■ 개요
○ 오늘 계획
- 모의 면접
- UGS 요청사항들
■ 모의면접 준비(Unity 문법 31-41)
31. Unity 생명주기(Unity Life Cycle)에 대해서 설명해주세요.
- Unity 생명주기는 게임 오브젝트의 생성부터 파괴까지의 과정에서 호출되는 일련의 메서드들로 구성되어 있고, MonoBehaviour를 상속 받아야지 사용할 수 있습니다.
- 참고 공식 문서
- 주요 단계
Awake- 프리팹이 인스턴스화 된 직후에 호출
- 스크립트가 로드될 때 가장 먼저 호출
- 게임 오브젝트가 시작하는 동안 비활성 상태인 경우 Awake 함수는 활성화될 때까지 호출되지 않음
OnEnable- 스크립트 인스턴스가 활성화된 경우에만 첫 번째 프레임 업데이트 전에 호출
- 레벨이 로드되거나 스크립트 컴포넌트를 포함한 게임 오브젝트가 인스턴스화될 때와 같이 MonoBehaviour를 생성할 때
Start- 게임이 시작되기 전 첫 번째 프레임에서 호출
- Awake 다음에 실행되며, 오브젝트가 활성화되어 있어야 호출됨
Update- 주로 게임 로직을 업데이트하는 데 사용
- 매 프레임 호출
FixedUpdate- 물리 연산과 관련된 업데이트에 주로 사용
- 프레임 속도와 관계없이 고정된 시간 간격으로 호출
- 프레임 속도가 낮은 경우 프레임당 여러 번 호출될 수 있으며 프레임 속도가 높은 경우 프레임 사이에 호출되지 않을 수 있음
- 모든 물리 계산 및 업데이트는 FixedUpdate 후 즉시 발생
- FixedUpdate 의 움직임 계산을 적용할 때 Time.deltaTime 만큼 값을 곱할 필요가 없습니다. FixedUpdate 가 프레임 속도와 관계없이 신뢰할 수있는 타이머에서 호출되기 때문
LateUpdate- 모든 Update 호출이 끝난 후에 호출
- Update 에서 수행된 모든 계산은 LateUpdate 가 시작할 때 완료됨
- 주로 카메라 관련 작업에 사용
- 캐릭터를 움직이고 Update 로 방향을 바꾸게 하는 경우 LateUpdate 에서 모든 카메라 움직임과 로테이션 계산을 수행할 수 있습니다. 이렇게 하면 카메라가 포지션을 추적하기 전에 캐릭터가 완전히 움직였는지 확인할 수 있음
OnApplicationQuit- 이 함수는 애플리케이션 종료 전 모든 게임 오브젝트에서 호출
- 에디터에서 사용자가 플레이 모드를 중지할 때 호출
OnDisable
동작이 비활성화되거나 비활성 상태일 때 이 함수가 호출OnDestroy
게임 오브젝트가 삭제되기 전에 호출
32. MonoBehaviour 클래스의 주요 메서드와 그 기능에 대해 설명해주세요.
-
MonoBehaviour 클래스에서 Start와 Awake의 차이점은 무엇이며, 이를 적절히 사용하는 방법에 대해 설명해주세요.
-
왜 MonoBehaviour가 필요할까?
- Unity의 생명주기 메서드는 Unity 엔진과의 연동이 필요합니다.
- MonoBehaviour는 Unity의 엔진 내부에서 동작하는 핵심 연결점 역할을 하며, 생명주기 메서드 호출을 가능하게 합니다.
- 상속받지 않으면 GameObject, Transform 등의 Unity 객체를 직접 다룰 수 없습니다.
- 상속받지 않고도 이용하려면
MonoBehaviour 클래스를 활용하여 비MonoBehaviour 클래스의 메서드 호출을 주입합니다.
- 상속받지 않고도 이용하려면
-
주요 메서드
Awake: 초기화 로직을 배치하며, 종속성 설정 등에 적합Start: 초기화 후 게임 시작 시 실행Update: 프레임 기반 작업에 사용FixedUpdate: 물리 연산 업데이트에 사용LateUpdate: Update가 끝난 뒤 호출OnEnable/OnDisable: 오브젝트 활성화/비활성화 시 동작OnDestroy: 오브젝트가 파괴되기 전에 실행
-
Start와 Awake의 차이점
-
Awake- 오브젝트가 인스턴스화 된 직후에 가장먼저 호출되어, 모든 스크립트의 초기화가 완료되기 전에 실행됩니다.
- 서로 다른 스크립트 간의 의존성을 설정할 때 사용합니다.
- 초기 데이터 설정, 다른 오브젝트에 대한 참조 설정
-
Start- 오브젝트가 활성화된 상태에서 첫 프레임에 실행됩니다. Awake 이후 실행되므로, 다른 컴포넌트나 오브젝트가 초기화된 상태임을 보장합니다.
- 초기화 후의 추가 동작 설정.
-
33. Update, FixedUpdate, LateUpdate의 차이점
-
Update- 매 프레임 호출되며, 프레임 속도에 따라 호출 횟수가 다름. 즉, 게임 성능이 저하되면 호출 주기가 느려질 수 있음
- 주로 게임 로직 및 입력 처리에 사용
-
FixedUpdate-
프레임이 아니라 고정된 시간 간격으로 호출되며, 주로 물리 연산에 사용
-
이 고정 시간 간격은 프로세서 성능과 관계없이 일정하게 유지되도록 설계되었습니다. 기본적으로 Unity의 Fixed Timestep 설정(기본값: 0.02초 = 50FPS)에 따라 호출됩니다.
-
고정 시간 간격 조정 가능
Unity의 Time.fixedDeltaTime 값을 변경하면 FixedUpdate 호출 간격이 달라집니다. (예: 물리 시뮬레이션을 더 정밀하게 처리하고 싶을 때 고정 시간 간격을 줄일 수 있음) -
성능이 부족할 때의 영향
CPU나 GPU 성능이 낮아 게임이 느려지더라도, FixedUpdate의 호출 횟수는 고정 간격을 유지하기 위해 한 프레임 내에서 여러 번 호출될 수 있습니다. 반대로 성능이 매우 높은 경우, FixedUpdate 호출 간의 시간 간격이 더 길어질 수 있습니다. -
정확히 일정하지 않을 수 있는 경우
이론적으로는 일정해야 하지만, 프레임 드랍이나 지나치게 높은 물리 연산 부하가 걸리면 Unity는 물리 연산과 FixedUpdate의 일정을 맞추기 위해 스킵하거나 여러 번 호출하기도 합니다.
FixedUpdate는 컴퓨터 성능과는 무관하게 일정한 주기를 유지하려고 노력하지만, 극단적인 상황에서는 영향을 받을 수도 있음
-
-
예: Rigidbody의 움직임 계산.
-
-
LateUpdate- 모든 Update 호출이 끝난 후 실행
- 주로 카메라 이동 및 오브젝트 추적 등에 사용
34. Time.deltaTime
Time.deltaTime은 현재 프레임과 이전 프레임 사이의 시간 간격(초)을 나타냄- 이 값은 게임이나 앱이 실행될 때 초당 프레임(FPS) 속도에 따라 다름
- CPU 성능과 클럭 속도에 맞춰 1초를 나눔.
- 프레임 속도가 다를 때 움직임이 일정하도록 하기 위해 사용
- 사용 이유
- 게임 로직이 프레임 속도에 의존하지 않도록 하기 위해.
- 예: transform.Translate(Vector3.forward speed Time.deltaTime).
35. 코루틴의 동작 원리 및 사용 예시
- 코루틴은 주어진 YieldInstruction이 완료될 때까지 yield를 통해 실행을 일시 중단하고, 특정 조건이나 시간이 지난 후 다시 실행을 재개할 수 있음
- 코루틴은 멀티태스킹처럼 보이게 하지만 단일 스레드에서 순차적으로 동작
- 일드 종류
yield코루틴은 모든 Update 함수가 다음 프레임에 호출된 후 계속됩니다.yield WaitForSeconds지정한 시간이 지난 후, 모든 Update 함수가 프레임에 호출된 후 계속됩니다.yield WaitForFixedUpdate모든 FixedUpdate가 모든 스크립트에 호출된 후 계속됩니다.yield WWW WWW다운로드가 완료된 후 계속됩니다.yield StartCoroutine코루틴을 연결하고 MyFunc 코루틴이 먼저 완료되기를 기다립니다.
36. Invoke와 코루틴의 차이
Invoke: 특정 메서드를 일정 시간 후에 한 번 호출코루틴: 복잡한 시간 제어나 반복 동작을 구현할 수 있음
37. 코루틴과 멀티쓰레딩의 차이
코루틴- Unity의 메인 스레드에서 실행됩니다.
- 단순히 실행을 중단했다가 이어서 실행하는 방식입니다.
멀티쓰레딩- 다중 스레드에서 병렬로 실행되며, CPU의 멀티코어를 활용합니다.
- Unity의 API는 메인 스레드에서만 호출 가능하므로 주의가 필요합니다.
38. 유니티 최적화 기법
-
최적화 방법
오브젝트 풀링: 자주 생성/삭제되는 오브젝트를 미리 만들어 재사용.Draw Call 감소: Material과 Mesh 병합을 통해 배치 수 줄이기.LOD (Level of Detail): 카메라 거리 기반으로 저해상도 메쉬 렌더링.Occlusion Culling: 보이지 않는 오브젝트의 렌더링 생략.텍스처 압축: 텍스처 포맷을 효율적으로 설정.
-
최적화에서 중요한 부분
- GPU/CPU 병목현상 제거.
- Overdraw 최소화.
-
텍스처 포맷 예시
ETC2, ASTC: 모바일 최적화.
39. 드로우콜(Draw Call)
- 드로우콜은 GPU에 오브젝트 렌더링 명령을 내리는 과정입니다.
- 드로우콜이 많아지면 성능 저하가 발생합니다.
- 최적화 방법:
- Material 병합.
- Static Batching 및 Dynamic Batching 사용.
- 쉐이더 최적화.
40. Find 함수 사용 자제 이유
Find함수는 이름 기반으로 오브젝트를 검색하기 때문에 속도가 느리고, 실시간 성능에 영향을 미칠 수 있습니다.- 가능한 경우 사전에 참조를 캐싱하는 것이 좋습니다.
41. Update에서 GetComponent 캐싱 지양 이유
- GetComponent는 컴포넌트를 검색하는 작업으로, 호출 시 성능 부담이 큽니다.
- 매 프레임 호출되면 성능 저하로 이어질 수 있으므로, 변수에 참조를 저장해 사용하는 것이 바람직합니다.
■ 모의면접 준비 (자료구조 54-56)
54. LinkedList의 특성
-
LinkedList는 노드(Node)라는 개별 요소들이 서로 연결된 구조로, 각 노드는 데이터와 다음 노드를 가리키는 주소를 포함합니다.
-
LinkedList는 언제 사용하면 좋은 자료구조인가요?
동적 데이터 관리가 필요한 경우: 크기를 미리 지정할 필요 없이 데이터를 동적으로 추가/삭제할 수 있습니다.삽입/삭제가 빈번한 경우: 중간에 데이터를 삽입하거나 삭제하는 작업이 빈번하면 Array와 달리 데이터 이동이 필요 없으므로 효율적입니다.메모리 효율적인 활용: 배열과 달리 메모리를 선형적으로 할당하지 않아도 되므로, 불규칙적인 데이터 크기와 위치를 처리하기 좋습니다.
-
LinkedList는 언제 사용하기 불리한가요?
랜덤 접근이 필요한 경우: 배열처럼 인덱스를 통한 직접 접근이 불가능하며, 원하는 데이터를 찾기 위해 처음부터 순차적으로 검색해야 하므로 시간이 더 걸립니다.오버헤드 증가: 각 노드마다 포인터를 저장하므로, 메모리 사용량이 배열보다 큽니다.캐시 성능 저하: 배열은 메모리에 연속적으로 저장되어 캐시 효율이 좋지만, LinkedList는 그렇지 못해 성능이 떨어질 수 있습니다.
-
LinkedList를 본인의 프로젝트에 적용해본 경험
LinkedList를 사용했던 프로젝트는 간단한 히스토리 관리 시스템 개발에서였습니다. 사용자가 입력한 명령을 저장하고 "뒤로가기"나 "앞으로 가기" 같은 기능을 제공하기 위해 이중 연결 리스트(Doubly Linked List)를 사용했습니다. 이를 통해 현재 상태를 기준으로 이전 상태로 이동하거나 이후 상태로 빠르게 이동할 수 있었으며, 명령 삽입과 삭제가 유연하게 이루어졌습니다.
55. Stack의 특성
-
LIFO(Last In, First Out) 구조, 가장 나중에 들어온 데이터가 가장 먼저 나가는 방식으로 동작합니다.
-
Stack은 언제 사용하면 좋은 자료구조인가요?
재귀적인 문제 처리: 함수 호출 스택처럼, 재귀를 구현하거나 트리/그래프의 깊이 우선 탐색(DFS)을 할 때 유용합니다.작업 순서 제어: 연산자 우선순위 계산, 수식 괄호 검사, 문자열 뒤집기와 같은 작업에서 유리합니다.히스토리 관리: 웹 브라우저의 뒤로가기/앞으로 가기 기능, UNDO/REDO 기능 구현에 적합합니다.
-
Stack은 언제 사용하기 불리한가요?
순차적 접근이 필요한 경우: Stack은 맨 위의 요소만 접근 가능하므로, 특정 인덱스에 직접 접근해야 하는 경우 부적합 합니다.크기 제한이 명확하지 않을 때: 메모리가 제한된 환경에서 크기가 동적으로 계속 증가할 가능성이 있으면 위험할 수 있습니다.
-
Stack을 본인의 프로젝트에 적용해본 경험
Stack은 HTML 태그 유효성 검사기를 구현할 때 활용했습니다. 열리는 태그와 닫히는 태그의 쌍을 확인하기 위해, 열린 태그를 Stack에 저장하고 닫히는 태그가 나타날 때 매칭 여부를 확인했습니다. 잘못된 순서나 비매칭 태그를 발견할 경우 오류를 반환하도록 설계하여 문서의 구조적 무결성을 검사하는 기능을 성공적으로 구현했습니다.
Queue의 특성
-
FIFO(First In, First Out) 구조, 가장 먼저 들어온 데이터가 가장 먼저 나가는 방식으로 동작합니다.
-
Queue는 언제 사용하면 좋은 자료구조인가요?
순서가 중요한 경우: 작업 요청이 들어온 순서대로 처리해야 하는 경우(예: 프린터 작업, 콜센터 대기열 등).데이터 스트리밍: 실시간 데이터를 순차적으로 처리해야 하는 상황(예: 데이터 패킷 전송, 멀티스레드 작업의 작업 큐).폭넓은 배치 작업: 너비 우선 탐색(BFS) 같은 알고리즘에서 사용됩니다.
-
Queue는 언제 사용하기 불리한가요?
랜덤 접근이 필요한 경우: Queue는 특정 인덱스의 요소에 직접 접근할 수 없으므로, 배열이나 LinkedList보다 비효율적입니다.많은 요소 삭제가 필요한 경우: 삭제 시 요소 이동이 필요할 수 있어 부적합할 수 있습니다(일반 배열 기반 Queue의 경우).
-
Queue를 본인의 프로젝트에 적용해본 경험
Queue를 활용한 프로젝트는 멀티스레드 환경에서의 작업 분배 시스템이었습니다. 여러 작업 요청이 동시에 들어오는 상황에서 작업 요청을 순차적으로 처리하기 위해 Queue를 사용했습니다. 작업이 요청되면 우선 작업 대기열에 추가되며, 별도의 작업 스레드가 대기열에서 작업을 하나씩 가져가 처리하도록 설계했습니다. 이를 통해 작업 처리의 안정성과 효율성을 높일 수 있었습니다.
■ 모의 면접 피드백
○ 코루틴과 비슷한 다른 기능들
- Invoke
- 잡시스템
- 유니태스크
○ 40
- 이유까지 자세히 찾아보기
- 캐릭터 같은 경우 본까지 검색하기 때문
- 이름이 중복됐을경우
○ 41
- 오버헤드 발생
- 메모리적인것, 탐색 원리도
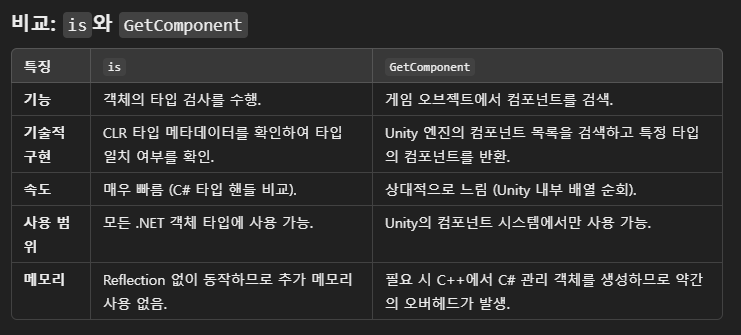
■ is와 GetComponent 차이점