
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
LeNet-5?
LeNet-5는 Yann LeCun이 1998년 발표한 논문에서 소개한 CNN 네트워크 구조입니다.
LeNet-5는 손글씨 인식을 할 때 기존 활용되던 Multilayer Neural Network의 한계를 극복하기 위해 CNN(Convolutional Neural NEtworks)을 활용한 모델입니다.
지금은 더 좋은 CNN 네트워크들이 많이 발표되었지만 CNN 네트워크들의 발전 흐름을 다시한번 복습하기 위해 간단히 정리해 보았습니다.
특징
LeNet 발표 전 활용되던 Fully-Connected Network는 2차원 이미지를 1차원으로 펼쳐진 데이터를 입력받았습니다. 이 때 이미지가 갖는 공간적인 정보(Topology)가 손실되는 문제가 있었습니다.
Yann LeCun은 Local receptive field, Shared weight, Sub-sampling의 개념을 결합하여 이 문제를 해결하려 하였습니다.
LeNet-1
LeNet-1은 1989년 제안되었으며 LeNet-5와 거의 유사한 구조를 가지고 있습니다.
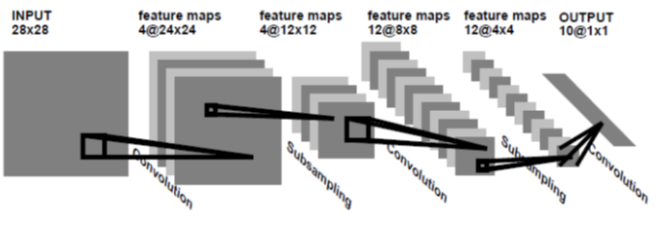
위 그림은 LeNet-1의 구조이며, 전체적으로 Convolutional layer + Pooling layer를 반복하면서 전역적으로 의미있는 특징을 찾아내는 현대 CNN 네트워크 기본 형태를 가지고 있음을 알 수 있습니다.
주목 할만한 특징들을 살펴 보면 아래와 같습니다.
1. Local receptive field의 개념을 활용하기 위해 5x5 Convolutional layer로 feature map을 생성
2. 전체 이미지가 같은 weight와 bias로 설정된convolutional kernel을 공유하는 shared weight개념을 적용
3. Layer를 거쳐가면서 전체 이미지에서 의미있는 영역에 집중하기 위해 Average Pooling Layer로 Subsampling
LeNet-5
Yann LeCun은 구조적으로 유사한 LeNet-4를 거쳐 최종적으로 LeNet-5를 발표하였습니다.
LeNet-5는 LeNet-1의 구조를 발전시킨 모델로 입력 이미지의 크기, feature-map의 개수 및 fully-connected layer의 크기에 변화가 있습니다.
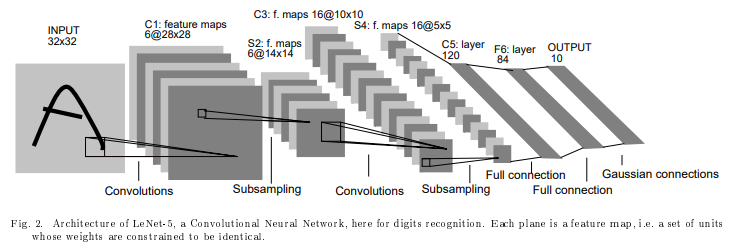
위 그림은 LeNet-5의 구조이며, Cx, Sx, Fx와 같은 기호로 구조를 설명하고 있습니다.
C는 convolution layer, S는 sub-sampling, F는 Fully-connected layer를 의미합니다.
뒤에 붙는 숫자는 전체 구조에서 몇 번째 layer인지를 의미합니다.
(예를들면 첫 번째 Convolution layer는 C1, 두 번째 sub-sampling은 S4)
먼저 입력 이미지의 크기가 32x32로 커졌습니다. 실제 문자 이미지는 28x28 크기로 이미지에서 중앙에 위치하고 있습니다. 실제 문자 이미지보다 큰 이유는 corner나edge와 같은 특징이receptive field의 중앙 부분에 나타나길 원하기 때문입니다.
구조적인 변화는 convolution layer를 통과 후 생성되는 feature map의 개수가 4개, 12개에서 6개 16개로 증가하였습니다.
또, Fully-connected layer의 개수가 3개로 증가하였습니다.
독특한 점은 두 번째 convolution layer(C3)을 통과할 때 6개 입력 으로부터 16개의 feature-map을 만들어 내는 부분입니다.
이때 6개 입력이 모든 16개 입력과 관여하지 않고 아래 테이블과 같이 선택적으로 활용됩니다.
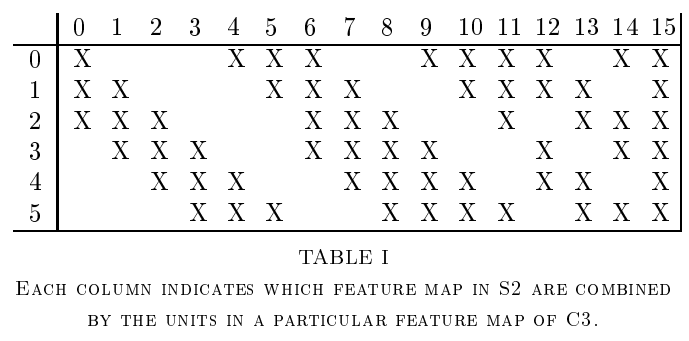
그 예시로 16개중 첫 번째 feature-map은 입력 6개중에 0, 1, 2 세개의 입력만 활용해 생성하고, 두 번째 feature-map은 6개 중 1, 2, 3 세 개의 입력만 활용해 생성합니다.
이렇게 하는 이유는 연산량을 줄이려는 의도도 있지만, 연결의 symmetry를 깨줌으로써 global한 feature로 만들기 위함이라고 합니다.
결과
LeNet-5는 MNIST 데이터셋으로 학습/평가되었습니다. 상세한 학습 파라미터는 논문에 설명되어 있습니다.
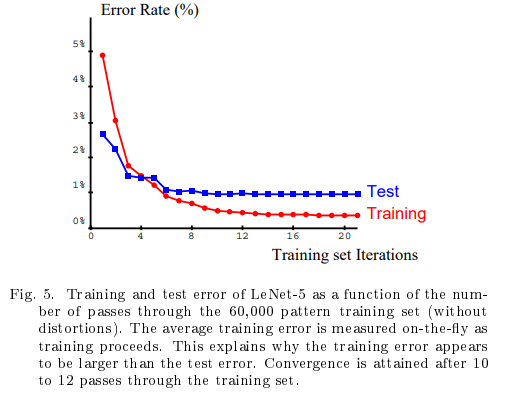
위 그림은 LeNet-5를 학습시키면서 Error rate를 확인한 결과입니다.
학습결과 약 10번의 epoch가 지난 뒤 test set에서 에러가 0.95%에서 수렴하였다고 합니다.
training set에서의 에러는 19 epoch에서 0.35%에 도달했다고 합니다.
참고로 보통 학습을 지속하면 overfitting이 발생하여 training set에서는 에러가 감소하지만 test set에서는 오히려 증가하는데, 논문의 결과에서는 그러한 현상이 나타나지 않았습니다.
논문는 언급하는 한가지 가능성은 learning rate를 크게 유지하였기 때문에 Loss가 local minimum에 빠지지 않고 불규칙하게 진동(oscillating randomly)한 것이라고 합니다.

위 그림은 잡음과 외곡이 있는 이미지에서 각각의 layer가 어떤 결과를 도출했는지와 output결과를 나타내는 그림입니다.
결과에서 볼 수 있듯 잡음이 있거나 왜곡이 있는 이미지에서도 안정적인 결과를 보여줌을 확인할 수 있습니다.
논문에서는 LeNet-5에 대해 학습 데이터를 달리했을 때 성능이나 LeNet-1, 4와 Fully Connected Multilayer Neural Network, 3개의 LeNet-4 결과를 결합한 Boosted LeNet-4 등 여러 구조와의 성능을 비교해 놓았으니 한번 쯤 참고삼아 읽어보셔도 좋을 듯 합니다.
정리
LeNet-5는 복잡하지 않은 망을 이용하여 (당시 기준)높은 성능을 보여주었을 뿐만 아니라 Convolutional layer와 pooling의 조합을 반복하는 현대적인 CNN 구조를 제안했다는 점에서 의미가 있는 모델인 것 같습니다.
또한, CNN 네트워크들의 고전으로 딥러닝을 활용해 영상분석을 하시는 분이라면 CNN에 대해 이해도를 높이기 위해 한번쯤 읽어볼만한 가치가 있다고 생각됩니다.
참고자료
Gradient-Based Learning Applied to Document Recognition
위키백과
라온피플 블로그
여니여니 블로그
Sik-Ho Tsang 블로그
딥러닝 공부방 블로그
머신러닝 아카데미 기사

정리가 너무 잘되어 있어서 많이 참고하고 갑니다!!! 괜찮으시다면 포스팅 한 내용 제 티스토리에 포스팅해도 될까요?