Randon Forests
Random Forests 모델은 Decision Tree의 연장선이라고 생각하면 편하다. decision tree는 하나의 트리만 생성하기 때문에 상부에서 생긴 에러가 하부에게도 영향을 주고 트리의 깊이에 따라서 과적합이 되는 단점을 갖고 있다. 이러한 단점을 보완하는 것이 바로 random forests 모델이다.
Ensemble (앙상블)
random forests 모델은 Ensemble 방법이다. 앙상블 방법은 한 종류의 데이터로 여러 머신러닝 학습모델(weak base learner, 기본모델)을 만들어서 그 모델들의 예측 결과를 다수결이나 평균을 내어 예측하는 방법이다.
random forests는 결정트리를 기본모델로 사용하는 앙상블 방법이다. 여러 개의 decision tree를 결합해 하나의 decision tree보다 더 좋은 성능을 내는 방법이다.
Bagging (배깅) & Bootstraping (부트스트래핑)
Bagging은 Bootstrap Aggregating의 약자로 샘플을 여러번 뽑아서 각 모델을 학습시키는 방법이다. 이때 샘플은 복원추출을 하기 때문에 중복되어서 뽑힐 수 있다. 복원추출이란 샘플을 뽑아 값을 기록하고 다시 제자리에 돌려놓는 방법이기 때문에 같은 샘플이 아래의 데이터처럼 반복될 수 있다.
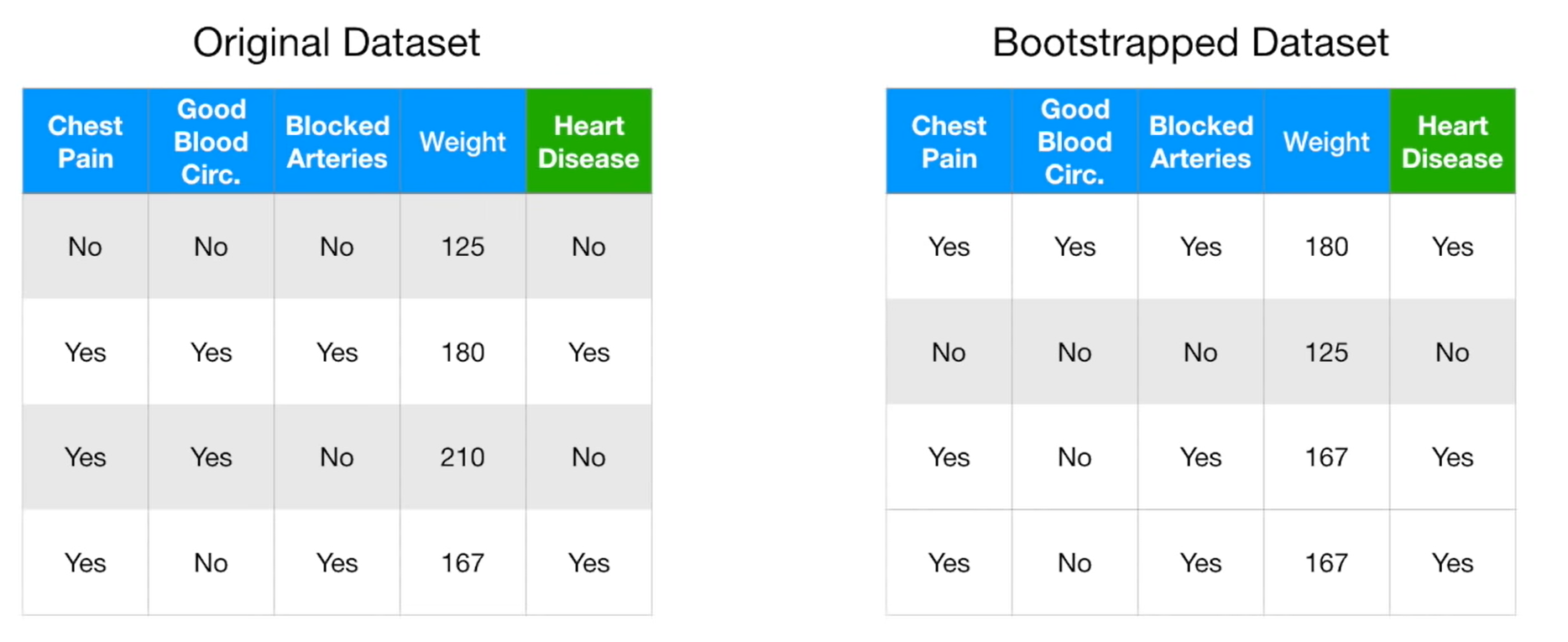
이때 위의 데이터에서 Bootstrapped Dataset에 속하지 못한 데이터들을 Out-Of-Bag 샘플이라고 부르며 줄여서 OOB라고 부른다. 이는 딱히 쓰이는 곳이 없기 때문에 (모델 내부에서는 쓰이지만 사용자가 따로 쓸 일이 없음) 그냥 이런게 있구나~ 하고 넘어가면 좋을 것 같다.
~ 추가 예정 Bootstraping과 Central Limit Theorem이 관련이 있다 ~
이렇게 만들어진 모델들을 합치는 과정을 Aggregation이라고 하며, 회귀문제일 경우에는 평균으로 결과를 내고 분류문제일 경우에는 다수결로 가장 많은 모델들이 선택한 범주로 예측을 하게 된다.
이러한 Bagging을 활용한 모델이 바로 Random Forests이다.
Ordinal Encoder
Ordinal Encoder는 순서형 인코딩 방법으로 범주에 숫자를 매핑하는 방법이다. 이 방법은 서로 연관성이 있을 경우에 사용하며, 연관성이 없을 경우에는 One-Hot Encoder를 사용하는 것이 좋다.
ordinal encoder는 범주를 숫자로 매핑하기 때문에 dataset의 feature가 늘어나지 않는 장점이 있다.
Tree ensemble이 과적합을 피할 수 있는 이유
- Random Forests에서 학습되는 tree들은 Bagging을 통해 만들어지는데 이때 사용되는 데이터가 랜덤으로 선택되기 때문이다.
- 각각의 트리는 무작위로 선택된 특성들을 가지고 분기를 수행하기 때문이다.
번외) Random Forests Pseudo code
그닥 중요하지 않은지 언급은 안됐지만 나름 정리를 한 김에 정리하면 좋을 것 같아서 하는 Random Forests의 Pseudo code.
Random Forests의 Pseudo code(의사코드)는 아래와 같다.

for문으로 B (tree의 개수)만큼 반복시키고 내부에서는 각 트리마다 부트 스트랩 샘플(Sᶤ)과 features(F)를 사용해 학습을 시킨다. 만들어진 트리 (hᵢ)를 전체 트리(H)에 합쳐준다.
트리를 학습 시키는 방법은 각 트리마다 어떤 특성의 set를 선택하고 분기들을 만들어서 트리를 생성한다. 그리고 완성된 트리를 return해준다.
