머신러닝
1.KNN(K-Nearest Neighbor)
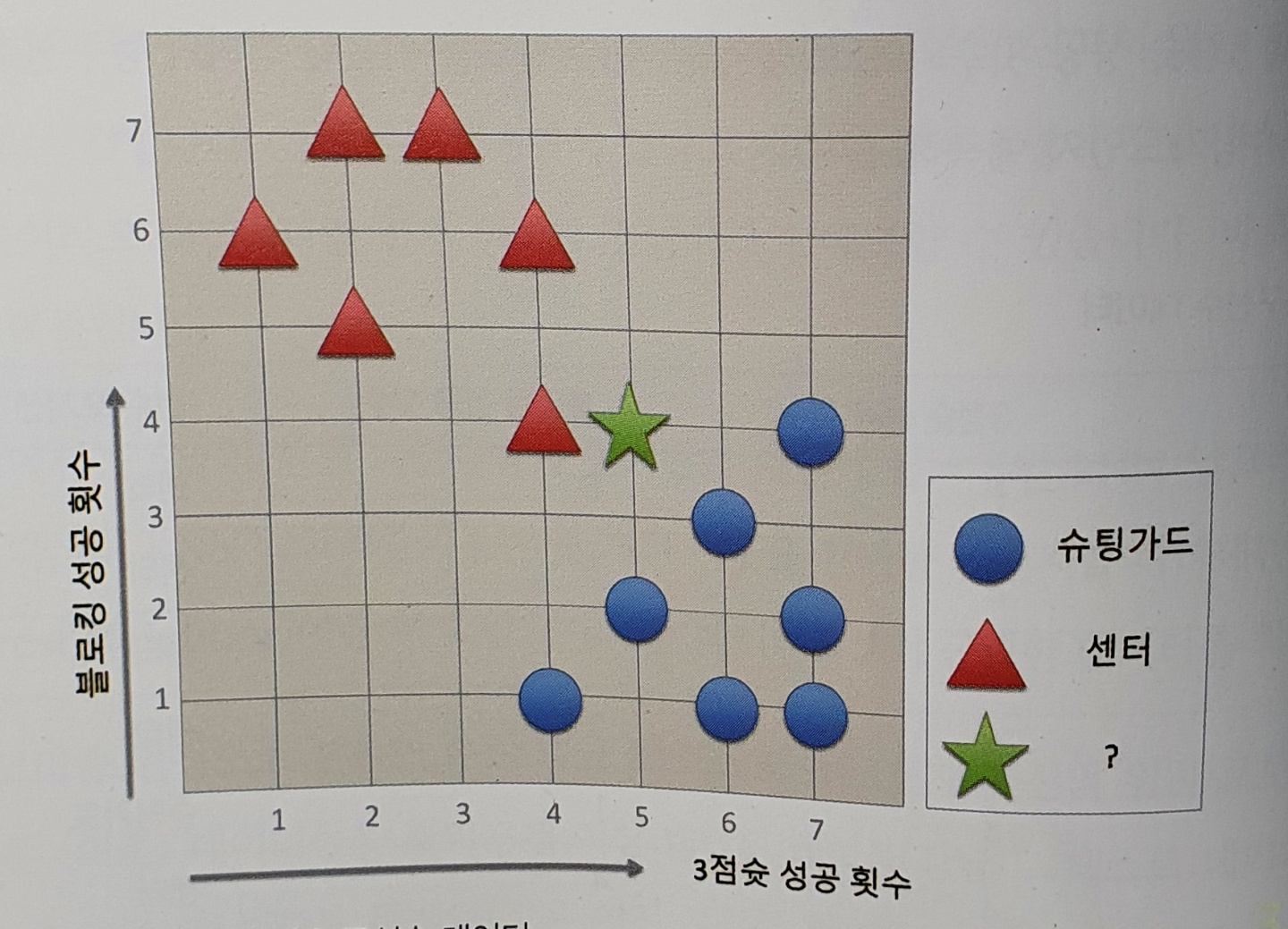
kNN알고리즘은 모든데이터 분류에 사용할 수 있는 아주 간단한 지도학습 알고리즘이다.kNN 알고리즘 이란 현재 데이터를 특정값으로 분류하기 위해 기존의 데이터 안에서 현재 데이터로부터 가까운 k개의 데이터를 찾아 k개의 레이블 중 가장 많이 분류된 값으로 현재의 데이터
2.Decision Tree(의사결정 나무)
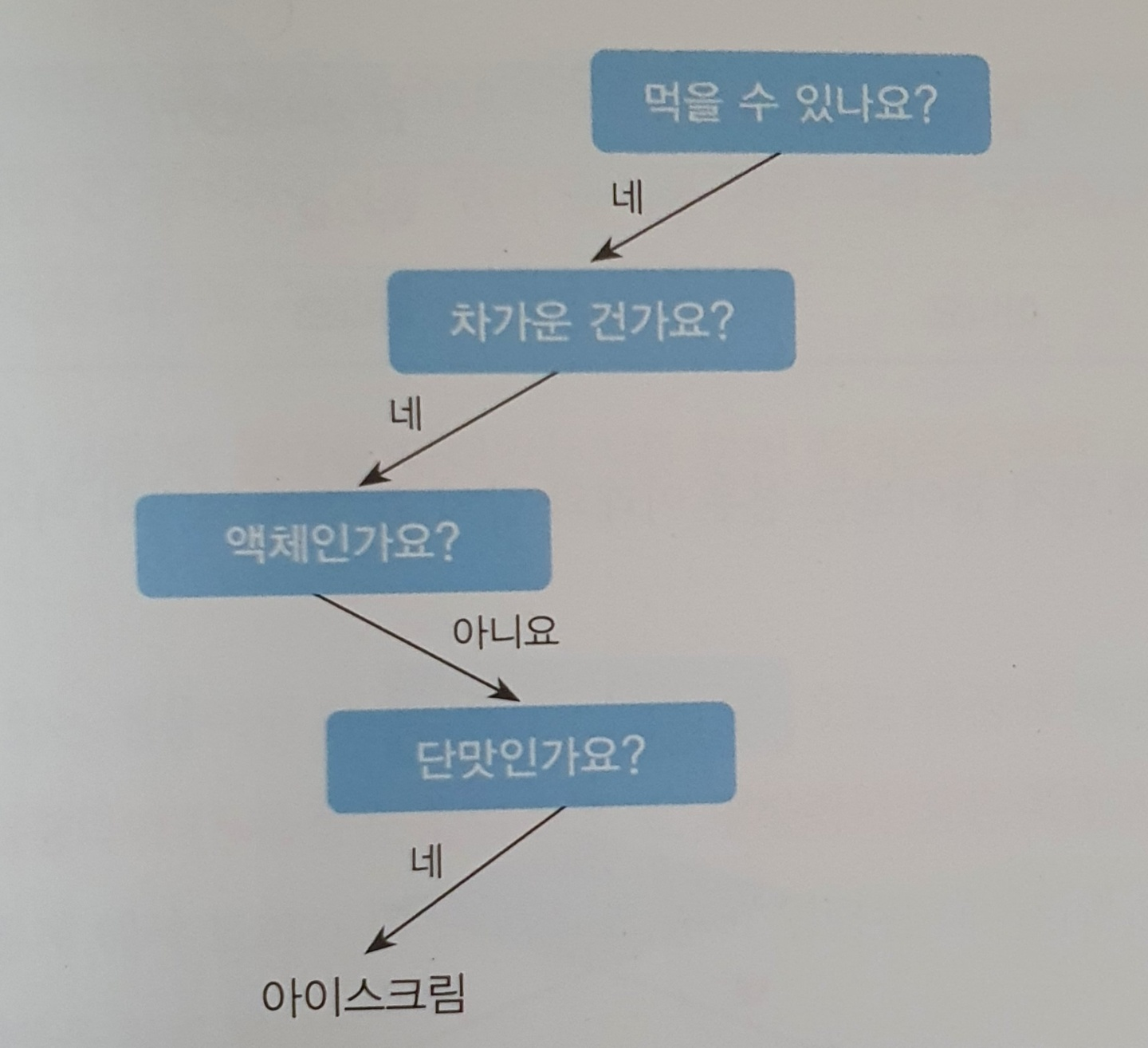
데이터 분류 및 회귀에 사용되는 지도학습 알고리즘입니다.스무고개를 생각하면 이해가기가 쉽습니다. 데이터의 특징을 바탕으로 데이터를 연속적으로 분리하다 보면 결국 하나의 정답으로 데이터를 분류할 수 있습니다.스무고개 놀이에서 적은 질문으로 정답을 맞추기 위해서는 의미 있
3.앙상블
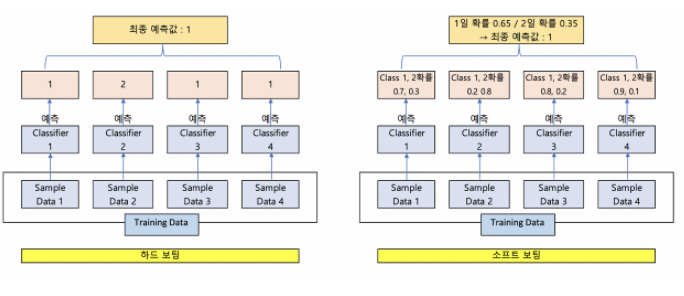
앙상블 기법이란 여러개의 분류 모델을 조합해서 더 나은 성능을 내는 방법입니다.부트스트랩(bootstarp) 과 어그리게이팅(aggregating)의 어원에서 온 것으로, 한 가지 분류 모델을 여러개 만들어 서로 다른 학습 데이터로 학습시킨 후 , 투표를 통해 가장 높
4.군집화
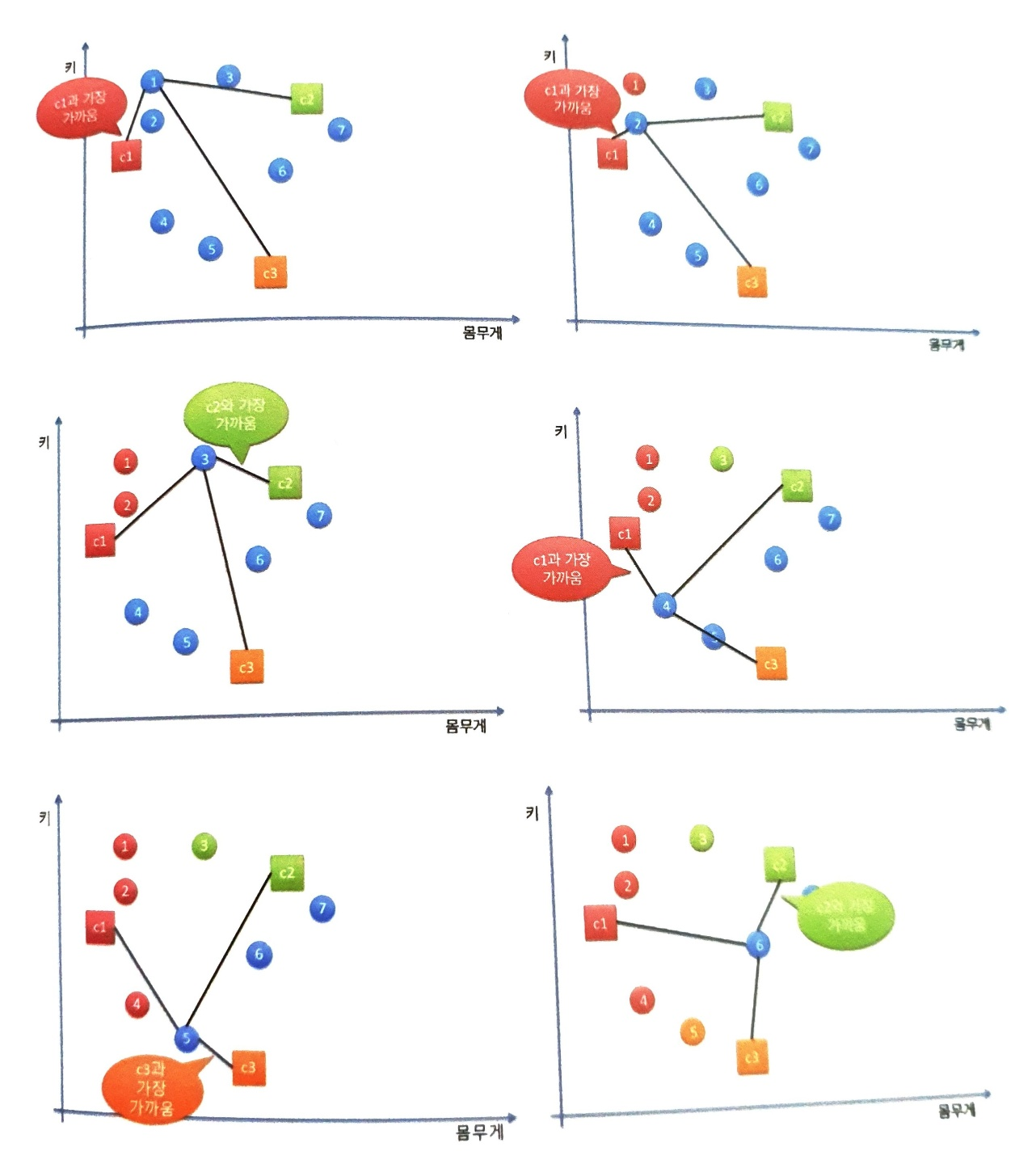
군집화는 비지도학습의 일종으로, 데이터의 특징만으로 비슷한 데이터들끼리 모아 군집된 클래스로 분류합니다.K 평균 알고리즘은 간단하면서도 강력한 클러스터링 알고리즘입니다.데이터 준비몇 개의 클래스로 분류할 것인지 설정(k 값 설정)각 군집의 최초 중심 설정데이터를 가장
5.선형회귀모델
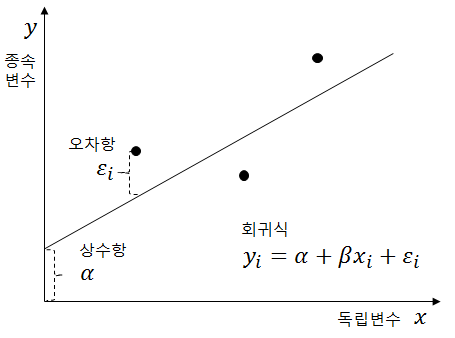
선형회귀 분석이란 관찰된 데이터들을 기반으로 하나의 함수를 구해서 관찰되지 않은 데이터의 값을 예측하는 것을 의미합니다.영향을 받는 변수를 종속변수 혹은 반응변수라고 하고 보통 y로 표기합니다.영향을 주는 변수를 독립변수 혹은 설명변수라 하고 보통 x,x1,x2등으로
6.주성분 분석
주성분 분석(PCA, Principal Component Analysis)이란 고차원의 데이터를 저차원의 데이터로 차원 축소하는 알고리즘입니다. 주로 고차원의 데이터를 시각화 하는데 많이 사용되며, 유용한 정보만 살려서 메모리를 줄이거나 데이터의 노이즈를 줄이고 싶을