1. 모델 학습만 하면 될까?
상품화를 위한 머신러닝 모델은 모델 학습만?
2. 다양한 과정을 거치는 모델 개발 여정
모델 개발을 위한 과정
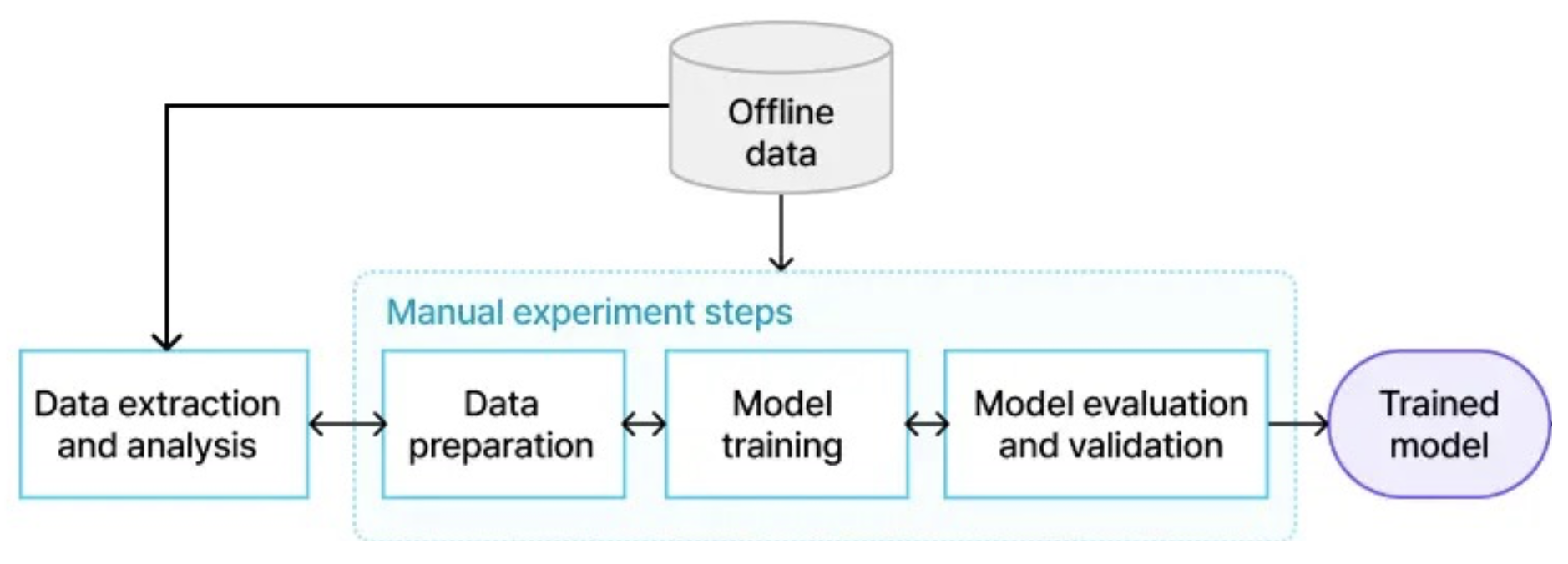
1단계: 학습 데이터 준비
- 머신러닝 모델의 목적에 맞춰서 학습 데이터를 준비
- Data 수집, Data 유형에 따른 처리, Data Sampling, Labeling, Class Imbalance 고려
2단계: Feature Engineering
- 데이터를 모델에 학습할 수 있는 형태로 Engineering
- Data Cleansing, Feature Selection, Feature Reduction, Data Augmentation, Data Scaling & Encoding
3단계: 모델 학습 및 최적화 평가
- 모델을 목적에 맞게 학습하고 평가, 최적화
- Model Traning, Model Evaluation, Model Hyperparameter Tuning, Model Selection, Ensembles & Auto ML
3. 모델 상품화 예시
숙박 업소 추천 모델을 만든다고 해봅시다.
숙박 추천 모델 개발
- 3단계의 과정을 거치면서 머신 러닝 모델을 개발
- 1단계: 학습 데이터 준비 (문제인식 포함)
- 2단계: Feature Engineering (전처리)
- 3단계: 모델 학습 및 평가
문제 인식
숙박 추천 문제 이해하기
 숙박 예약 사이트에서는 사용자의 프로필, 검색 기록 등을 활용하여 맞춤형 숙박 추천 서비스 제공을 목적으로 한다.
### 모델 개발 목표 설정
숙박 예약 사이트에서는 사용자의 프로필, 검색 기록 등을 활용하여 맞춤형 숙박 추천 서비스 제공을 목적으로 한다.
### 모델 개발 목표 설정
 사용자 경험을 향상시키기 위한 숙박 추천 서비스를 개발하고자 한다. 이를 위해, **정확성**과 **속도** 모두 높은 머신러닝 모델을 개발한다.
사용자 경험을 향상시키기 위한 숙박 추천 서비스를 개발하고자 한다. 이를 위해, **정확성**과 **속도** 모두 높은 머신러닝 모델을 개발한다.
학습 데이터 준비
숙박 데이터 수집 방법 설계
외부 데이터베이스에서 호텔 정보와 리뷰 데이터를 수집하여 데이터셋을 구성 설계. 이때, 어떤 데이터를 수집하는 등의 프로토콜 설계
개인 정보 보호 검토
데이터 수집을 위한 개인 정보 보호 검토 필요. 데이터 수집을 위한 문서 확충(개인 정보 수집 동의 등)
숙박 데이터 수집
크롤링을 통해 수집할 경우, 저장할 스토리지와 어떤 스토리지 유형을 선택할 지를 고려.
레이블링 (정답셋)
데이터의 레이블(정답셋)이 없는 경우, 어떻게 이 문제를 해결할 지 검토 필요. 인력을 활용하거나 외부 기업을 활용
Feature Engineering
데이터 정제 및 결측치 처리
수집하는 호텔 정보와 리뷰 데이터는 자연어 처리 과정을 거쳐 전처리 필요. 잘못된 데이터는 처리 필요.
데이터 분석
호텔 정보/리뷰 데이터를 분석하여 데이터 불균형 문제가 있는지, 혹은 데이터가 잘못되지 않았는지 파악. 데이터 분석으로 사용할 데이터에 대해서 검토.
변환 및 스케일링
숙박 시설의 위치, 가격, 시설 등 여러 특성을 고려하여 수치화하고 스케일링 진행.
데이터 분할 및 검증 세트 구성
전체 데이터 셋을 훈련, 검증 및 테스트로 나누어 모델 훈련에 활용할 수 있도록 저장. 이때, 다양한 팀에서 사용할 수 있도록 적절한 저장 형식과 스토리지 선택.
모델 훈련과 선택
1. 여러 가지 머신러닝 알고리즘 검토
선형 회귀, 의사결정 트리, 랜덤 포레스트, SVM, 신경망 등 다양한 알고리즘이 검토.
각 알고리즘의 특징을 파악하고 모델 선택에 반영 및 반복 테스트.
2. 모델 선택 프로세스
평가 지표를 선택(일부 숙박 업소만 추천하지는 않는지, 리뷰가 적은 호텔도 적절히 추천하는지) 하고, 검증 세트를 사용하여 여러 가지 알고리즘의 성능을 비교. 최종 모델을 선택하고 훈련.
3. 모델 훈련 및 성능 평가
모델을 훈련하면서 하이퍼파라미터를 조정하며, 다양한 평가 지표를 활용하여 검증 세트에 대한 예측 성능을 평가.
모델 성능 향상, 최적화
하이퍼파라미터 튜닝
최적의 하이퍼파라미터를 찾기 위해 그리드 탐색, 랜덤 탐색, 베이지안 최적화 등의 방법을 사용.
앙상블 기법
다양한 알고리즘의 결과를 결합하여, 보다 정확한 예측이 가능한지 테스트.
오차 분석 및 해결
모델이 잘못 예측한 샘플에 대한 오차를 분석하여, 모델 성능을 개선할 수 있는 방법을 모색.
모델 상품화 검토
성능 평가 결과
85% 이상의 정확도 보이며, 해석 가능성(왜 이 숙박을 추천했는지) 등을 평가.
성능 개선의 가능성
데이터 양의 증가, 특성의 추가, 더 나은 성능을 보이는 알고리즘의 도입 등을 통해 모델의 성능을 더욱 개선 여부 검토.
적용 가능한 지 검토
성능 외에 추론 속도, 지연 시간 등을 검토. A/B test 검토.
