Labeling 이란
- 라벨링 혹은 레이블링이라 불림
- 특정 객체에 의미를 부여하는 프로세스
Data Labeling
- 기계 학습 및 딥러닝 모델을 훈련하기 위해 필요한 데이터에 의미를 부여하는 과정
- 데이터에 주석 을 달거나 레이블 을 지정하여 의미를 부여하는 과정
- 이를 통해, 모델이나 컴퓨터가 데이터를 이해하고 원하는 작업을 수행할 수 있도록 돕는 중요한 단계 → 컴퓨터가 데이터를 처리하고 해석할 수 있는 방식으로 데이터를 변환하는 작업

Data Labeling 예시
이미지, 텍스트, 오디오 데이터의 Labeling 예시
Image Labeling
- 객체 인식, 세그멘테이션, 특징 포인트 지정, 이미지 분류 등의 다양한 작업에서 필요로 함
- 개와 고양이 이미지를 Labeling하여 모델이 이 두 동물을 구별 할 수 있도록 함
Text Labeling
- 텍스트 분류, 감정 분석, 주관적 의견 분석, 키워드 추출 및 개체명 인식
- 텍스트 문서에 글의 주제, 감정, 주요 키워드 등을 Labeling하여 모델이 텍스트를 이해하도록 도움
Audio Labeling
- 음성 인식, 음악 분류, 화자 인식
- Audio에 발화된 단어, 음악 트랙의 장르, 음성 신호의 특징을 Labeling하여 모델이 오디오를 이해하도록 도움
다양한 도메인의 Labeling Data
의료 분야
- 의료 영상 데이터의 Labeling
- 종양 발견, 질병 분류 및 환자 정보 관리에 사용
자연어 처리 NLP
- Text Labeling
- 텍스트 분류, 기계 번역, 자동 질문 응답 시스템에서 활용
자율 주행 자동차
- 센서 데이터 라이다, 카메라 의 Labeling
- 도로 상황 이해 및 자율 주행일 지원
환경 모니터링
- 환경 데이터 Labeling
- 환경 상태 모니터링 및 예측
Labeling과 AI 모델 학습 유형
Supervised Learning
- Data에 모든 Labeling이 존재한 상태에서의 Learning 방식
Semi Supervised Learning
- 일부 Data만 Labeling이 존재하며, 나머지는 Labeling이 존재하지 않는 상황에서의 Learning 방식
Self Supervised Learning
- Data에 모든 Labeling이 존재하지 않으며, 모델이 스스로 학습할 수 있도록 설계된 Learning 방식
Supervised 학습과 Labeling
Supervised Learning
- 모델은 Labeling된 데이터를 기반으로 학습하여, 이후 새로운 입력 데이터에 대한 예측을 수행할 수 있음
- 모델은 Labeling된 데이터를 활용하여 데이터 패턴을 학습
Classification and Regression
- Classification : 데이터를 여러 클래스 또는 범주로 분류하는 작업을 수행. 예를 들어, 스팸과 정상 이메일을 구분하는 문제 해결
- Regression : 연속적인 출력 값을 예측하는 작업을 수행. 예를 들어, 주택 가격 예측과 주식 가격 예측 등의 문제 해결
Semi Supervised Learning
Semi Supervised
- 일부 데이터만 Labeling 되고 나머지는 Labeling이 없는 상황에서의 Learning
- 모델은 Labeling된 데이터를 통해 스스로 특징을 학습하고, 그 특징을 활용하여 Label이 없는 데이터를 예측
Self Training
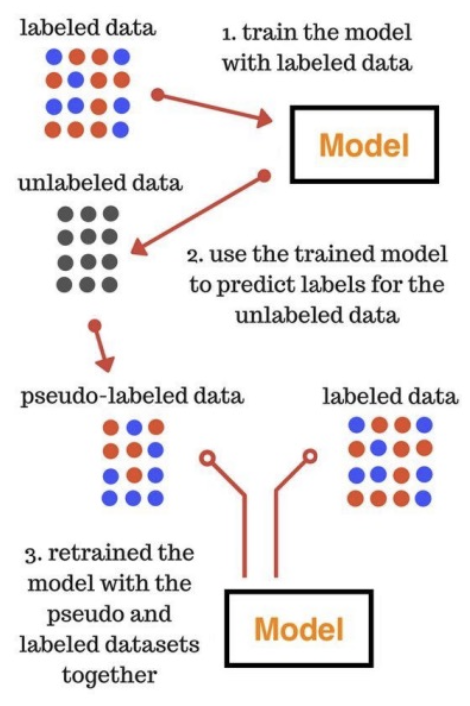 출처: Introduction to semi supervised learning. Synthesis lectures on artificial intelligence and machine learning 3.1 2009: 1 130, Zhu Xiaojin
출처: Introduction to semi supervised learning. Synthesis lectures on artificial intelligence and machine learning 3.1 2009: 1 130, Zhu Xiaojin
초기에 Labeling된 데이터로 모델을 훈련한 후, 모델이 높게 예측한 Labeling없는 데이터에 적용하여 Labeling을 하고 모델을 학습하는 과정을 반복
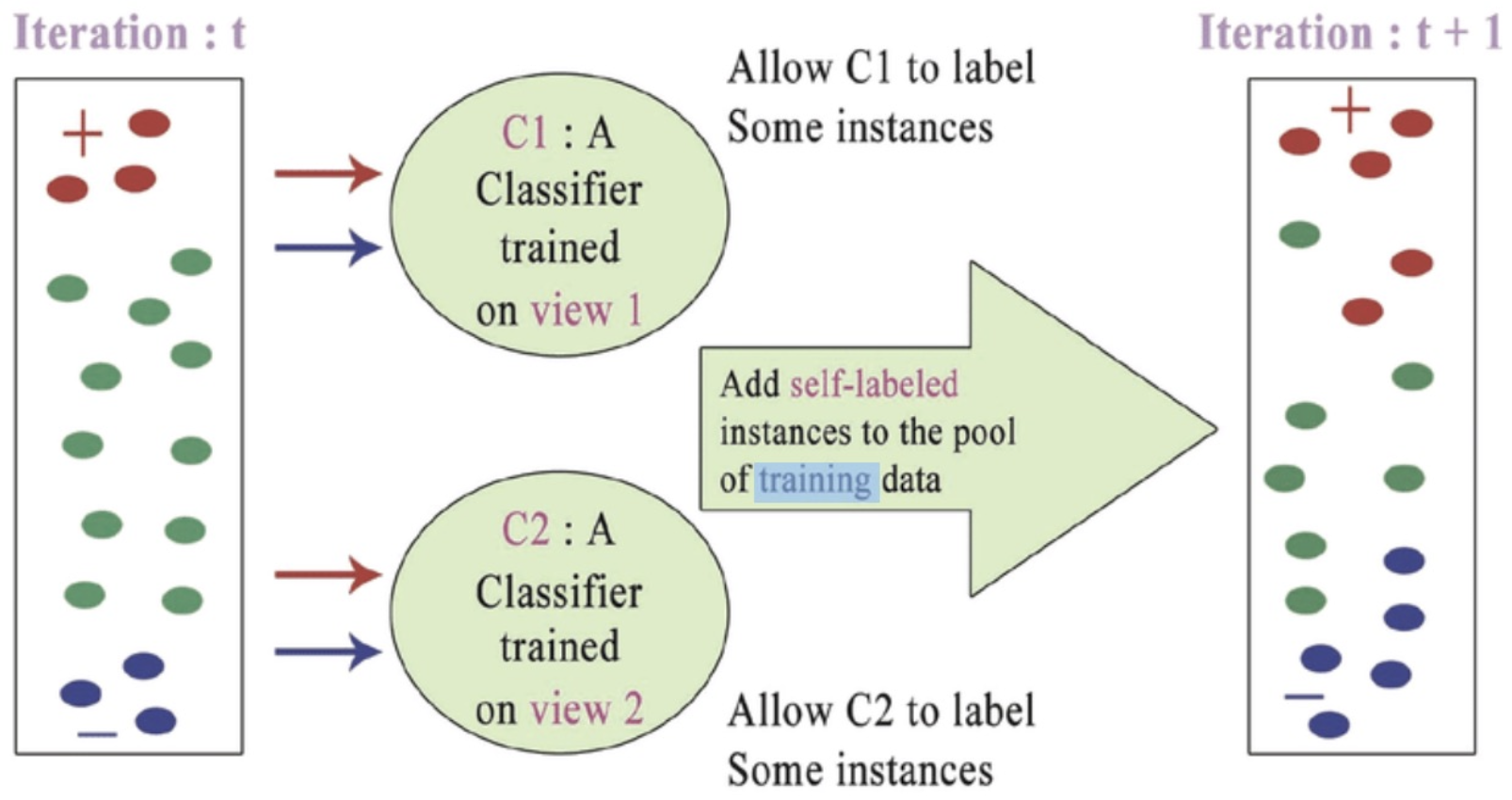
Co Training
 출처: A. review of various semi supervised learning models with a deep learning and memory approach, J. Bagherzadeh
출처: A. review of various semi supervised learning models with a deep learning and memory approach, J. Bagherzadeh
- 데이터를 여러 독립적인 부분 집합 또는 도메인으로 나누어 모델을 학습하여, semi supervised 학습에서의 데이터 부족 문제를 해결
- 초기 데이터 : 데이터를 여러 부분을 나눔 텍스트 데이터를 다른 문장이나 문서를 별도의 부분으로 나눔
- 초기 모델 : 독립된 모델을 각 부분 데이터에 대해 각 각 학습. 모델 A는 하나의 관점 부분 으로 학습하고, 모델 B는 다른 관점 부분 으로 학습
- 정보 교환 : 모델 A와 모델 B가 각 자 학습한 결과물을 공유하며 서로의 예측을 보완
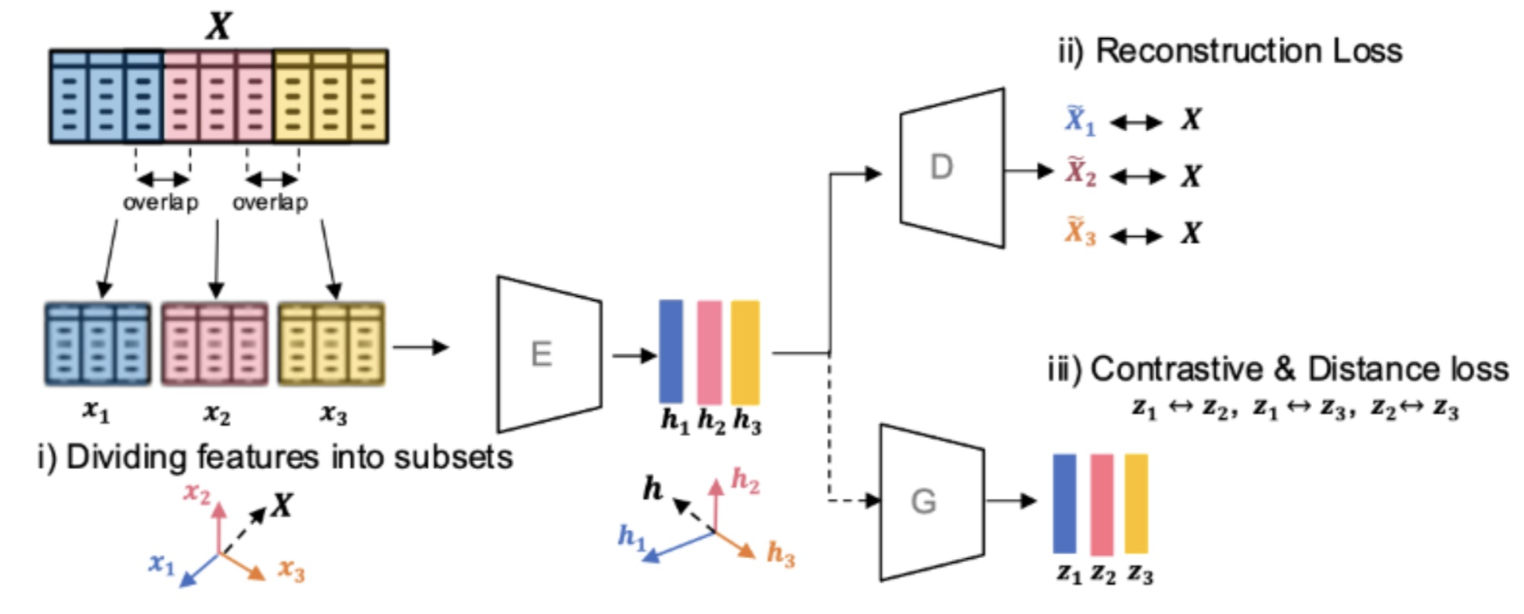
Multi view Learning
- 데이터를 여러 다른 관점 또는 특성을 나누어 모델을 학습
- 데이터의 다양한 특성이 중요한 경우에 유용
- 데이터 분할 : 데이터를 여러 부분 또는 관점으로 분할 이미지 데이터를 픽셀 데이터와 색 공간 데이터로 분할
- 모델 학습 : 각 관점 또는 특성에 대해 별도의 모델을 학습
- 결합 : 각 관점에서 얻은 정보를 종합하여 모델을 결합
Self Supervised Learning
- Labeling된 데이터 없이도 모델을 훈련시키는 학습법
- 데이터 내에서 숨겨진 정보를 활용하여 모델을 학습
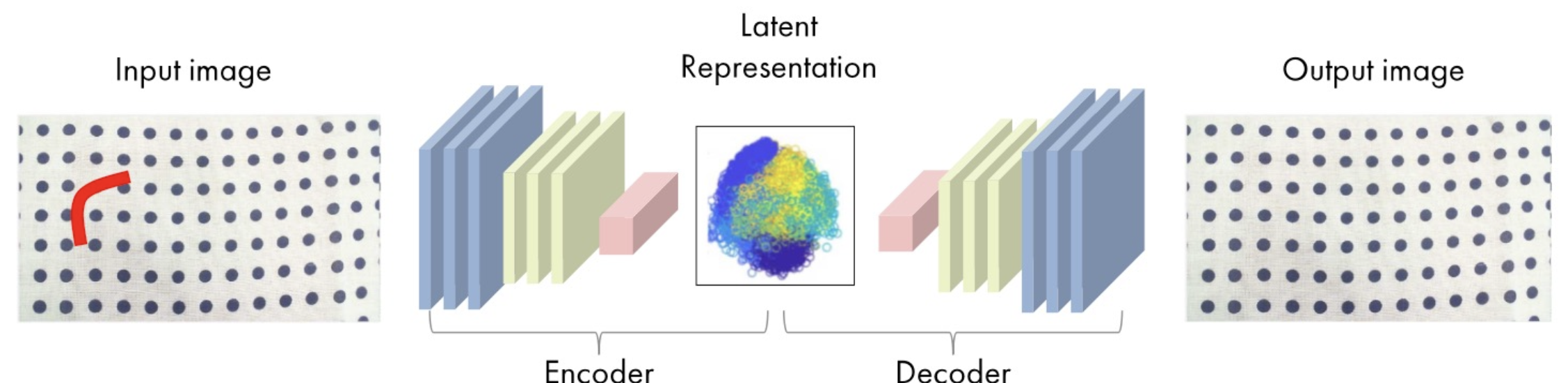
AutoEncoder
 출처: https://kr.mathworks.com/discovery/autoencoder.html
* 입력 데이터를 압축하고 다시 복원하는 네트워크 아키텍처로, Encoder와 Decoder로 구성
* 모델은 입력 데이터를 압축하고 복원하는 과정에서 정보를 학습
* 학습이 완료되면 Encoder의 중간 embedding특성 을 활용하여 다른 작업에 모델을 transfer 할 수 있음
## Masked Language Model
* 일부 단어를 가리고 해당 단어를 예측하는 Task를 활용
* 모델은 문맥을 이해하고 숨겨진 단어를 예측하기 위해 단어 간의 관계를 학습
* 자연어 처리 모델의 사전 훈련에 많이 쓰임
## Contrastive Learning
출처: https://kr.mathworks.com/discovery/autoencoder.html
* 입력 데이터를 압축하고 다시 복원하는 네트워크 아키텍처로, Encoder와 Decoder로 구성
* 모델은 입력 데이터를 압축하고 복원하는 과정에서 정보를 학습
* 학습이 완료되면 Encoder의 중간 embedding특성 을 활용하여 다른 작업에 모델을 transfer 할 수 있음
## Masked Language Model
* 일부 단어를 가리고 해당 단어를 예측하는 Task를 활용
* 모델은 문맥을 이해하고 숨겨진 단어를 예측하기 위해 단어 간의 관계를 학습
* 자연어 처리 모델의 사전 훈련에 많이 쓰임
## Contrastive Learning
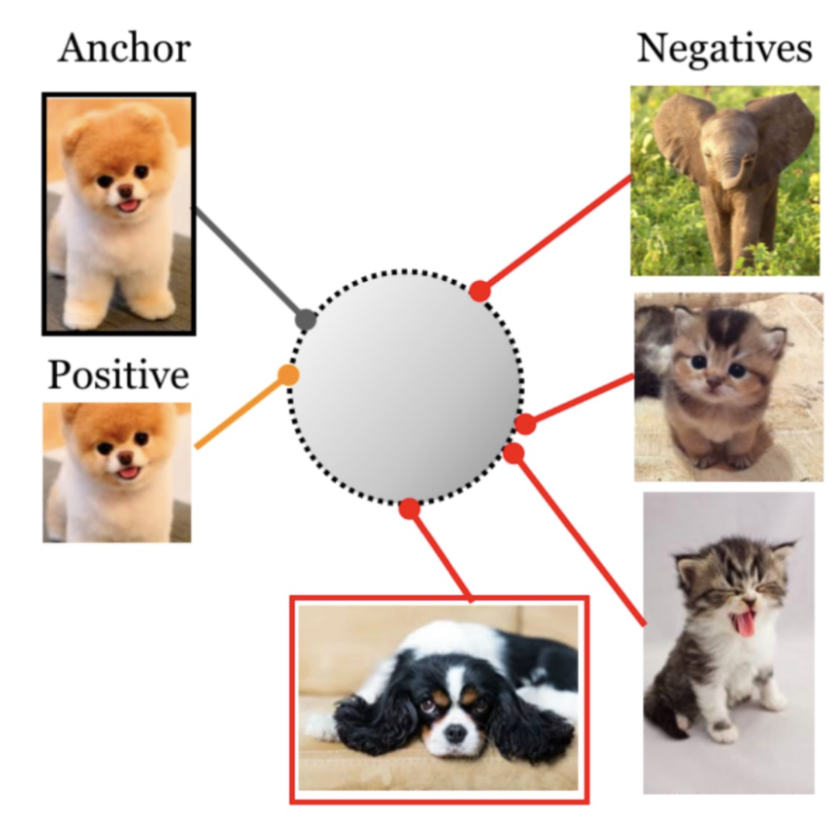 출처: https://blog.research.google/2021/06/extending contrastive learning to.html
출처: https://blog.research.google/2021/06/extending contrastive learning to.html
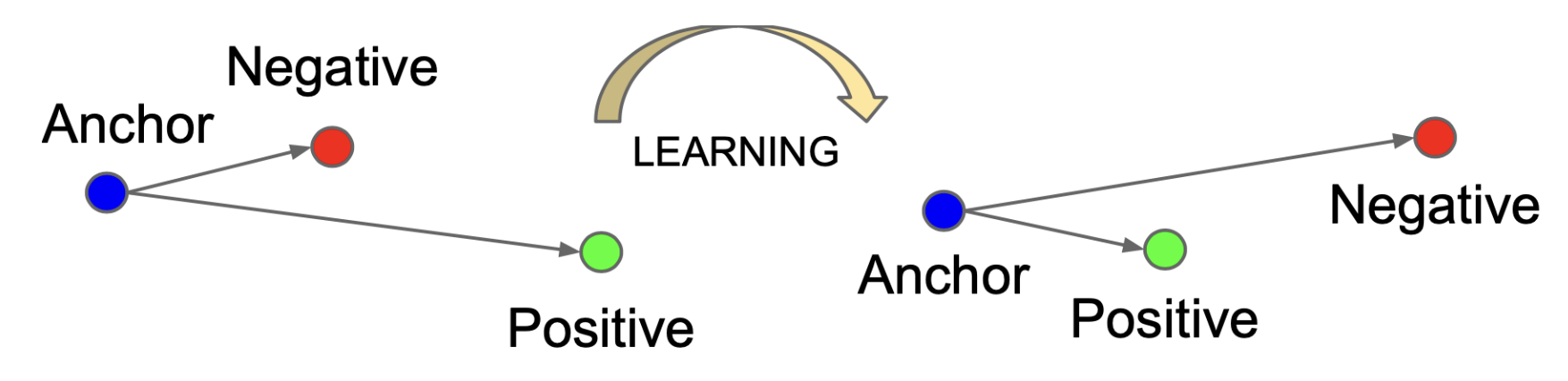 출처 : Contrastive Learning, Schroff et
출처 : Contrastive Learning, Schroff et
- 모델에게 유사한 데이터는 가깝게, 다른 데이터는 멀게 표현하도록
학습시키는 방법 - 모델은 데이터간의 유사성을 학습하여 서로 다른 예제를 구분하는 방법
Model 학습 유형
Transfer Learning
- 이미 훈련된 모델을 다른 작업에 적용하는 방법
- 사전 훈련된 모델은 대용량 데이터로 학습되어 다양한 특징을 추출하고, 이를 새로운 작업에 Transfer 하는데 사용
예시
- 이미지 분류 : 사전 훈련된 ResNet, VGG 모델을 의료 이미지 분류나 식물 종류 분류에 활용
- 자연어 처리 : GPT와 같은 모델에 자체적인 문서 분류, 감정 분석에 활용
Fine Tuning
- Transfer Learning의 한 형태로, 사전 학습된 모델을 새로운 작업에 맞게 미세 조정하는 과정
- 모델의 일부 레이어를 고정하거나 새로운 레이어를 추가하여 작업에 맞게 모델을 finetune
예시
- 이미지 분류 : 사전 훈련된 ResNet, VGG 모델을 의료 이미지 분류나 식물 종류 분류 데이터에 학습시켜, 빠르게 모델을 학습시키고 활용
- 자연어 처리 : GPT와 같은 모델에 자체적인 문서 분류, 감정 분석 데이터에 추가 학습시켜서 활용
Online Learning
- 데이터를 순차적으로 처리하면서 모델을 업데이트하는 방식
- 새로운 데이터가 도착할 때마다 모델을 finetune하며, 스트리밍 데이터나 지속적인 학습을 위해 유용
Batch Learning
- 데이터 셋을 한 번에 모델에 입력하는 전통적인 방식
모델 학습 유형 선택의 고려사항
- 데이터 양, 학습 시간, 모델 복잡성, 도메인 특성 등을 고려하여 적절한 전략을 선택해야 함
- 이와 같은 전략과 고려는 MLOps 에서도 지원되어야함

이기적이타주의자