정형, 반정형, 비정형 데이터
정형 데이터
- 구조화된 데이터로 '표' 형태로 표현되며 고정된 스키마를 갖음
- 데이터 베이스, 스프레드시트 및 CSV 파일과 같은 데이터 소스에서 얻음
- 예시: 고객 데이터 베이스(고객 이름, 주소, 전화번호, 이메일과 같은 고정된 필드), 주문 데이터 베이스(주문 번호, ID, 수량, 가격)
정형 데이터 특징
- 고정된 스키마: 정해진 필드 및 데이터 형식을 갖음
- SQL 쿼리 사용 가능: 데이터 베이스 관리 시스템에 SQL 쿼리를 통해 데이터 검색 및 조작 가능
- 쉬운 분석: 데이터 분석 도구와 머신러닝 모델에 쉽게 적용 가능
비정형 데이터
- 구조가 없거나 매우 제한적인 구조를 가지지 않는 데이터로 텍스트, 이미지, 오디오, 비디오 같은 형태를 갖음
- 예시: X의 트윗(텍스트로 된 트윗, 특정 구조 따르지 않음), 의료 이미지(X-ray 이미지 또는 MRI 스캔 이미지)
비정형 데이터 특징
- 구조가 없음: 데이터는 자유 형식이며, 특정 구조를 따르지 않음
- 고도의 전처리 필요: 데이터 전처리 및 특징 추출(feature extraction/engineering)이 고도의 기술로 필요하며, 자연어 처리/컴퓨터 비전 및 음성 처리 기술을 활용해야함
반정형 데이터
- 구조가 명확하게 정의되지 않은 데이터로 '일부' 구조화된 정보를 갖음
- XML, JSON, HTML과 같은 마크업 언어를 사용하여 주로 표현
- 예시: 웹 스크래핑 데이터, 기업 문서 데이터(회사 문저 중에서 특정 키워드나 구조화된 정보를 추출한 데이터)
반정형 데이터 특징
- 일부 구조화된 정보: 데이터 내에 구조가 정확히 정의되지 않았지만 일부 마크업 또는 태그를 갖음
- 데이터 파싱 필요: 데이터 파싱을 통해 의미있는 정보 추출이 필요
- 유연성: 데이터 형식이 더 유연하며 새로운 정보를 추가하거나 수정하기 용이함
실시간 데이터
실시간 데이터
- 데이터를 실시간으로 분석하고 수행해야 하는 데이터
- 이미 저장된 것이 아닌, 실시간으로 데이터가 수집되는 것
- 예시: 유튜브 시청 데이터, 금융 거래 데이터, IoT 센서 데이터
실시간 데이터 예시
- 금융 거래: 주식 거래 및 금융 거래 데이터는 실시간으로 처리되어야 하며 시장 조건에 따라 신속한 결정을 내려야 함
- IoT 센서 데이터(미세먼지): 환경 데이터를 센싱하는 경우, 실시간으로 분석하여 환경 상태를 모니터링 하거나 경고를 생성
스트리밍 데이터
- 지속적으로 생성되고 전송되는 데이터 스트림(물줄기)을 나타냄
- 시간이 지나면서 변경되며 새로운 데이터가 계속해서 이전 데이터에 추가됨(지속적으로 전체 데이터 용량 증가)
스트리밍 데이터 처리 특징
- 무한한 데이터 스트림: 데이터의 끝이 없고 지속적으로 생성되므로 스트리밍 데이터를 처리하기 위한 특수한 방법 필요
- 실시간 분석: 데이터가 도착하자마자 분석되며, 지연이 발생하지 않아야 함
IoT 데이터
- 다양한 종류의 데이터가 복합적으로 스트리밍 형식으로 수집
- 작은 Edge Device에서 수집되는 경우가 많음
IoT 데이터 처리 특징
- 대량 데이터 처리: 일반적인 데이터들보다도 상대적으로 많은 데이터를 저장 및 처리할 수 있어야함
- 다양한 데이터 형식: 다양한 형식과 프로토콜로 데이터가 전송되기 때문에, 데이터 변환 및 표준화가 필요할 수 있음
- 실시간 처리 & 모니터링 경고
데이터 저장과 관리
데이터 저장소
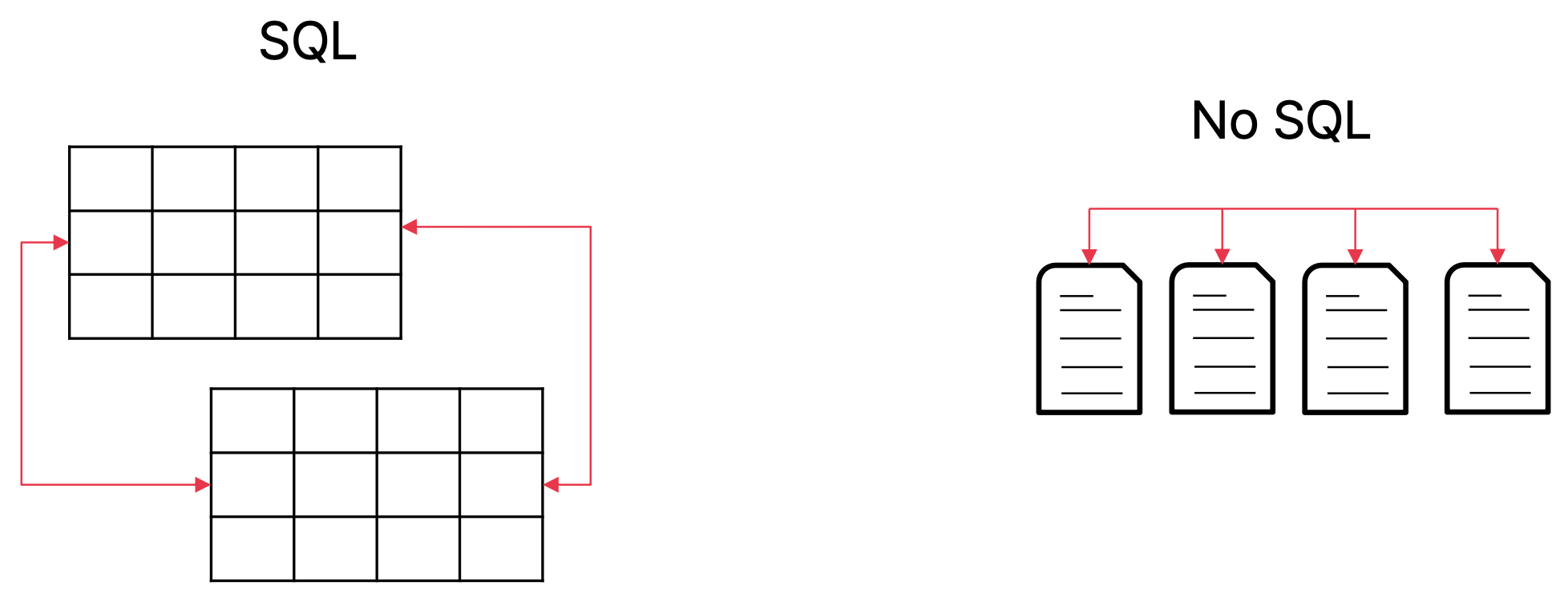
Database(DBMS)
- 구조화된 데이터를 효율적으로 저장, 관리 및 검색하기 위한 소프트웨어 시스템
- SQL을 사용하여 데이터 베이스에 대한 쿼리 및 조작을 지원
- MySQL, PostgreSQL, ...
NoSQL Database
- 정형 데이터 외에도 반정형 및 비정형 데이터를 저장하고 관리하기 위한 데이터 베이스
- 데이터 형식 유연성 제공, 대량 데이터 처리와 분산 환경 확장 가능
- MongoDB, Cassandra, Redis, ...
Data Lake
- 다양한 비구조화 데이터를 저장하는 시스템으로, 원시 데이터를 보관하고 나중에 분석 및 처리에 활용
- 스키마의 유연성을 제공하고 나중에 정의되거나 변경될 수 있으며, 쉽게 새로운 데이터 형식을 수용할 수 있음
Data Warehouse
- 다양한 데이터 원본에서 데이터를 추출, 변환 및 로드(ETL)하여 중앙 집계 및 분석을 위한 중앙 데이터 저장소를 만드는 시스템
- 주로 정형 데이터 중심. 구조화된 데이터를 저장하고 분석.
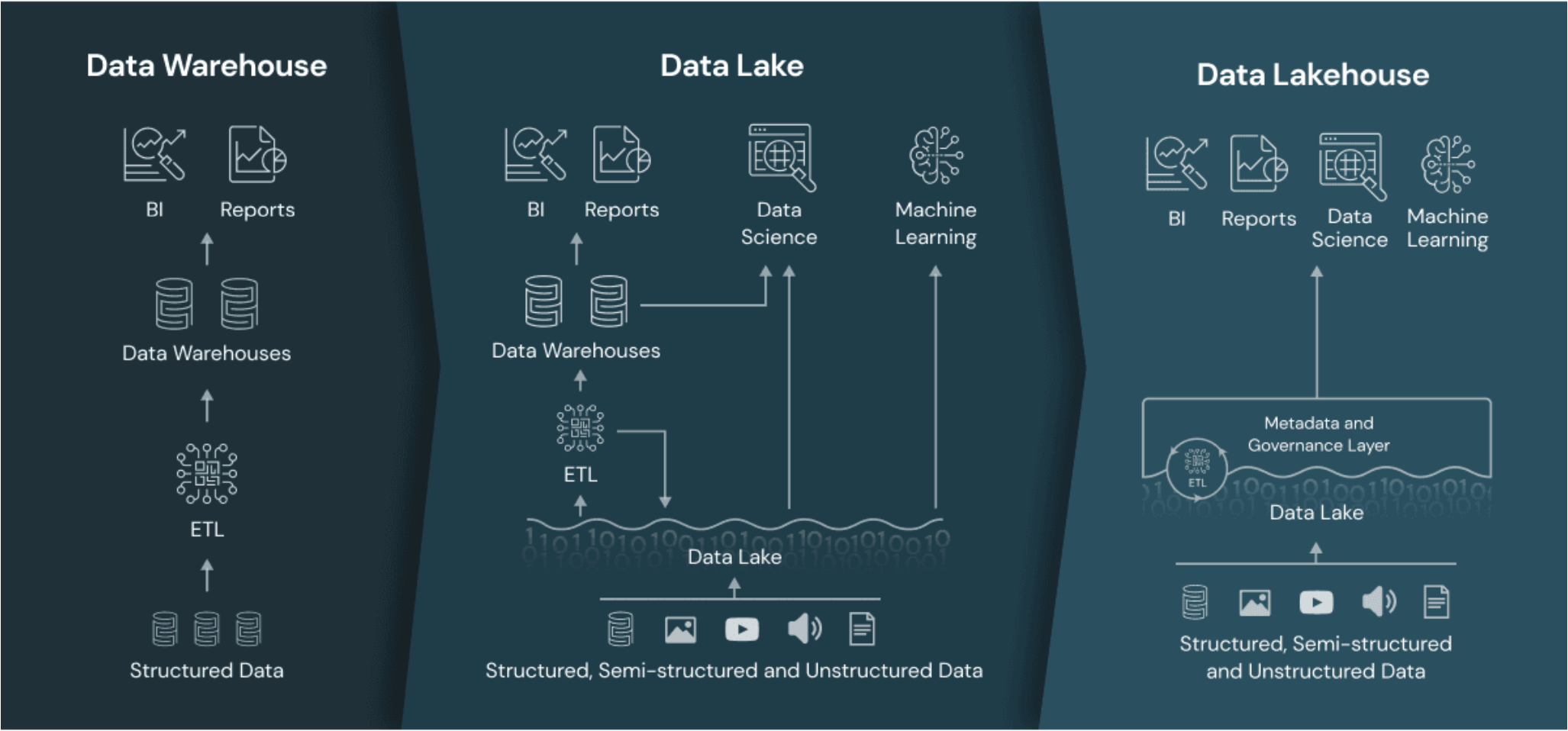
출처: Databricks
데이터 버전 관리
데이터 버전 관리 중요성
- 데이터의 변경 이력을 추적하고 이전 상태로 롤백할 수 있게 하는 프로세스
- 데이터의 무결성과 안정성을 보장하며, 잘못된 변경으로 인한 문제를 예방
Git-LFS 혹은 Feature Store
- Git Large File Storage는 Git 확장 도구로 대용량 데이터 파일을 관리할 수 있음
- Feature Store는 Feature(Data 가공된 버전)의 버전 관리를 지원
데이터 품질과 보안
데이터 품질 관리
데이터 품질의 중요성 및 영향
- 데이터 품질은 데이터가 정확하고 신뢰할 수 있는지 나타냄
- 낮은 데이터 품질은 잘못된 분석 및 결정을 초래할 수 있으며, 비즈니스 프로세스에 영향을 미칠 수 있음 → 의사 결정 오류
데이터 품질 검사 및 개선 방법
- 데이터 프로파일링, 데이터 클리닝, 중복 제거, 이상치 감지 및 데이터 표준화 같은 기술과 도구를 사용하여 품질 검사
- 데이터 입력 및 수집 프로세스를 개선하여 데이터 품질을 유지하고 향상
데이터 보안
데이터 보안이란
- 데이터를 무단 액세스, 변조, 유출 또는 파괴로부터 보호하는 것을 의미
- 데이터 위협은 해커, 악성 코드, 내부 유출, 사회 공학 및 자연 재해와 같은 다양한 형태로 나타날 수 있음
- 데이터 유출로 인한 법적 문제 고려 필요
데이터 보안을 위한 방어적 조치
- 방어적 조치를 위해 암호화, 액세스 제어, 물리적 보안, 네트워크 보안, 모바일 기기 보안, 정책 및 교육 등이 포함
- 기업인 경우 데이터 보안 정책을 개발하고 직원 교육 및 보안 솔루션을 구현하여 데이터 보호를 강화해야 함
Data Sampling
1. Data Sampling이란?
- 큰 데이터 집합에서 작은 부분 집합을 추출하는 프로세스
- 통계 및 데이터 분석 분야에서 사용되는 일반적인 기술로, 데이터의 일부를 조사하고 전체 데이터 집합에 대한 결론을 도출하는데 활용 → 전체 데이터셋에 대한 통찰력을 얻거나 계산/저장 공간을 줄이는데 도움
목적
1. 자원 및 시간 절약: 전체 데이터 집합을 처리하거나 분석하는데 걸리는 시간과 자원을 절약. 대규모 데이터 집합에서 무작위로 추출된 샘플은 대부분의 데이터를 다루지 않아도 결과를 얻을 수 있음.
2.품질 향상: 데이터 샘플링은 데이터 품질을 향상시키는 데 도움. 이상치나 오류를 탐지하고 데이터 정제를 수행하기 위해 데이터의 작은부분을 확인.
3.통계적 추론: 데이터 샘플을 사용하면 통계적 추론을 수행. 추출된 샘플을 기반으로 모집단에 대한 통계적 추론을 수행하여 일반적인 패턴, 평균, 분포 등을 파악.
4.데이터 시각화: 데이터 샘플을 사용하여 데이터 시각화를 수행하면 데이터를 더 잘 이해하고 시각적으로 표현할 수 있음. 이를 통해 패턴, 관계 및 트렌드를 시각적으로 파악 가능.
5.데이터 테스트: 데이터 샘플링은 새로운 데이터 수집 및 분석 기술의 테스트와 실험에 유용. 더 많은 데이터를 수집하기 전에 시스템 및 알고리즘을 테스트 가능.
2. Data Sampling 종류
Random Sampling
- 무작위로 데이터 집합에서 샘플을 선택하는 방법
- 각 데이터 포인트가 선택될 확률은 동일하며, 편향이 적게 대표성 있는 샘플을 얻을 수 있음
Stratified Sampling
- 데이터를 계층적으로 분류한 후, 각 계층에서 샘플을 추출하는 방법
- 각 계층의 특성을 고려하여 샘플을 얻기 위해 사용
- 예를 들어, 남성과 여성의 성별에 따라 샘플을 추출할 때 사용
Cluster Sampling
- 데이터를 여러 그룹 또는 cluster로 나누고, 몇 개의 cluster를 무작위로 선택한 후 선택된 cluster 내의 모든 데이터를 포함하는 방법
- 데이터가 고루 분포되지 않은 경우에 유용
- 데이터가 클러스터로 그룹화 될 때 사용
Weight Sampling
- 데이터 포인트에 가중치를 할당하고 이러한 가중치를 기반으로 샘플을 추출하는 방법
- 데이터 포인트에 할당된 가중치는 해당 데이터 포인트의 중요성을 나타내며, 중요한 데이터는 더 자주 선택될 가능성이 높음
- 불균형 데이터 분포를 가진경우 잘 활용됨 이상치 탐지나 희귀 이벤트 분석과 같이 minor class data가 매우 적은 경우
Importance Sampling
- 확률 분포에 기반한 통계 샘플링 기법
- 베이지안 추론, 몬테 카를로 시뮬레이션, 결합 확률 분포의 추정 등
3. Data Sampling 고려사항
편향과 오차 관리
- 특정 데이터 세트에 대한 과소 또는 과대 표현이 일어나지 않도록 Sampling을 선정
- Sampling 과정 속에서 무작위성에 의한 변동이 많지 않도록 Sampling을 선정
Data Sampling 샘플 크기 및 신뢰 수준
- Data Sampling 에서 샘플 크기와 신뢰 수준은 중요한 결정 사항
- 통계적 방법을 사용하여 샘플 크기 및 신뢰 수준을 설정
- 예를 들어, 모집단의 크기, 표본 분포의 변동성, 희귀 사건의 발생률 및 원하는 신뢰 수준 등을 고려해서 샘플 크기를 선정할 수 있음

이기적이타주의자