
3.1 최적의 모델과 파라미터 찾기
3.1.1 사이킷런을 통해 학습과 예측에 사용할 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)특성공학(feature engineering)을 통해 유의미한 column을 구했고, 데이터에 사용하자.
X = df[['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Pregnancies_high', 'Age_low', 'Age_middle', 'Insulin_nan', 'low_glu_insulin']]
X.shape # (768, 9)y = df['Outcome']
y.shape # (768, )3.1.2 랜덤값을 고정하여 디시전트리로 학습과 예측하기
학습과 예측하기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=11, random_state=42)
model
y_predict = model.predict(X_test)
y_predict
diff_count = abs(y_predict - y_test).sum() # 28from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict) * 100 # 81.818181818183accuracy score를 구합니다. 지난 모델에서는 오버피팅이 발생한 것으로 예상할 수 있습니다.
3.1.3 최적의 max_depth 파라미터값 찾기
feature_names = X_train.columns.tolist()
from sklearn.tree import plot_tree
plt.figure(figsize=(15, 15))
tree = plot_tree(model, feature_names=feature_names, fontsize=10, filled=True)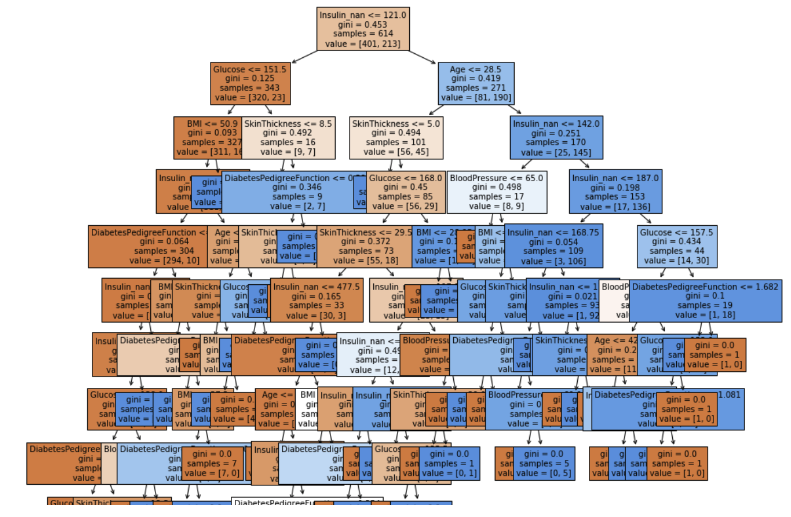
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=11, random_state=42)
modelmax_depth 값을 조정하기만 해도 성능이 좋아집니다. 너무 tree 깊이가 얕으면 언더피팅이 일어납니다.
최적의 max_depth 값 찾기
from sklearn.metrics import accuracy_score
for max_depth in range(3, 12):
model = DecisionTreeClassifier(max_depth=max_depth, random_state=42)
y_predict = model.fit(X_train, y_train).predict(X_test)
score = accuracy_score(y_test, y_predict) * 100
print(max_depth, score)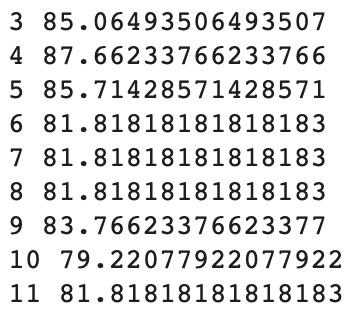
for문 안에 모델을 넣으면 max_depth 파라미터를 바꿔가면서 모델을 학습시킵니다.
다른 파라미터를 변경해도 성능이 향상될 수 있습니다.
3.1.4 GridSearchCV 를 사용해서 최적의 하이퍼 파라미터 값 찾기
Grid Search
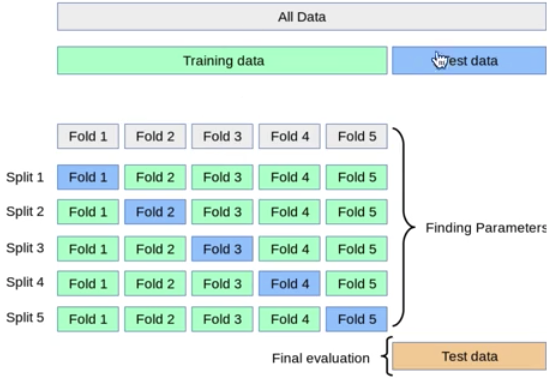
cross validation은 train 데이터셋을 여러 fold로 나눠서 평균을 내는 방법입니다.
from sklearn.model_selection import GridSearchCV
model = DecisionTreeClassifier(random_state=42)
param_grid = {"max_depth": range(3, 12),
"max_features": [0.3, 0.5, 0.7, 0.9, 1]}
clf = GridSearchCV(model, param_grid=param_grid, n_jobs=-1, cv=5, verbose=2)
clf.fit(X_train, y_train)param_grid에는 튜닝하고 싶은 파라미터 정보를 넣습니다.
max_features는 일부 feature만 사용하고 싶을 때 사용합니다. 1은 전체라는 뜻입니다.
n_jobs는 -1로 설정하여 사용 가능한 모든 장비를 학습에 이용합니다.
cv는 cross validation을 5개로 나눕니다.
verbose를 1로 하여 로그를 찍으면서 학습을 합니다. 0이면 로그를 출력하지 않습니다.
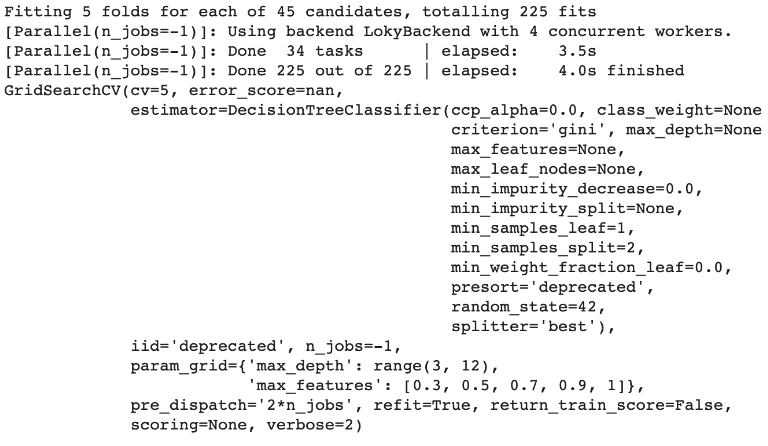
# 가장 성능이 좋은 파라미터를 찾아줍니다.
clf.best_params_ # {'max_depth': 5, 'max_features': 0.7}# 가장 좋은 성능을 내는 파라미터 조합 전체를 알려줍니다.
clf.best_estimator_ 
# 가장 좋은 점수를 알려줍니다.
clf.best_score_ # 0.8664934026389444pd.DataFrame(clf.cv_results_).sort_values(by="rank_test_score").head()cvresults는 cross validation 결과를 데이터프레임으로 반환합니다. score을 내림차순으로 확인할 수 있습니다.
clf.score(X_test, y_test) # 0.870122987012987013.1.5 RamdomSearchCV 를 사용해서 최적의 하이퍼 파라미터 값 찾기
Grid Search는 우리가 설정한 범위 안에서만 parameter을 탐색하지만
Random Search는 좋은 성능을 낼 수 있는 랜덤값을 탐색합니다.
max_depth = np.random.randint(3, 20, 10)
max_depth
max_features = np.random.uniform(0.7, 1.0, 100)
param_distributions = {"max_depth" :max_depth,
"max_features": max_features,
"min_samples_split" : list(range(2, 7))
}
param_distributionsparam_distributions을 정의하여 랜덤한 값을 넣습니다.
random_state는 값을 고정하는 역할을 합니다.
가장 좋은 파라미터를 찾게 됩니다.
from sklearn.model_selection import RandomizedSearchCV
clf = RandomizedSearchCV(model,
param_distributions,
n_iter=1000,
scoring="accuracy",
n_jobs=-1,
cv=5,
random_state=42
)
clf.fit(X_train, y_train)
param_distributions을 정의하여 랜덤한 값을 넣습니다.
random_state는 값을 고정하는 역할을 합니다.
가장 좋은 파라미터를 찾게 됩니다.
clf.best_params_ # {'min_samples_leaf': 4, 'max_features': 0.74150809045216909, 'max_depth': 5}