
전체 코드는 MLP + basic regularizaters 에서 확인할 수 있습니다.
DataLoader 정의
datasets = dataset_split(fashion_mnist_dataset, split=[0.9, 0.1])
print(datasets)
train_dataset = datasets["train"]
val_dataset = datasets["val"]
train_batch_size = 100
val_batch_size = 100
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=train_batch_size, shuffle=True, num_workers=1
)
val_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=val_batch_size, shuffle=False, num_workers=1
)DataLoader란?
파이토치의 공식 문서 에 따르면
데이터 샘플을 처리하는 코드는 지저분(messy)하고 유지보수가 어려울 수 있습니다; 더 나은 가독성(readability)과 모듈성(modularity)을 위해 데이터셋 코드를 모델 학습 코드로부터 분리하는 것이 이상적입니다. PyTorch는 torch.utils.data.DataLoader 와 torch.utils.data.Dataset 의 두 가지 데이터 기본 요소를 제공하여 미리 준비해둔(pre-loaded) 데이터셋 뿐만 아니라 가지고 있는 데이터를 사용할 수 있도록 합니다. Dataset 은 샘플과 정답(label)을 저장하고, DataLoader 는 Dataset 을 샘플에 쉽게 접근할 수 있도록 순회 가능한 객체(iterable)로 감쌉니다.
PyTorch의 도메인 특화 라이브러리들은 (FashionMNIST와 같은) 미리 준비해둔(pre-loaded) 다양한 데이터셋을 제공합니다. 데이터셋은 torch.utils.data.Dataset 의 하위 클래스로 개별 데이터를 특정하는 함수가 구현되어 있습니다. 이러한 데이터셋은 모델을 만들어보고(prototype) 성능을 측정(benchmark)하는데 사용할 수 있습니다. 여기에서 데이터셋들을 찾아볼 수 있습니다: 이미지 데이터셋, 텍스트 데이터셋 및 오디오 데이터셋
라고 합니다.
모델 정의
# Define Model
class MLP(nn.Module):
def __init__(self, in_dim:int, h1_dim:int, h2_dim:int, out_dim:int):
super().__init__()
self.linear1 = nn.Linear(in_dim, h1_dim)
self.linear2 = nn.Linear(h1_dim, h2_dim)
self.linear3 = nn.Linear(h2_dim, out_dim)
self.relu = F.relu
pass
def forward(self, input):
x = torch.flatten(input, start_dim=1)
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
out = self.linear3(x)
return out
class MLPWithDropout(MLP):
def __init__(self, in_dim:int, h1_dim:int, h2_dim:int, out_dim:int, dropout_prob:float):
super().__init__(in_dim, h1_dim, h2_dim, out_dim)
self.dropout1 = nn.Dropout(dropout_prob)
self.dropout2 = nn.Dropout(dropout_prob)
def forward(self, input):
x = torch.flatten(input, start_dim=1)
x = self.relu(self.linear1(x))
x = self.dropout1(x)
x = self.relu(self.linear2(x))
x = self.dropout2(x)
out = self.linear3(x)
return out모델 선언
model = MLP(28*28, 128, 64, 10)
# model = MLPWithDropout(28*28, 128, 64, 10, dropout_prob=0.3)
model_name = type(model).__name__
print(model_name)
# define loss
loss_function = nn.CrossEntropyLoss()
# define optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
max_epoch = 15
# define tensorboard logger
# 여러개를 돌릴 거기 때문에 로그 디렉토리를 관리하자.
log_dir = f"runs/{datetime.now()}-{model_name}"
writer = SummaryWriter(log_dir=log_dir)
log_interval = 100
# set save model path
log_model_path = os.path.join(log_dir, "models")
os.makedirs(log_model_path, exist_ok=True)텐서보드 살펴보기
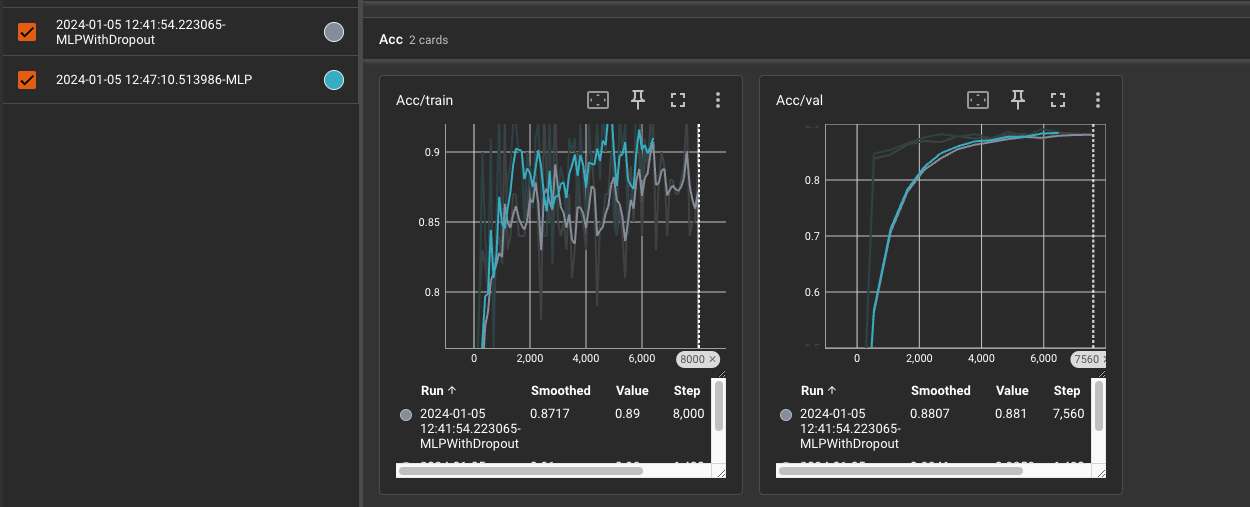
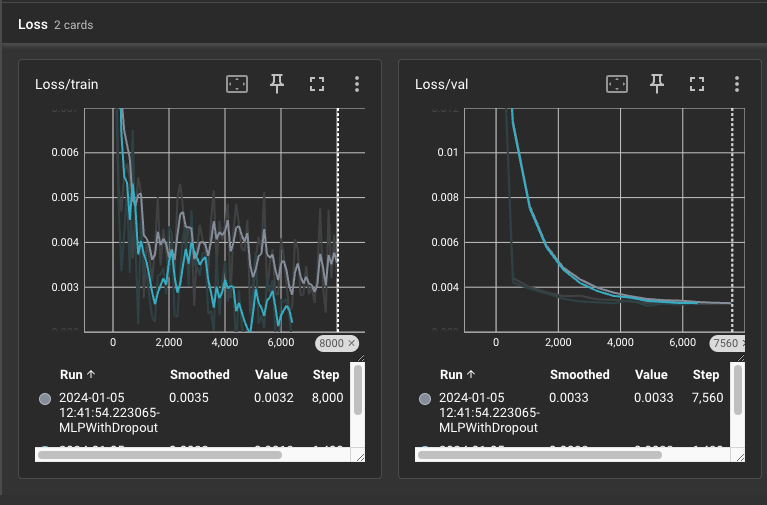

이기적이타주의자