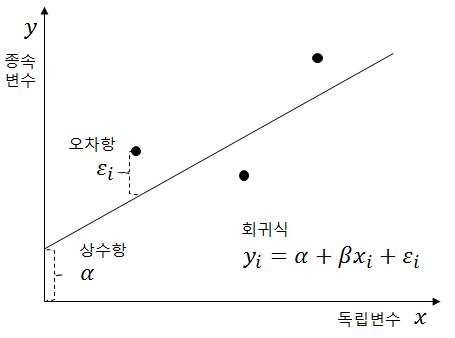
주성분 분석
주성분 분석(PCA, Principal Component Analysis)이란 고차원의 데이터를 저차원의 데이터로 차원 축소하는 알고리즘입니다. 주로 고차원의 데이터를 시각화 하는데 많이 사용되며, 유용한 정보만 살려서 메모리를 줄이거나 데이터의 노이즈를 줄이고 싶을 때도 사용합니다.
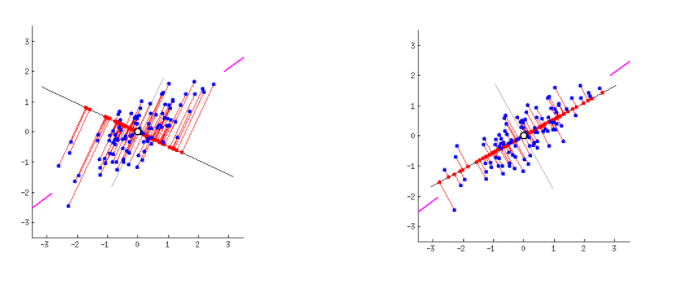
출처 - https://i.stack.imgur.com/lNHqt.gif
{kind=link}
주성분 분석 알고리즘은 수학적인 방법으로 데이터 정보의 유실이 가장 적은 라인을 찾아냅니다. 수학적으로 '데이터의 중첩이 가장 적다'라는 말은 '데이터의 분산이 가장 크다'와 동일합니다.
import pandas as pd
import numpy as np
#데이터 생성
df = pd.DataFrame(columns=['calory', 'breakfast', 'lunch', 'dinner', 'exercise', 'body_shape'])
df.loc[0] = [1200, 1, 0, 0, 2, 'Skinny']
df.loc[1] = [2800, 1, 1, 1, 1, 'Normal']
df.loc[2] = [3500, 2, 2, 1, 0, 'Fat']
df.loc[3] = [1400, 0, 1, 0, 3, 'Skinny']
df.loc[4] = [5000, 2, 2, 2, 0, 'Fat']
df.loc[5] = [1300, 0, 0, 1, 2, 'Skinny']
df.loc[6] = [3000, 1, 0, 1, 1, 'Normal']
df.loc[7] = [4000, 2, 2, 2, 0, 'Fat']
df.loc[8] = [2600, 0, 2, 0, 0, 'Normal']
df.loc[9] = [3000, 1, 2, 1, 1, 'Fat']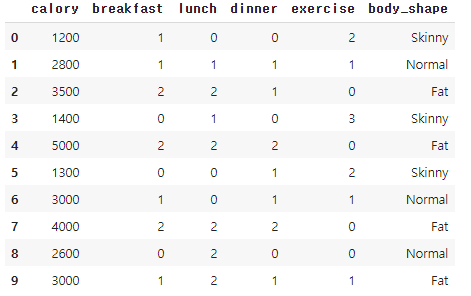
#독립변수,종속변수 분리
X = df[['calory','breakfast','lunch','dinner','exercise']]
Y = df[['body_shape']]#표준화
from sklearn.preprocessing import StandardScaler
x_std = StandardScaler().fit_transform(X)
#공분산 행렬
features = x_std.T
covariance_matrix = np.cov(features)
print(covariance_matrix)
#고유값과 고유 벡터 구하기
projected_X = x_std.dot(eig_vecs.T[0]) / np.linalg.norm(eig_vecs.T[0])
result = pd.DataFrame(projected_X, columns=['PC1'])
result['y-axis'] = 0.0
result['label'] = Y
#시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.lmplot('PC1', 'y-axis', data=result, fit_reg=False, # x-axis, y-axis, data, no line
scatter_kws={"s": 50}, # marker size
hue="label") # color
# title
plt.title('PCA result')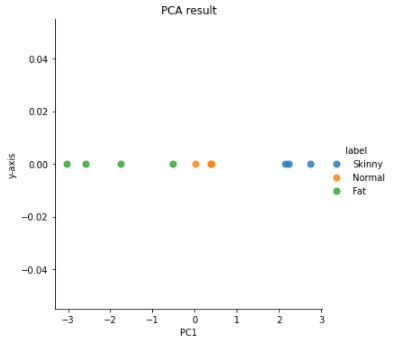
scikit-learn을 사용한 주성분 분석 구현
from sklearn import decomposition
pca = decomposition.PCA(n_components=1)
sklearn_pca_x = pca.fit_transform(x_std)
#시각화
sklearn_result = pd.DataFrame(sklearn_pca_x, columns=['PC1'])
sklearn_result['y-axis'] = 0.0
sklearn_result['label'] = Y
sns.lmplot('PC1', 'y-axis', data=sklearn_result, fit_reg=False, # x-axis, y-axis, data, no line
scatter_kws={"s": 50}, # marker size
hue="label") # colorscit-learn을 사용하면 위에서 한 코드와 다르게 간단하게 주성분 분성을 할 수 있습니다.
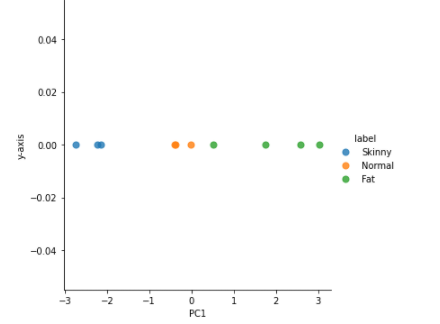
출처, 공부한 도서 - 나의 첫 머신러닝/딥러닝, 데이터분석전문가 가이드

Positive Vibe