데이터베이스를 기반으로 데이터를 학습시키는 방법
앞에서 다룬 머신러닝 프로그램은 데이터로 CSV 등의 텍스트 데이터를 많이 사용했으며 데이터베이스 (RDBMS)를 따로 사용하지 않았습니다.
하지만 실제로 업무에 사용되는 데이터는 데이터베이스에 들어 있는 경우가 많습니다.
따라서 머신러닝을 업무에서 사용하는 경우, 다음 그림의 사각형으로 둘러싸인 부분처럼 머신러닝 프 로그램이 업무 DB의 데이터를 추출하고 이 데이터를 사용해 학습하고 학습이 완료된 파일을 저장하는 경우가 많습니다.
(이미지)
업무 DB의 데이터를 사용해 머신러닝하는 경우의 구성
이번 절에서는 업무 DB에서 데이터를 추출하는 방법을 몇 가지 소개합니다. 그리고 키와 체중 데이터 베이스를 구축하고 데이터베이스를 활용한 머신러닝 시스템을 구축한 뒤 건강 진단 시스템을 만들겠습니다.
CSV로 출력하고 CSV를 머신러닝 시스템에 전달하기
이 책에서 다룬 대부분의 데이터는 쉼표와 줄 바꿈으로 구분된 텍스트 형식인 CSV였습니다. CSV 형 식은 데이터를 손쉽게 가공할 수 있으며, 읽어 들인 뒤 머신러닝 시스템에 전달할 수 있다는 장점이 있 습니다. 대부분의 데이터베이스와 엑셀처럼 테이블 형식으로 데이터를 저장하고 활용하는 도구는 CSV 형식으로 데이터를 출력하는 기능을 갖고 있습니다.
(이미지)
데이터베이스에서 CSV 파일로 출력하고 머신러닝 시스템에 전달하는 방법
이러한 방식을 사용할 때는 2장에서 소개한 것 처럼 Pandas 등의 라이브러리를 사용해 CSV 파일을 읽어 들이고 머신러닝 시스템에 전달하면 됩니다.
이때 주의할 점은 데이터베이스에서 CSV를 출력할 때와 읽어 들일 때 큰따옴표와 줄 바꿈 이스케이프 처리가 잘못돼서 데이터가 깨지는 것입니다. 따라서 데이터를 입출력할 때 CSV가 특수 문자를 어떻게 처리하는지 잘 확인해야 합니다. 또한 엑셀에서 데이터를 출력할 경우 디폴트로 문자 코드가 EUC-KR로 설정되니 주의해야 합니다.
정리하자면, 데이터베이스에서 CSV를 출력하고 이를 머신러닝 시스템에 전달하는 경우의 장점은 데이터를 쉽게 다룰 수 있다는 것입니다. 하지만 CSV 파일을 읽고 쓸 때 데이터가 깨지지 않게 주의해야 합니다.
데이터베이스에서 직접 머신러닝 시스템에 데이터 전달하기
Python은 유명한 데이터베이스를 대부분 지원합니다. Python은 풍부한 라이브러리를 가지고 있으며 여러 모듈을 조합해 사용할 수도 있습니다. 따라서 데이터베이스에서 직접 머신러닝 시스템에 데이터 를 전달할 수 있습니다. 이 절에서는 이 방법을 사용해 예제를 만들겠습니다.
키와 체중 데이터베이스 만들기
병원의 건강 검진 데이터를 기반으로 머신러닝을 사용한 검진 결과 출력 시스템을 만든다고 가정해 봅시다.
키와 체중 데이터는 매일 추가됩니다. 이 데이터를 사용해 머신러닝 모델을 구축하고 새로운 진단 결과에 사용해 봅시다.
(이미지)
키와 체중 데이터베이스를 활용한 진단 시스템 구축
- 새로운 키와 체중을 데이터베이스에 추가하는 프로그램
- 데이터베이스의 값을 머신러닝 시스템에 학습시키는 프로그램
- 키와 체중을 입력하면 진단 결과를 출력하는 프로그램
추가로 이번 장에서는 간단하게 사용할 수 있는 데이터베이스(RDBMS)인 SQLite를 사용하겠습니다. SQLite는 Python 표준 라이브러리로 사용할 수 있으므로 별도의 모듈을 설치하거나 데이터베이스 서버를 설정할 필요가 없습니다.
SQLite로 키와 체중 데이터베이스 만들기
이번에 만들 키와 체중 데이터 베이스는 키, 체중, 체형이라는 3개의 필드를 갖습니다.
| 열 | 필드 설명 | 필드 이름 |
|---|---|---|
| 0 | 고객 ID(자동으로 추가) | id |
| 1 | 키(cm) | height |
| 2 | 체중(kg) | weithg |
| 3 | 체형(0~5의 값) | typeNo |
아울러 체형을 다음과 같은 6단계로 구분합니다. 관리하기 쉽게 숫자로 나타냅니다.
| 값 | 체형 |
|---|---|
| 0 | 저체중 |
| 1 | 표중 체중 |
| 2 | 비만(1도) |
| 3 | 비만(2도) |
| 4 | 비만(3도) |
| 5 | 비만(4도) |
그럼 데이터베이스를 생성합시다. 다음 코드는 데이터베이스를 만들고 내부에 person이라는 이름의 테이블을 생성합니다.
# init_db.py
import sqlite3
dbpath = "./hw.sqlite3"
sql = '''
CREATE TABLE IF NOT EXISTS person (
id INTEGER PRIMARY KEY,
height NUMBER,
weight NUMBER,
typeNo INTEGER
)
'''
with sqlite3.connect(dbpath) as conn:
conn.execute(sql)프로그램을 실행하면 'hw.sqlite3'이라는 데이터베이스 파일이 생성됩니다. RDBMS는 SQL을 사용해 데이터베이스를 조작합니다. 'CREATE TABLE'을 사용하면 테이블을 만들 수 있습니다.
Python에서 sqlite3.connect()라고 작성하면 데이터베이스에 연결되며 execute() 메서드를 사용해 SQL 구문을 실행합니다.
새로운 키와 체중을 데이터베이스에 추가하기
이어서 새로운 키, 체중, 체형 데이터를 100개 추가하는 프로그램을 만들어 봅시다. 다음 프로그램을 실행하면 100개의 키, 체중, 체형 데이터가 데이터베이스에 삽입됩니다.
# insert_db.py
import sqlite3
import random
dbpath = "./hw.sqlite3"
def insert_db(conn):
# 더미 데이터 만들기 --- (*1)
height = random.randint(130, 180)
weight = random.randint(30, 100)
# 더미 데이터를 기반으로 체형 데이터 생성하기 --- (*2)
type_no = 1
bmi = weight / (height / 100) ** 2
if bmi < 18.5:
type_no = 0
elif bmi < 25:
type_no = 1
elif bmi < 30:
type_no = 2
elif bmi < 35:
type_no = 3
elif bmi < 40:
type_no = 4
else:
type_no = 5
# 데이터베이스에 저장하기 --- (*3)
sql = '''
INSERT INTO person (height, weight, typeNo)
VALUES (?,?,?)
'''
values = (height,weight, type_no)
print(values)
conn.executemany(sql,[values])
# 100개의 데이터 삽입하기
with sqlite3.connect(dbpath) as conn:
# 데이터 100개 삽입하기 --- (*4)
for i in range(100):
insert_db(conn)
# 확인하기 --- (*5)
c = conn.execute('SELECT count(*) FROM person')
cnt = c.fetchone()
print(cnt[0])프로그램을 실행해 봅시다. SQL INSERT 구문이 실행되며 100개의 데이터가 데이터베이스에 추가되는 것을 확인할 수 있습니다.
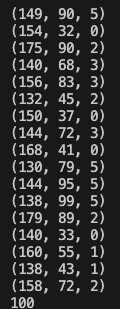
그럼 프로그램의 내용을 자세하게 확인해 봅시다. 프로그램의 (1) 부분에서는 랜덤하게 키와 체중을 결정합니다. (2) 부분에서는 키와 체중 데이터를 기반으로 체형 데이터를 계산합니다. 이때 비만도 판정에 BMI 공식을 사용했습니다. BMI 공식은 다음과 같습니다. BMI가 22정도일 때가 표준 체중입니다.
bmi 값이 18.5 미만이라면 '0: 저체중', 25 미만이라면 '1: 표준 체중', 30 미만이라면 '2: 비만(1도)', 35 미만이라면 '3: 비만(2도)', 40 미만이라면 '4: 비만(3도)', 그 이상은 '5: 비만(4도)'로 판정됩니다.
프로그램의 (*3) 부분에서는 INSERT 구문을 실행해 생성한 키, 체중, 체형 데이터를 데이터베이스에 삽입합니다.
프로그램의 (4) 부분에서는 100회 데이터를 생성해 데이터베이스에 삽입하게 지시하고 (5) 부분에 서는 데이터베이스에 들어 있는 전체 행 수를 출력합니다.
정말로 추가됐는지 확인할 수 있게 삽입한 데이터 목록을 출력해 봅시다.
# select_db.py
import sqlite3
dbpath = "./hw.sqlite3"
select_sql = "SELECT * FROM person"
with sqlite3.connect(dbpath) as conn:
for row in conn.execute(select_sql):
print(row)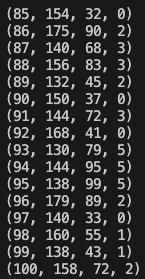
100개의 키와 체중 데이터가 삽입된 것을 확인할 수 있습니다.
키, 체중, 체형 학습하기
그럼 키, 체중, 체형 데이터를 학습해 봅시다.
# make_model.py
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
in_size = 2 # 체중과 키를 입력으로
nb_classes = 6 # 체형은 6단계로 구별
# MLP모델의 구조 정의하기
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size,)))
model.add(Dropout(0.5))
model.add(Dense(nb_classes, activation='softmax'))
# 모델 컴파일하기
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
model.save('hw_model.h5')
print("saved")딥러닝 모델을 구축하고 컴파일해서 파일로 저장하는 프로그램
코드를 실행하면 'hw_model.h5'라는 학습된 가중치 파일이 만들어집니다. 굉장히 간단한 MLP 모델을 정의했습니다. 이 모델을 학습해 봅시다.
아래는 최신 100개의 데이터를 데이터베이스에서 추출해 학습하는 프로그램입니다.
# mlearn.py
import keras
from keras.models import load_model
from keras.utils.np_utils import to_categorical
import numpy as np
import sqlite3
import os
# 데이터베이스에서 데이터 100개 읽어 들이기 --- (*1)
dbpath = "./hw.sqlite3"
select_sql = "SELECT * FROM person ORDER BY id DESC LIMIT 100"
# 읽어 들인 데이터를 리스트에 추가하기 --- (*2)
x = []
y = []
with sqlite3.connect(dbpath) as conn:
for row in conn.execute(select_sql):
id, height, weight, type_no = row
# 데이터를 정규화하기 --- (*3)
height = height / 200
weight = weight / 150
y.append(type_no)
x.append(np.array([height, weight]))
# 모델 읽어 들이기 --- (*4)
model = load_model('hw_model.h5')
# 이미 학습 데이터가 있는 경우 읽어 들이기 --- (*5)
if os.path.exists('hw_weights.h5'):
model.load_weights('hw_weights.h5')
nb_classes = 6 # 체형은 6단계로 구별
y = to_categorical(y, nb_classes) # One-hot 벡터로 변환하기
# 학습하기 --- (*6)
model.fit(np.array(x), y,
batch_size=50,
epochs=100)
# 결과 저장하기 --- (*7)
model.save_weights('hw_weights.h5')프로그램을 실행하면 학습된 가중치 파일 hw_weights.hs'가 생성됩니다.
프로그램을 확인해 봅시다. 프로그램의 (※1) 부분에서는 SQLite 데이터베이스에서 최신 데이터 100 개를 추출하는 SELECT 구문을 작성했습니다. (※2) 부분에서는 실제로 데이터베이스에서 데이터를 추 출합니다. execute 구문을 실행하고 그 결과를 for 구문에 넣으면 데이터베이스에서 차례대로 값을 추출할 수 있습니다.
프로그램의 (※3) 부분에서는 학습 전용 데이터를 지정할 때 키와 몸무게를 0~1의 범위가 되게 적당한 값으로 정규화한 뒤 리스트에 추가합니다. (※4) 부분에서는 학습한 모델을 읽어 들입니다. (※5) 부분 에서는 이미 학습된 가중치 데이터가 있는 경우 그것을 읽어 들입니다. (※6) 부분에서는 데이터를 학 습하고 (※7) 부분에서 학습 결과를 파일로 저장합니다.
Keras의 fit 메서드는 새로운 데이터를 추가로 학습할 수 있음
Keras의 model.fit() 메서드를 호출하면 데이터가 학습됩니다. 그런데 이미 학습된 데이터가 있는 상태에서 model.fit()을 호출하면 이전에 학습된 결과에 추가로 새로운 데이터가 학습됩니다. 이전 학습 이 리셋되는 것이 아니라 새로운 데이터와 대응하며 관련 매개변수를 수정하는 형태입니다.
정답률 확인하기
그럼 학습 상황을 확인해 봅시다. 다음 프로그램을 실행하면 임의의 체중에 대한 결과를 출력할 수 있 습니다. 이는 학습 모델과 학습된 가중치 데이터를 읽어 들이고 임의의 데이터를 테스트하는 프로그램입니다.
# my_checker.py
from keras.models import load_model
import numpy as np
# 학습하기모델 읽어 들이기 --- (*1)
model = load_model('hw_model.h5')
# 학습한 데이터 읽어 들이기 --- (*2)
model.load_weights('hw_weights.h5')
# 레이블
LABELS = [
'저체중', '표준 체중 ', '1비만(1도)',
'비만(2도)', '비만(3도)', '비만(4도)'
]
# 테스트 데이터 지정하기 --- (*3)
height = 160
weight = 50
# 정규화하기 --- (*4)
test_x = [height / 200, weight / 150]
# 예측하기 --- (*5)
pre = model.predict(np.array([test_x]))
idx = pre[0].argmax()
print(LABELS[idx], '/ 가능성', pre[0][idx])이 프로그램을 실행해 봅시다. 키 160cm, 체중 50kg은 '표준 체중'이어야 맞지만 '저체중'이라고 잘못된 값이 출력되는 것을 볼 수 있습니다. 사실 100개의 데이터만 입력했으므로 어떻게 보면 틀리는게 당연하다고 할 수 있습니다.
(이미지)
그럼 계속해서 체중 데이터를 데이터베이스에 삽입하는 프로그램 'insert_db.py'와 데이터를 학습하는 프로그램 'mlearn.py'를 번갈아 가며 반복 실행해서 5000개 정도의 데이터를 학습시켜 봅시다.
이때 여러번 실행하는 것이 귀찮다면 한 번에 5000개의 데이터를 삽입하고 학습하게 코드를 수정하기 바랍니다. 물론 학습 데이터가 더 많으면 더 높은 정답률이 나올 것 입니다.
그리고 다시 'my_checker.py'를 실행해 봅시다. 실행하면 제대로 된 진단 결과가 출력되는 것을 볼 수 있습니다.
프로그램을 확인해 봅시다. 프로그램의 (※1) 부분에서 학습 모델을 읽어 들이고 (x2) 부분에서 학습 된 가중치 데이터를 읽어 들입니다. (※3) 부분에서는 테스트 데이터를 지정합니다.
그리고 프로그램의 (※4) 부분에서 0~1 범위로 데이터를 정규화하고 (※5) 부분에서 predict() 메서드 를 호출하면 진단 결과를 예측하고 결과를 출력합니다.
분류 정답률 확인하기
1만개의 데이터를 학습하고 결과가 어떤지 실제 BMI 공식을 기반으로 만든 데이터로 분류 정답률을 테스트해 봅시다. 다음 프로그램을 실행하면 분류 정답률을 확인할 수 있습니다.
# check_text.py
from keras.models import load_model
import numpy as np
import random
from keras.utils.np_utils import to_categorical
# 학습하기모델 읽어 들이기 --- (*1)
model = load_model('hw_model.h5')
# 학습한 데이터 읽어 들이기 --- (*2)
model.load_weights('hw_weights.h5')
# 정답 데이터를 1000개 만들기 --- (*3)
x = []
y = []
for i in range(1000):
h = random.randint(130, 180)
w = random.randint(30, 100)
bmi = w / ((h / 100) ** 2)
type_no = 1
if bmi < 18.5:
type_no = 0
elif bmi < 25:
type_no = 1
elif bmi < 30:
type_no = 2
elif bmi < 35:
type_no = 3
elif bmi < 40:
type_no = 4
else:
type_no = 5
x.append(np.array([h / 200, w / 150]))
y.append(type_no)
# 형식 변환하기 --- (*4)
x = np.array(x)
y = to_categorical(y, 6)
# 정답률 확인하기 --- (*5)
score = model.evaluate(x, y, verbose=1)
print("정답률=", score[1], "손실 =", score[0])
(이미지)
1만개이ㅡ 데이터 분류 정답률은 0.97(97%)입니다. 꽤 높은 정답률입니다. 참고로 3만 개의 데이터를 학습시키면 0.98(98%) 정도 나옵니다.
개선사항
데이터베이스에서 최근 100개의 데이터를 추출하고 재학습하게 구성돼 있습니다. 실제로 데이터 변경 처리를 하는 경우 이전 실행에서 마지막에 학습한 데이터베이스에 ID를 기억해 그 이후의 데이터만 학습하게 하는 방법을 활용하면 좋습니다.
