[2011.07068] Fast and Robust Cascade Model for Multiple Degradation Single Image Super-Resolution
Super Resolution
abs : https://arxiv.org/abs/2011.07068
code(아직 안 올라옴) : https://github.com/vipgugr/CADUF
abstract
Single Image Super-Resolution (SISR) is one of the low-level computer vision problems that has received increased attention in the last few years. Current approaches are primarily based on harnessing the power of deep learning models and optimization techniques to reverse the degradation model. Owing to its hardness, isotropic blurring or Gaussians with small anisotropic deformations have been mainly considered. Here, we widen this scenario by including large non-Gaussian blurs that arise in real camera movements. Our approach leverages the degradation model and proposes a new formulation of the Convolutional Neural Network (CNN) cascade model, where each network sub-module is constrained to solve a specific degradation: deblurring or upsampling. A new densely connected CNN-architecture is proposed where the output of each sub-module is restricted using some external knowledge to focus it on its specific task. As far we know this use of domain-knowledge to module-level is a novelty in SISR. To fit the finest model, a final sub-module takes care of the residual errors propagated by the previous sub-modules. We check our model with three state of the art (SOTA) datasets in SISR and compare the results with the SOTA models. The results show that our model is the only one able to manage our wider set of deformations. Furthermore, our model overcomes all current SOTA methods for a standard set of deformations. In terms of computational load, our model also improves on the two closest competitors in terms of efficiency. Although the approach is non-blind and requires an estimation of the blur kernel, it shows robustness to blur kernel estimation errors, making it a good alternative to blind models.
abstract 읽었을 때 생각나는 질문들
- 정말 이 정도로 SOTA 보다 좋다고? 너 뭐랑 비교했는데?
- 각 모듈 별로 domain knowledge를 반영해서 만드는 거도 많이 있던건데...
Problem statement
- 최근 딥러닝 기반 SR 기법들은 isotropic blurring 혹은 Gaussians with small anisotropic deformations 정도만 주로 고려한다.
- 따라서 Real camera movement의 large non-Gaussian blur를 고려한 SR 모델을 제안한다.
- 각각의 모듈들에 카메라에 대한 prior를 적용했다.
Proposed
- SRResnet 블럭들을 (그렇게 한 이유를 덧붙여서) 조금씩 깨작깨작.
Cons
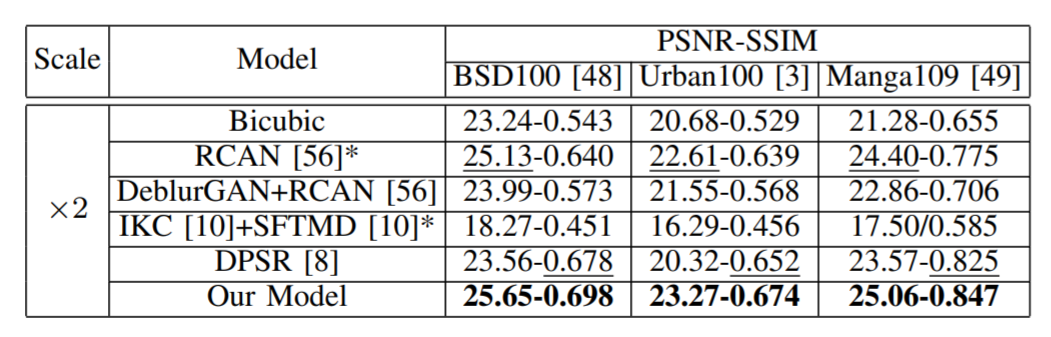
18년 ~ 19년 거랑만 비교하면 어떡해요 ㅠㅠ
잡소리
읽기 전에 저자 정보부터 확인할 필요성을 다시 느낌.
