의사결정 트리
데이터 분류 및 회귀에 사용되는 지도학습 알고리즘입니다.
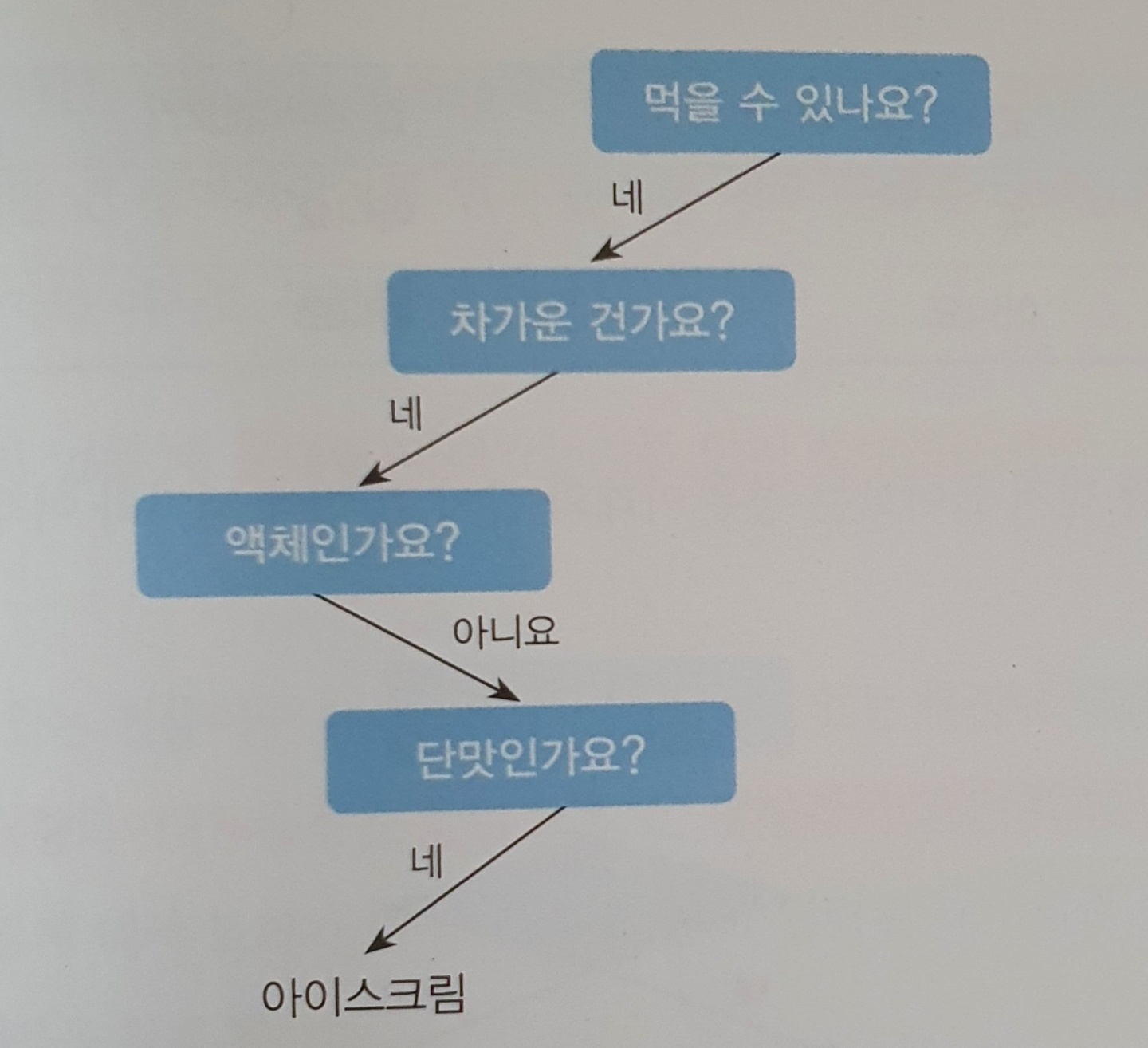
스무고개를 생각하면 이해가기가 쉽습니다. 데이터의 특징을 바탕으로 데이터를 연속적으로 분리하다 보면 결국 하나의 정답으로 데이터를 분류할 수 있습니다.
스무고개 놀이에서 적은 질문으로 정답을 맞추기 위해서는 의미 있는 질문을 먼저 하는 것이 중요하듯이 의사결정 트리에서도 의미 있는 질문을 먼저 하는 것이 상당히 중요합니다.
영향력이 큰 특징을 상위 노드로, 영향력이 작은 특징은 하위 노드로 선택해야 좋은 모델이 될 수 있습니다.
의사결정 트리는 대표적으로 엔트로피 와 지니계수 두 가지 방법 중 하나를 사용하여 영향력을 평가합니다.
정보 이론
정보 이론(Information Theory)에서는 불확실성을 수치적으로 표현한 값을 엔트로피(Entropy)라고 표현하며, 정보이득(Information gain)은 질문 이전의 엔트로피에서 질문 후의 엔트로피를 뺀 값입니다. 즉, 불확실성이 줄어 든 정도를 정보 이득이라고 합니다.
질문 후의 정보 이득 = 질문 전의 엔트로피 - 질문 후의 엔트로피
Gain(T,X) = Entropy(T) - Entropy(T,X)
확률을 바탕으로 정보 엔트로피를 구하는 공식
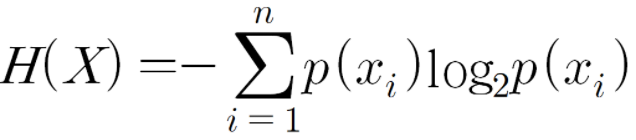
특징에 대한 엔트로피를 계산하는 공식

지니 계수
특징에 의한 분리가 이진 분류로 나타날 경우 지니계수(Gini coefficient)를 사용할 수 있습니다. 사이킷런의 의사결정 트리는 CART(classfication and regression tree) 타입의 의사결정 트리이며, CART는 트리의 노드마다 특징을 이진 분류하는 특징이 있기에 사이킷런은 트리를 구성할 때 기본적으로 지니 계수를 사용합니다.
- 특징이 항상 이진 분류로 나뉠 때 사용됨
- 지니 계수가 높을수록 순도가 높음
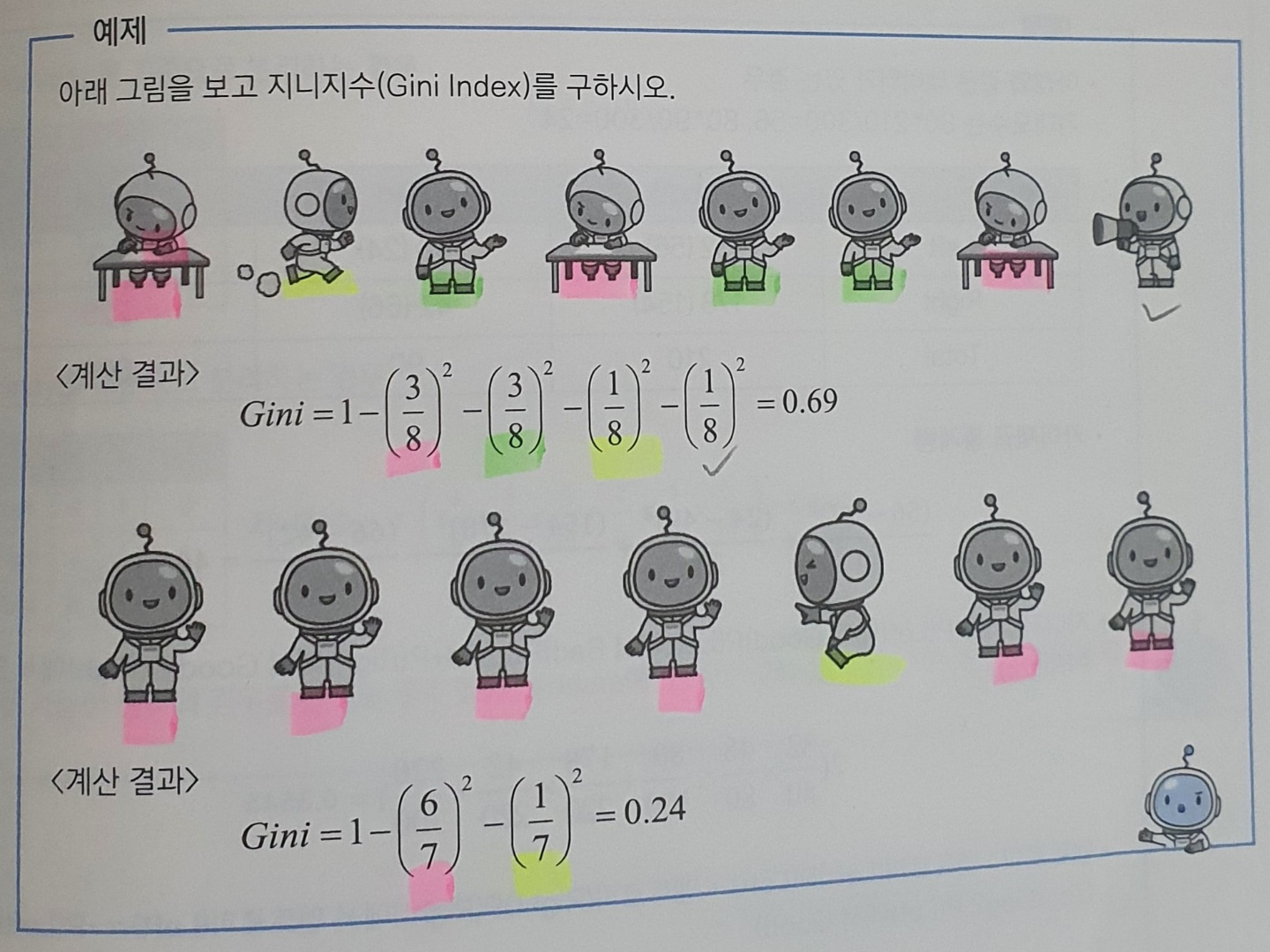
출처 - adsp 데이터분석준전문가(데이터에듀)
위의 그림은 지니지수입니다. 지니 계수는 높을수록 순도가 높지만, 지니 지수는 1- 지니 계수의 값으로 낮을 수록 순도가 높습니다.
다중 분류
의사결정 트리는 다중 분류에도 탁월한 성능을 보입니다.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 경도, 위도에 따른 데이터 시각화
sns.lmplot('longitude', 'latitude', data=train_df, fit_reg=False, # x 축, y 축, 데이터, 라인 없음
scatter_kws={"s": 150}, # 좌표 상의 점의 크기
markers=["o", "x", "+", "*"],
hue="label")
# title
plt.title('district visualization in 2d plane')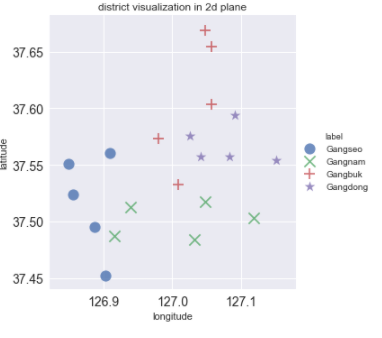
위와 같은 2차원 공간에서의 행정구역 점들을 의사결정 트리로 분류하면 다음과 같은 그림이 나옵니다.
clf = tree.DecisionTreeClassifier(max_depth=4,
min_samples_split=2,
min_samples_leaf=2,
random_state=70).fit(X_train, y_encoded.ravel())
display_decision_surface(clf,X_train, y_encoded)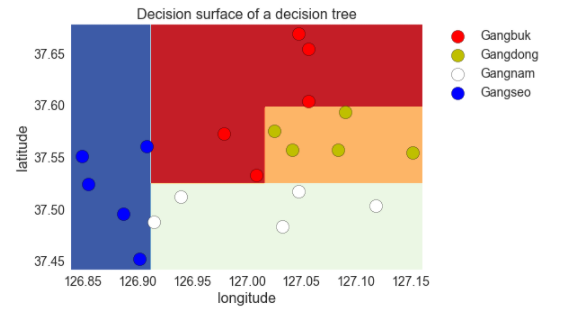
위의 경계를 트리로 시각화하면 더욱 이해하기 쉽습니다.
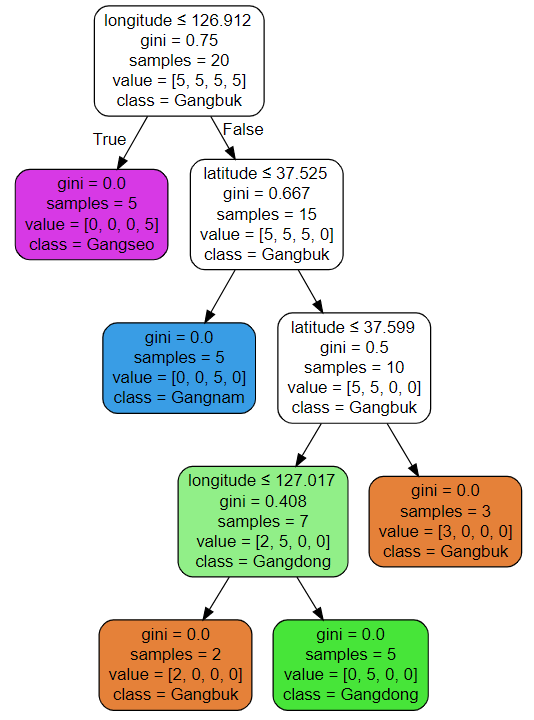
의사 결정 트리 장점
- 수학적인 지식이 없이도 결과를 해석하고 이해하기 쉽다.
- 수치 데이터 및 범주 데이터에 모두 사용이 가능하다.
단점
의사결정 트리의 가장 큰 단점은 과대적합의 위험이 높다는 점입니다. 의사결정 트리 학습 시 적절한 리프 노드의 샘플 개수와 트리의 깊이에 제한을 둬서 학습 데이터에 너무 모델이 치우치지 않게 주의해야 합니다.
출처 - 나의 첫 머신러닝/딥러닝 , ADsP데이터분석 준전문가, 위키피디아
