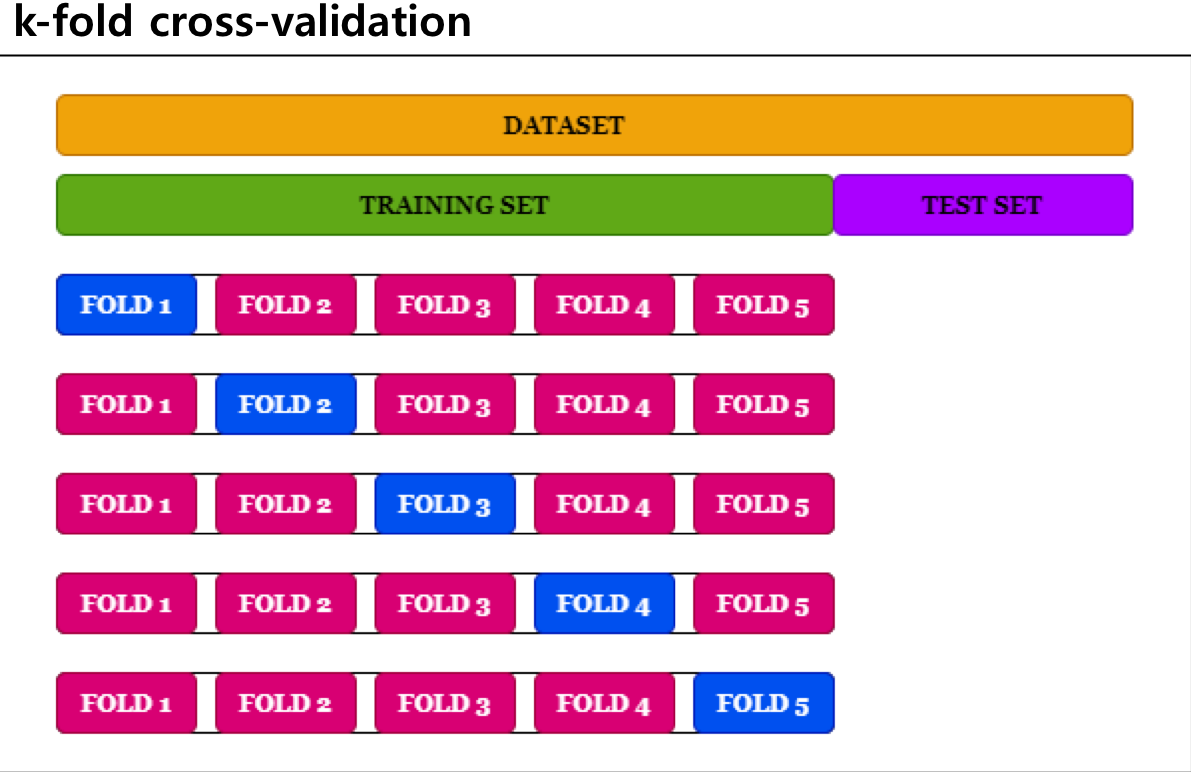
- Training data set - used to train a model to fit data
- Validation data set - used to provide unbiased evaluation of the model's fitness
- Test data set - never been used in the training
→ Cross-validation allows a better model to avoid overfitting (but more complexity)
교차 검증 (Cross-Validation)
교차 검증은 모델의 일반화 성능을 평가하기 위해 사용되는 통계적 방법입니다. 이 방법은 데이터를 여러 부분으로 나누고, 이를 반복적으로 훈련하고 검증하는 과정을 통해 모델의 안정성과 성능을 평가합니다.
교차 검증의 기본적인 절차는 다음과 같습니다:
데이터를 k개의 동일한 크기의 부분 집합(또는 '폴드')으로 분할합니다.
모델을 k-1개의 폴드로 훈련시키고, 나머지 1개의 폴드로 검증합니다.
이 과정을 k번 반복하여, 각 폴드가 한 번씩 검증용으로 사용됩니다.
k번의 반복 과정에서 얻은 성능 지표를 평균내어, 모델의 최종 성능을 평가합니다.
교차 검증의 가장 큰 장점은 모든 데이터를 훈련과 검증에 모두 사용하기 때문에, 데이터의 편향을 최소화하고 모델의 일반화 성능을 보다 정확하게 평가할 수 있다는 것입니다. 또한, 모델의 안정성도 함께 평가할 수 있습니다. 즉, 다양한 훈련 데이터에 대해 모델의 성능이 얼마나 일관적인지 알 수 있습니다.
교차 검증 기법은 k-겹 교차 검증, 계층적 k-겹 교차 검증, 임의 분할 교차 검증 등 다양한 변형이 있습니다. 이들은 각각 다른 상황에 적용되며, 사용하려는 모델의 특성과 데이터의 특성에 따라 적합한 방법을 선택하면 됩니다.
교차 검증은 모델의 성능 평가뿐만 아니라, 모델 선택, 하이퍼파라미터 튜닝 등에도 널리 사용되는 중요한 기법입니다. 이를 통해 보다 정확하고 안정적인 머신러닝 모델을 구축할 수 있습니다.
Linear Reagression
Gradient Descent
Linear Classification
Advanced Classification
Ensemble
