Layout-and-Retouch: A Dual-stage Framework for Improving Diversity in Personalized Image Generation
Abstract
personalized text to image(P-T2I)생성은 몇 개의 참조 이미지를 통해 개인화된 주제를 담은 새로운 이미지를 텍스트에 따라 생성하는 것을 목표로 한다. 그러나 텍스트의 정확성과 identity preservation 사이의 균형을 맞추는 것은 여전히 중요하다. 이 문제를 해결하기 위해 논문에서 Layout-and-Retouch라는 새로운 P-T2I 방법을 제안한다.
💡새로운 아이디어
비 개인화된 부분(배경이나 의상)과 목표 주제의 정체성을 분리하여 두 단계로 구조화하는 것
Introduction
[Stage-1] Layout Generation
- 정체성 보존을 고려하지 않고 텍스트 충실도를 향상시키는 데에 중점을 둠
- step-blended inference를 사용해 T2I모델의 내재된 샘플 다양성을 활용
- 다양한 레이아웃 이미지 생성+ 텍스트의 정확성 향상
[Stage-2] Retouch
- 레이아웃 이미지에서 배경 컨텍스트를 보존하면서 목표 주제를 정확히 조정하는것이 핵심
- multi-source attention swapping을 통해 첫 번째 단계에서 얻은 컨텍스트 이미지와 참조 이미지를 통합
- 컨텍스트 이미지의 구조를 활용 & 이미지에서 시각적 특징 추출->텍스트의 정확성을 유지하면서 정체성 특징을 보존
Proposed Methods
Preliminaries
Latent diffusion model.
Stable Diffusion은 pretrained된 autoencoder를 사용하여 latent space내에서 노이즈 제거 과정을 수행함으로 효율적인 이미지를 생성한다.
구체적으로 pretrained된 인코더는 이미지를 latent representation 로 압축하고 이후 조건부 확산 모델 를 사용하여 확산 및 반복적인 노이즈 제거 단계를 진행한다.
논문에서는 Stable Diffusion을 기반으로 모델을 개발했다.
Latent diffusion model은 time-conditional U-net backbone을 사용하며, 이는 여러개의 self-attention layer를 가지고 있다.
attention mechanism은 다음과 같다.
Pre-training personalized model.
personalized 모델을 훈련하려면, 목표 개념을 설명하는 개의 참조 이미지 집합 이 필요하다. 이전 연구에서는 네트워크의 일부 또는 전체를 미세 조정하여 특정 개념을 학습했다. 그리고 훈련 후에는 "<>"와 같은 특수 텍스트 토큰을 사용해 personalized된 정보를 표현하고, 추가 텍스트와 결합했다. 하지만 훈련 이미지가 충분하지 않을 경우 과적합의 위험이 있었다.
본 논문에서는 pretrained personalized 모델이 다양한 이미지를 생성하는 데 한계가 있다고 관찰했다. 따라서 이번 연구에서는 특수 텍스트 토큰을 포함한 텍스트 조건을 로, 특수 텍스트 토큰이 제거된 조건을 로, 그리고 개념만 포함된 중립 텍스트 조건을 로 정의한다.
Layout-and-Retouch Framework
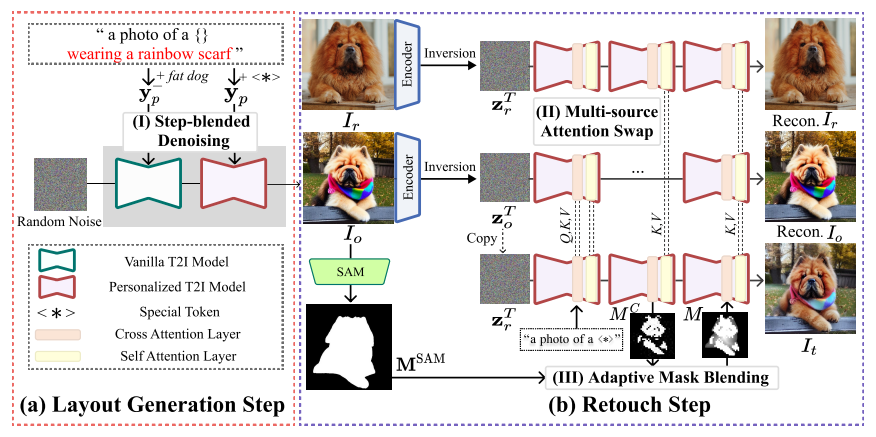
논문의 목표는 참조 이미지 와 해당 텍스트 조건 가 주어졌을때, 텍스트 조건을 따르면서 의 외형을 유지하는 목표이미지 를 생성하는 것이다. 논문에서는 반복적인 레이아웃으로 훈련된 모델이 다양한 구성을 생성하는 능력을 제한한다고 가정한다. 이 문제를 해결하기 위해 Layout-and-Retouch 프레임 워크를 제안했다.
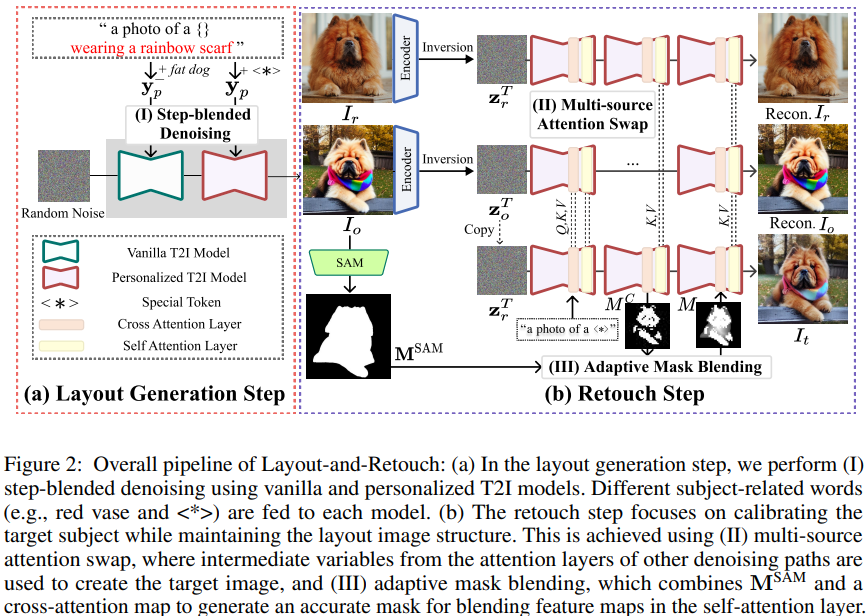
Stage 1 - Layout Generation
Step-blended denoising.
논문의 핵심 아이디어는 초기 단계에서 레이아웃을 생성하기 위해 Stable Diffusion(SD)의 표현력을 활용하는 것이다. 초기 레이아웃 생성 작업을 (SD)에 맡김으로 레이아웃의 범위와 표현력을 확장할 수 있다. SD는 개념에 대한 사전 지식이 없으므로, 텍스트 조건 을 사용한다. SD로 생성된 레이아웃은 pretrained P-T2I모델로 생성한 것 보다 훨씬 다양한다.
초기 레이아웃 생성은 경험적 연구를 바탕으로 단계에서 이루어진다.
단계에서 초기 레이아웃을 생성한 후 다음 단계에서는 초기 구조를 유지하면서 목표 주제에 시각적으로 맞도록 객체 외형을 조정한다. 이 과정에서는 와 개인화된 모델을 사용한다. 여기서 와 는 개인화된 denoising 네트워크를 나타내며, 는 각 노이즈 제거 단계 에서의 e latent representations을 의미한다. latent representations in step-blended denoising 수식은 다음과 같다.
Stage 2 - Retouch
Multi-source attention swap.
레이아웃 이미지 는 목표 주제의 시각적 특성을 일부 포착할 수 있지만, 세부 디테일이 부족하다. 세부 디테일을 개선하기 위해 와 참조이미지 을 사용하여 attention swap기술을 적용한다. 구체적으로 에서 파생된 attention swap과 self-attention모듈의 중간 변수들이 목표 이미지 의 denoising단계로 전달된다. attention swap모듈의 쿼리, 키, 값은 각각 로, self-attention모듈의 쿼리 키 값은 로 표시한다. 또한 텍스트 조건 을 사용하여 노이즈 제거 과정 전반에 걸쳐 목표 객체의 시각적 특성을 수정하는 데 집중한다.

Algorithm 1 은 리터칭 단계의 전체 과정을 설명한다. 목표 경로에서 노이즈를 제거하는동안 attention swaping은 나 룰 레이아웃이나 context경로로 부터 온 변수로 교체한다. 초기 단계에서는 레이아웃 경로에서 와 를 사용하여 목표 경로와 통합해 노이즈 이미지의 전체 구조를 구성한다. 이 공유는 가 의 구조를 느슨하게 따르게 하여 복제를 용이하게 한다. 이후 노이즈 제거 단계에서는 참조 경로의 가 목표 경로의 변수들을 교체해 참조 객체의 세부 특성을 주입한다. 추가로 composite foreground mask 은 의 latent 표현을 결합한다.
Adaptive mask blending.
목표 객체의 시각적 디테일을 개선하기 위해, 레이아웃 이미지와 참조 이미지의 latent 표현을 혼합하는 foreground mask를 생성한다. cross-attention 맵을 사용하여 이진 전경 마스크 를 만들고, 노이즈 문제를 해결하기 위해 Segment-Anything에서 생성된 이진 마스크 을 추가로 사용한다. Adaptive mask blending 기법으로 와 을 조합하여 노이즈를 줄이고 최종 latent표현은 self attention layer에서 가중합을 통해 생성된다.
여기서 는 거리를 사용하는 거리변환, Normalize는 값을 [0.5, 1.0]범위로 매핑하는 스케일링 작업, 는 지정된 볼륨 임계값 이하의 연결된 집합을 제거해 노이즈 픽셀 마스크 영역을 제거한다.

