CUDA Shuffle Intrinsics
CUDA 에는 Warp 내 스레드 간 레지스터 수준으로 데이터를 교환할 수 있는 intrinsics 함수가 있음. 공유 메모리와 __syncthreads() 오버헤드를 줄여 성능을 높일 때 자주 사용됨. 주로 벡터 내적의 합 같은 연산에서 사용.
지원 버전: Compute Capability 3.0 이상
헤더:<cuda_runtime.h>or<device_launch_parameters.h>
공통 파라미터
-
unsigned mask- 동기화할 워프 비트마스크 (예:
0xFFFFFFFF→ 래인 0~31 전부)
- 동기화할 워프 비트마스크 (예:
-
int width(선택)- 워프 폭 (
2, 4, 8, 16, 32, 64), 기본값warpSize(보통 32) - 2진수로 설명하는 이유는 bitwise로 설명하기 유리하기 때문임
위의 표에서 보는것 같이 2의 지수배만큼 이동하는 칸이 다르기 때문에 지수배로 표시하는게 맞음Decimal 32-bit Binary 1 00000000 00000000 00000000 00000001 2 00000000 00000000 00000000 00000010 4 00000000 00000000 00000000 00000100 8 00000000 00000000 00000000 00001000 16 00000000 00000000 00000000 00010000 32 00000000 00000000 00000000 00100000 64 00000000 00000000 00000000 01000000
- 워프 폭 (
-
T var- 복사할 로컬 변수 (정수형, 부동소수형 모두 지원)
1. __shfl_up_sync
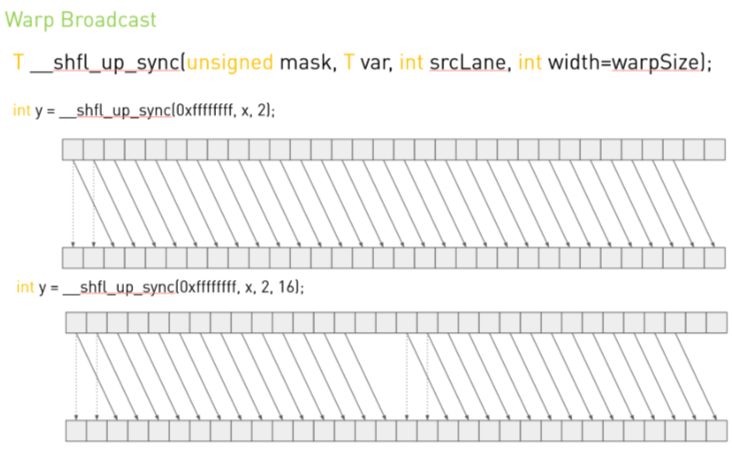
T __shfl_up_sync(unsigned mask,
T var,
unsigned delta,
int width = warpSize);- 동작: 각 레인은 자기보다 작은 래인 ID(낮은 인덱스를 가진 스레드)의 var 값을 획득
- 용도: 아래쪽 래인의 데이터를 위쪽으로 전달할 때
2. __shfl_down_sync

T __shfl_down_sync(unsigned mask,
T var,
unsigned delta,
int width = warpSize);- 동작: 각 레인은 자기보다 높은 래인 ID(높은 인덱스를 가진 스레드)의 var 값을 획득
- 용도: 워프 내 리덕션(합 계산) 등에 자주 사용
3. __shfl_xor_sync
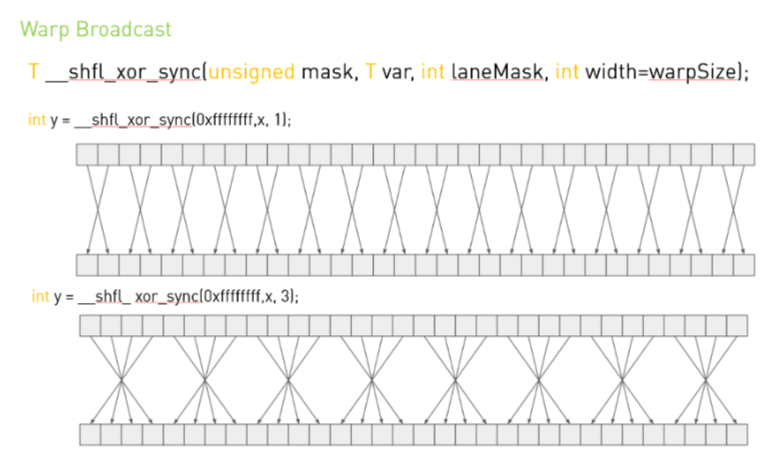
T __shfl_xor_sync(unsigned mask,
T var,
unsigned laneMask,
int width = warpSize);- 동작: 자신의 래인 ID와
laneMask를 비트 XOR한 결과 ID의 래인으로부터var복사 - 용도: Butterfly 패턴 기반 병렬 알고리즘(리덕션, 스캐터 등)
4. __shfl_sync
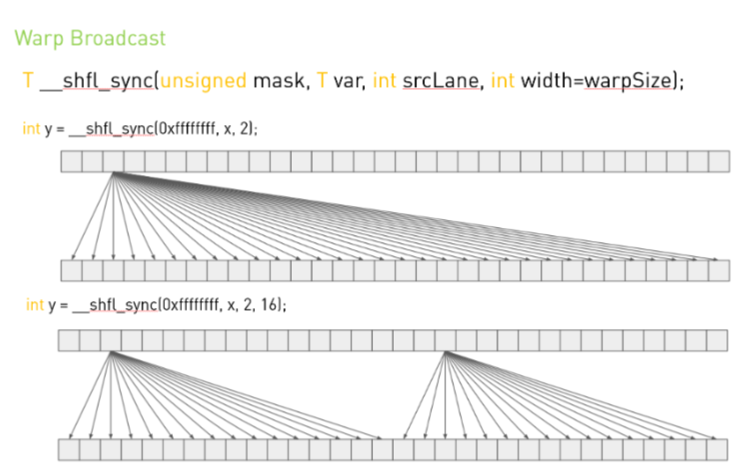
T __shfl_sync(unsigned mask,
T var,
int srcLane,
int width = warpSize);- 동작: 지정한
srcLaneID를 가진 래인의var값을 복사 - 용도: 워프 내 특정 스레드의 값을 전체 브로드캐스트할 때

imageprocessing and Data science