kNN(k-Nearest Neighbor)
k-최근접 이웃 알고리즘
kNN알고리즘은 모든데이터 분류에 사용할 수 있는 아주 간단한 지도학습 알고리즘이다.
kNN 알고리즘 이란 현재 데이터를 특정값으로 분류하기 위해 기존의 데이터 안에서 현재 데이터로부터 가까운 k개의 데이터를 찾아 k개의 레이블 중 가장 많이 분류된 값으로 현재의 데이터를 분류하는 알고리즘입니다.
- kNN에서의k 는 몇개의 이웃을 살펴볼 것인지를 나타내는 변수이고, NN(Nearest Neighbor)이란 현재 알고자 하는 데이터로부터 근접한 데이터를 의미합니다.
- 강남/강북 분류와 같은 이진 분류를 할 경우에는 과반수의 대답을 얻기 위해 k를 홀수로 지정하는것이 좋습니다.
현실공간 → 평면 이동 및 수직 이동이 가능한 3차원 공간
벡터공간 → 벡터 연산이 가능한 N차원 공간
kNN 알고리즘을 포함한 대다수의 머신러닝 알고리즘에서 사용되는 공간이란 개념은 벡터 공간을 의미합니다. 벡터 공간은 우리가 살고 있는 공간보다 더 포괄적인 개념이기 때문에 특별히 현실 공간의 데이터(위도, 경도)가 없어도 데이터의 특성을 벡터 공간의 축으로 지정해서 데이터 간의 거리를 계산할 수 있습니다.
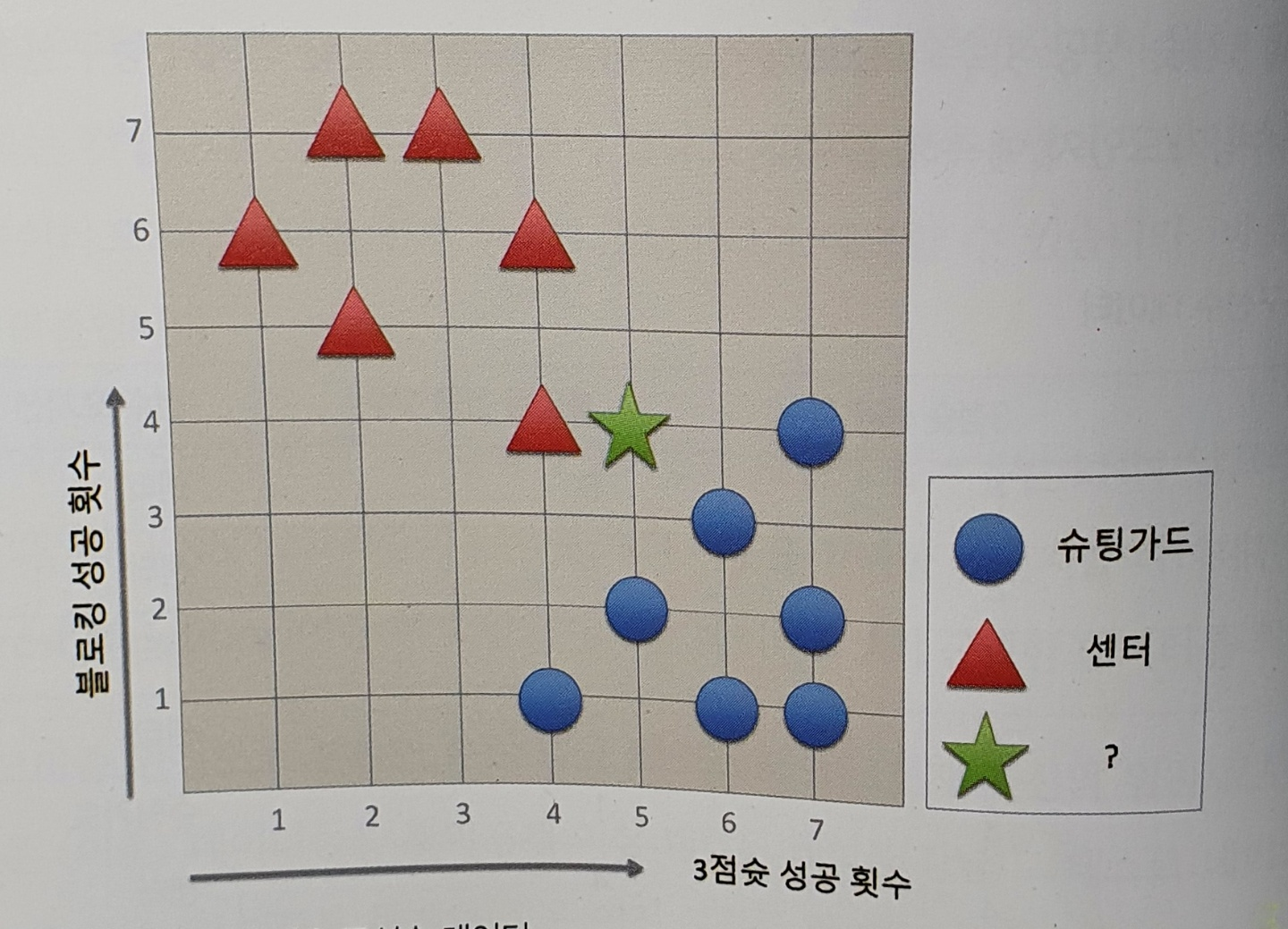
출처 나의 첫 머신러닝/딥러닝 허민석
x 값을 3정슛 성공 횟수, y 값을 블로킹 성공 횟수로 2차원 벡터 공간에서 시각화 한 그림.
k가 1일경우의 분류 → 센터로 분류한다.
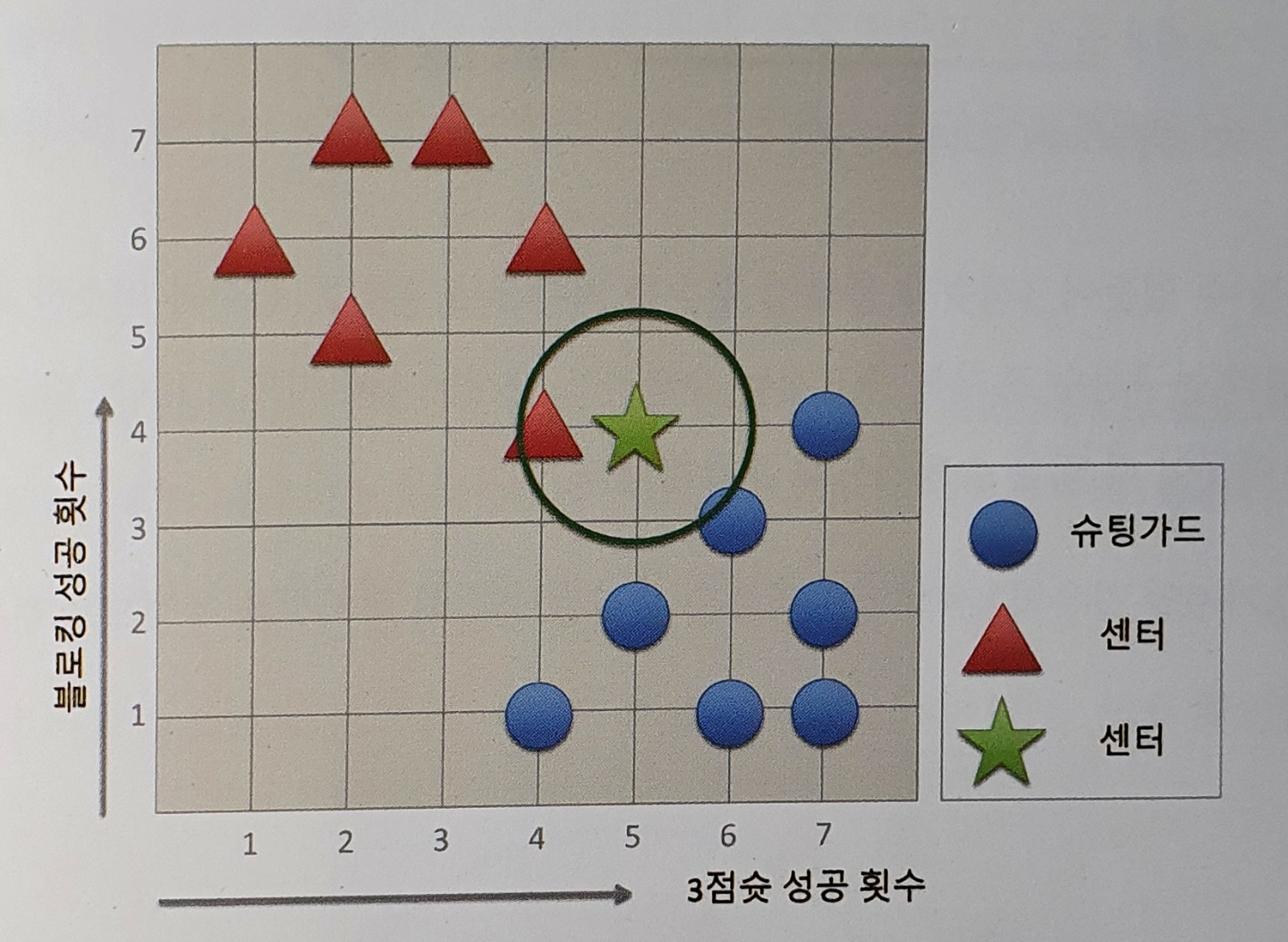
k가 5일 경우의 분류 → 슈팅가드 3개, 센터 2개이므로 슈팅가드로 분류한다.
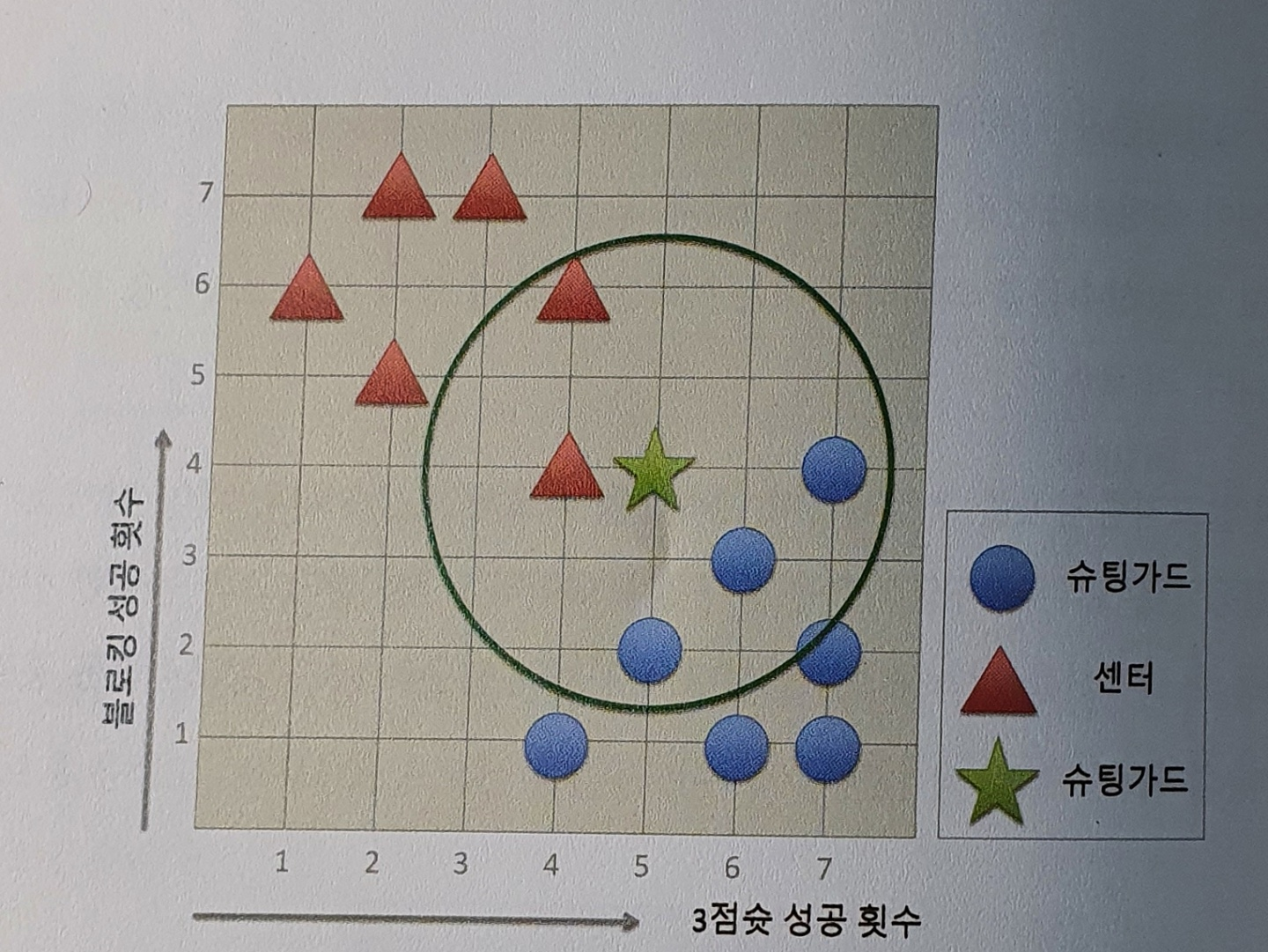
이처럼 kNN알고리즘은 k(탐색할 이웃의 개수)에 따라 데이터를 다르게 예측할 수도 있습니다. 보통 k는 1로 설정하지 않는데 → 하나의 이웃으로 현재의 데이터를 판단하기에는 정보가 너무 한쪽으로 편향돼 있기 때문입니다.
이진 분류
- 두 가지 중 하나를 분류하는 경우
- 악성 코드 분류
- 위조 지폐 분류
다중 분류
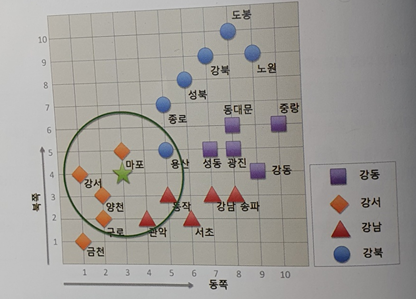
- 여러 개의 가능한 레이블 중 하나로 분류하는 경우
- 손글씨 분류 모델
- 도시 분류 모델
kNN알고리즘에서의 벡터 공간 거리는 유클리드 거리를 이용하여 계산합니다.
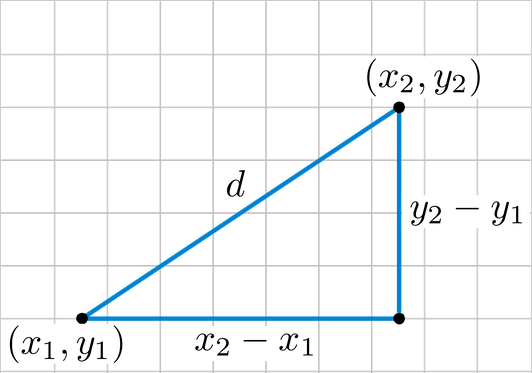
2차원일 경우
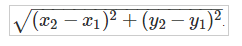
3차원 이상일 경우
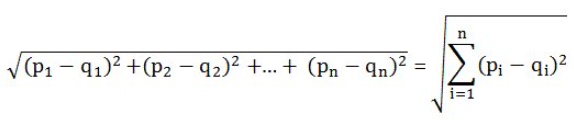
이미지 출처 - wikipedia
장점과 단점
장점
- 알고리즘 이해하기가 쉽다.
- 숫자로 구분된 속성에 우수한 성능을 보인다.
- 별도의 모델 학습이 필요 없다.
단점
- 예측 속도가 느리다. → 하나의 데이터를 예측할 때마다 전체 데이터와의 거리를 계산해야 한다.
- 예측값이 지역 정보에 많이 편향될 수 있다. → k의 개수가 적거나 몇개의 예외적인 데이터가 이웃으로 존재할 경우 예측값이 틀릴 가능성이 높아진다.
공부 및 출처 나의 첫 머신러닝/딥러닝 허민석
