
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
VGGNet?
VGGNet은 OxFord대학교의 Visual Geometry Group이 개발한 CNN Network입니다.
비록 2014년 ILSVRC에서 2위에 그쳤지만 이해하기 쉬운 간단한 구조로 되어있고 변형이 용이하기 때문에 같은 대회에서 1위를 차지한 GoogleNet보다 더 많이 활용되고 있습니다.
CNN Network의 성능을 향상시키는 가장 기본적인 방법은 망의 깊이를 늘리는 것 입니다.
VGGNet은 이러한 망 깊이(depth)가 따른 네트워크의 성능변화를 확인하기 위해 개발된 네트워크 입니다.
VGGNet을 발표한 논문인 Very Deep Convolutional Networks For Large-Scale Image Recognition 에서는 동일한 컨셉의 깊이가 다른 6가지 구조에 대해 발표하였고 성능을 비교했습니다.
특징
VGGNet은 망 깊이(depth)가 네트워크 성능에 주는 영향에 대해 확인하기 위한 네트워크이며, 이를 위해 상하좌우 및 중심을 볼 수 있는 가장 작은 크기인 3x3 사이즈 필터 만을 사용합니다.
논문에서는 3x3 사이즈의 필터를 쌓아가며 깊이에 따른 6가지 네트워크를 구현한 뒤 성능을 확인하였습니다.
Factoring Convolution
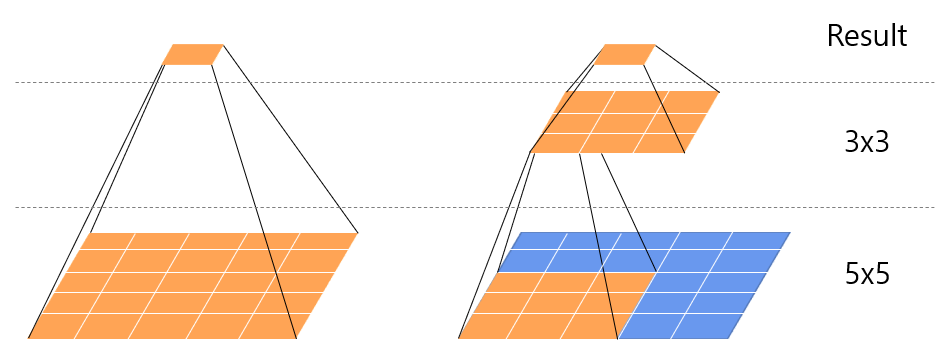
위 그림과 같이 kernel 사이즈가 5x5인 convolution은 2개의 3x3 convolution으로 분해(Factoring)할 수 있습니다.
즉, 3x3 Conv layer를 중첩하면 5x5 Conv layer를 만들 수 있으며, 더 나아가 7x7, 9x9와 같이 큰 receptive field를 갖는 Conv layer를 3x3 Conv layer의 중첩으로 만들 수 있습니다.
그렇다면 3x3 convolution와 큰 receptive field를 갖는 convolution중 어느 것이 좋은지 궁금해지는데,
논문에서는 큰 사이즈의 필터 대신 3x3 사이즈의 필터를 사용하는 것이 두 가지 장점이 있다고 설명합니다.
첫 번째 장점은 비선형성(non-linearity)가 더 증가하여 더 좋은 차별성(구별력)을 가진 feature를 뽑아낼 수 있습니다.
즉, 5x5 사이즈 필터 대신 3x3 사이즈 필터 두개를 사용하면 같은 영역을 볼 수 있는 동시에 더 좋은 feature를 추출하여 성능이 증가됩니다. 이 내용은 뒤의 실험결과에서 증명했습니다.
두 번째는 사용하는 파라미터의 수가 줄어들고, 학습 속도가 빨라지는 것 입니다.
입출력 채널 수가 같다고 할 때 5x5 Conv layer와 두 개의 3x3 Conv layer의 파라미터 수를 계산하면 아래와 같습니다.
kernel size 5 :
kernel size 3 :
두 개의 3x3 사이즈 필터를 사용하면 5x5 사이즈의 필터를 사용하는 것 보다 72%의 파라미터만 사용하기 때문에 더 적은 파라미터로 동일한 영역에 대해 Convolution 연산이 가능합니다.
네트워크 구조
1) 기본 골격
VGGNet의 기본 구조는 Conv layer뒤에 max-pooling으로 해상도를 줄여가는 단순한 구조로 되어있습니다.
그리고 기존 CNN Network들 처럼 FC layer 3개를 뒤에 연결한 뒤 soft-max layer를 거쳐 각 클래스의 확률값을 계산합니다.
Convolutional layer는 stride는 1에 padding 1을 주어 원 해상도가 유지되도록 만들었고, Conv layer 뒤에 2x2 window size에 stride 2를 갖는 max-pooling을 통해 해상도를 점차 줄여갑니다.
채널 수는 64채널부터 시작하여 max-pooling으로 해상도를 줄일 때 마다 2배씩 늘려나갑니다.
Fully-Connected layer의 경우 총 3개의 layer로 구성되어 있습니다. 첫 번째와 두 번째 layer는 4,096개의 채널을 갖고 마지막 layer는 1,000개(ImageNet Dataset의 class 개수) 채널을 갖습니다.
2) 설계한 네트워크 구조
위에서 설명한 기본 틀을 가진 채 VGGNet개발자들은 depth가 늘어남에 따른 성능변화, LRN사용에 따른 성능변화, 1x1 Conv layer 사용에 의한 성능변화를 확인하기 위해 아래와 같이 총 6가지 종류의 네트워크를 설계했습니다.
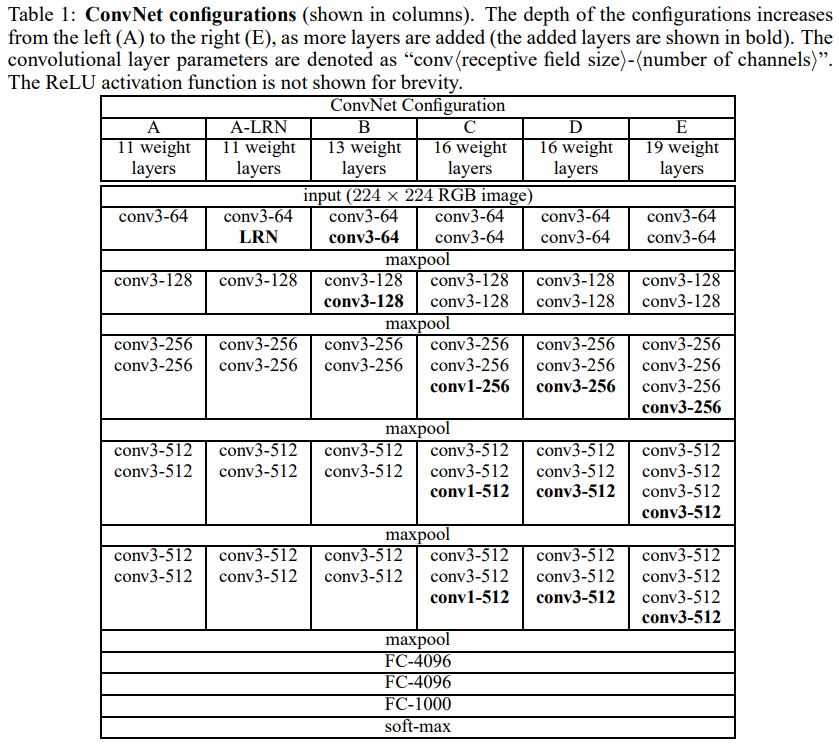
6개 구조 중 A, B, D, E 4개의 구조로 depth에 따른 성능변화를 볼 수 있습니다.
또, LRN의 성능을 확인하기 위해 가장 기본구조인 A의 첫 번째 Conv layer 후 LRN을 추가해 성능변화를 확인합니다.
마지막으로 C, D 구조를 활용해 1x1 Conv layer의 효용성을 확인합니다.

전체 파라미터 수는 위 표와 같습니다. 표에서 보면 가장 작은 크기의 VGGNet-A조차 133million(1억 3300만개)으로 엄청나게 많습니다. 이렇게 큰 파라미터를 갖는 이유는 맨 마지막에 붙는 FC layer 때문으로, FC layer에만 122 million개의 파라미터가 있습니다.
성능평가
VGGNet 논문에서는 VGGNet은 설계한 6개 구조에 대해 학습/평가 이미지의 scale과 같은 요소를 변화해 가며 성능이 어떻게 변화되는지 확인했습니다.
학습/평가 방법
1) 학습
VGGNet또한 AlexNet과 같이 Overfitting에 빠지지 않게 하기위해 Data augmentation 기법을(특히 scale jittering) 활용합니다.
먼저 training scale를 S라고 지정합니다. 학습시에는 이미지의 짧은 변의 크기를 S로 리사이즈한 뒤 무작위로 224x224 영역을 1장 crop합니다. crop한 이미지는 AlexNet과 같이 수평반전과 RGB컬러성분 변경 과정을 거칩니다.
고정된 S를 사용하는 Single-scale 학습에서는 S=256, S=384 두 개의 값을 사용하며, S=256을 먼저 학습한 다음, S=384를 학습합니다.
Multi-scale 학습에서는 S를 [S, S] 사이 값 중 무작위로 선정합니다. VGGNet 논문에서는 256~512 사이 값 중 무작위로 선정된 스케일에 대해 학습합니다.
학습 시 가중치들의 초기화는 먼저 가장 간단한 A구조에 대해 랜덤 초기화 후 학습을 진행합니다.
더 깊어진 B구조에서는 A의 가중치값을 기본값으로 사용하되, A에서 B 구조를 만들기 위해 새롭게 추가된 layer의 가중치는 랜덤 초기화합니다.
같은 방식으로 C, D, E도 앞선 구조의 가중치를 초기값으로 활용해 학습합니다.
2) 평가
VGGNet에서 평가할 땐 크게 세 가지 특징이 있습니다.
첫 번째는 AlexNet, GoogLeNet 등 다른 CNN Network들과 마찬가지로 여러 스케일에 대해 평가한 결과를 합침으로써 성능을 높입니다.
VGGNet의 경우 먼저 training scale S와 유사하게 test scale을 Q로 지정합니다.
평가 할 이미지의 짧은 변을 Q로 변환한 이미지를 네트워크에 입력하며, 결과로 나온 각각의 class의 확률값의 평균값을 활용해 최종 결과를 도출합니다.
두 번째는 네트워크 제일 뒤에 붙는 FC layer를 Conv layer로 변환하여 fully-convolutional network로 만듭니다.
구체적으로는 첫 번째 FC layer를 7x7 Conv layer로 바꾸고, 뒤의 두 FC layer는 1x1 Conv layer로 바꿉니다.
이러한 fully-convolutional network로 변환함으로 입력 이미지 크기에 상관없이 네트워크를 동작시킬 수 있게 됩니다. 즉, VGGNet Network에 Q로 크기를 바꾼 평가 이미지를 입력할 때 crop없이 전체 이미지 입력할 수 있게됩니다.
마지막으로 이미지를 여러 스케일에서 평가할 때 multi-crop방식과 dense evaluation방식을 사용합니다.
Dense evaluation은 crop 이미지마다 네트워크에 입력하는것과는 달리 큰 이미지를 네트워크에 한번 입력한 다음 sliding window를 적용하는 것과 같이 일정한 간격으로 결과를 도출할 수 있는 방법입니다. 이는 연산 관점에서 매우 효율적이지만, grid크기에 문제로 인해 성능이 나빠질 수 있기 때문에 실제로는 multi-crop을 상호 보완적으로 사용하였다고 합니다.
결과
VGGNet은 ILSVRC-2012 dataset의 validation set을 활용해 평가되었습니다.
1) Single-scale
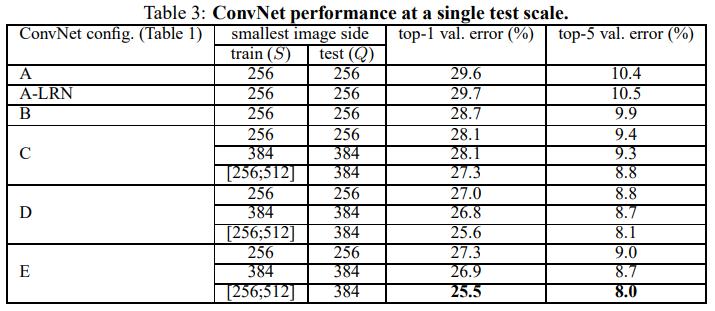
위 표는 평가용 이미지의 scale인 Q를 하나의 값으로 고정한 single-scale 평가 결과 이며 아래에서 자세히 살펴보겠습니다.

먼저 A와 A-LRN의 결과를 비교했을 때, LRN(Local Response Normalisation)을 적용한 결과가 미미하게 성능이 떨어짐을 볼 수 있습니다. 논문 저자들은 이 결과로부터 LRN이 유용하지 않다고 판단했으며, B~E 구조에서는 사용하지 않았다고 합니다.

두 번째로 학습/평가의 scale이 256인 결과만 봤을 때, 망의 깊이가 깊어질수록 error가 낮아지는 것을 볼 수 있습니다. 따라서 depth가 증가할 수록 성능이 좋아지지만 D와 E구조로 부터 19개 layer를 넘어가면 성능향상이 수렴하는 것을 볼 수 있습니다. 하지만 논문에서는 더 큰 데이터셋에서는 성능향상이 있을 수 있다고 언급하였습니다.
![]()
세 번째로 B와 C를 보면 1x1 Conv layer를 활용해 비선형성을 높인 경우 성능이 향상되며, C와 D에서 1x1 Conv layer보다 3x3 Conv layer를 썼을 때 성능이 더 좋음을 확인할 수 있습니다.
이 결과로부터 1x1 Conv layer를 활용해 비선형성을 높이는 것이 성능향상에 도움이 되지만, 1x1보다 3x3 사이즈에서 성능이 더 좋은것으로 보아 주변 위치의 공간적 정보를 활용하는 것이 더 중요함을 알 수 있습니다.
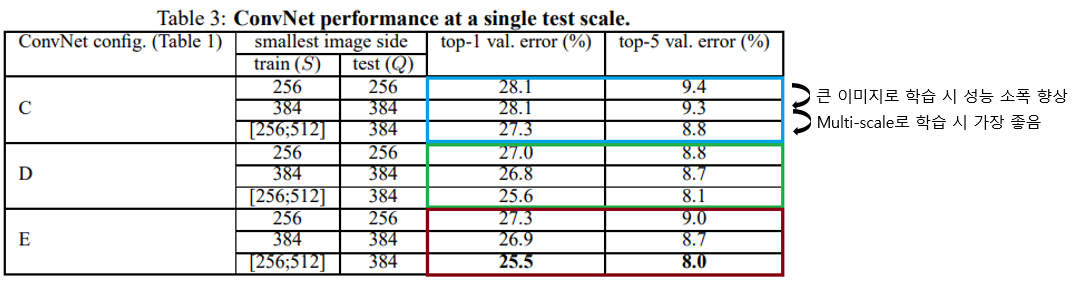
네 번째로 학습 시 scale jittering에 따른 성능변화를 보면 더 큰 S를 사용하는 편이 성능이 약간 좋으며, S를 하나의 고정 값으로 사용하는 single-scale 보다 multi-scale(256~512)을 사용하는 편이 더 좋은 성능이 나왔습니다. 이 결과로부터 학습할 때 scale jittering을 사용하는 것이 도움되는것을 알 수 있습니다.
마지막으로 표에는 나오지 않지만, 큰 receptive field를 갖는 Conv layer와 3x3 Conv layer를 중첩한 경우를 비교했습니다.
B구조에서 3x3 Conv layer 두 개가 짝을 이루는것을 볼 수 있는데, 이것을 하나의 5x5 Conv layer로 바꾼뒤 성능을 확인했습니다.
그 결과 3x3 크기의 필터를 사용하면 top-1 error가 7%나 낮아짐을 볼 수 있었고, 작은 필터를 중첩해서 사용하는 것이 큰 필터 하나를 사용하는 것보다 더 좋음을 확인했다고 합니다.
2) Multi-scale
다음으로 아래 표는 평가 시 test scale Q를 여러개 사용하는 Multi-scale 평가결과입니다.
평가는 single-scale 또는 multi-scale로 학습된 모델의 weight에 대해 3개 scale의 Q로 테스트했을 때 성능변화를 확인했습니다.
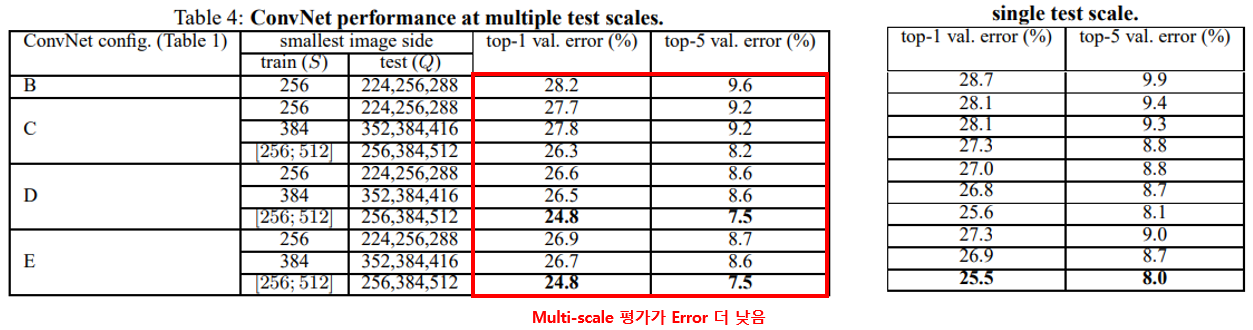
위 표에는 각각의 케이스에서 테스트 결과가 정리되어 있습니다.
앞 단의 single-scale 테스트 결과와 비교해 보면 multi-scale로 평가한 경우가 single scale로 평가한 것 보다 성능이 좋음을 알 수 있습니다.
3) Multi-crop
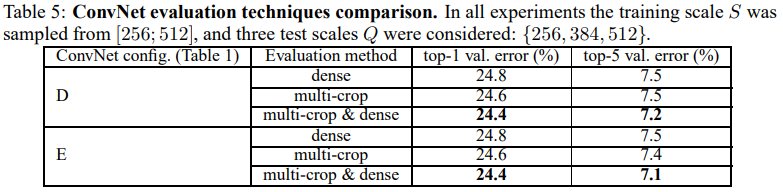
위의 표는 평가할 때 Dense와 multi-crop을 사용할 때의 결과입니다.
Dense를 사용했을 때 보다 multi-crop을 사용한 평가방법이 미세하게 성능이 더 좋음을 확인할 수 있고, 두 방식을 함께 적용하는 편이 가장 좋음을 볼 수 있습니다.
논문에서는 Dense evaluation과 방식은 Convolution 경계조건을 다르게 처리하기 때문에 두 방법 모두를 사용하면 서로 상호보완적이 되어 성능이 향상된다고 언급하고 있습니다.
4) 기타
다른 CNN Network들과 마찬가지로 VGGNet 또한 ILSVRC에 참가할 때 여러개 모델 출력의 평균치를 사용하는 ensemble형태로 제출했습니다.

ILSVRC에 제출한 결과는 7개의 네트워크를 활용해 top-5 error 7.3%를 달성했으며, 제출 후 추가적인 실험을 통해 2개의 네트워크에서 top-5 error를 6.8%까지 낮췄습니다.
이 수치는 ILSVRC-2014의 SOTA인 GoogleNet의 6.7%와 매우 근소한 차이입니다. 또, ensemble 없는 singel network에서는 7.0%로 7.9%의 GoogLeNet보다 더 좋은 성능을 보여줍니다.
마무리
VGGNet은 ILSVRC-2014에서 GoogLeNet에 밀려 2위를 차지했지만, 단순한 구조로 이해와 구현이 쉽고 여러 형태로 변형시켜가며 테스트하기 용이하기 때문에 GoogLeNet보다 더 많이 사용되고 있습니다.
성능 또한 GoogLeNet에 밀리지 않은 좋은 성능을 보여주며, 이러한 결과를 GoogLeNet과 같은 복잡한 구조 없이 단순한 구조에서 망의 깊이만 늘려 달성했다는 점에서 의미가 있다고 생각됩니다.
또한 VGGNet을 설명한 논문에서는 여러 실험을 통해 LRN과 1x1 Conv layer의 효용성, 망 깊이에 따른 성능 등 CNN Network에 대해 많은 내용을 알 수 있어 한번은 읽어볼 가치가 있다고 생각됩니다.
참고자료
Very Deep Convolutional Networks For Large-Scale Image Recognition
라온피플 블로그
Time Traveler 블로그

자세한 설명 감사합니다!!