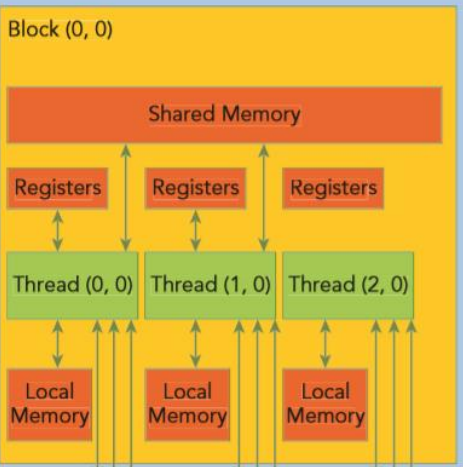
GPU 메모리 구조 개요
본인 사용중인 RTX 4090기준으로 스펙정리
(chip nam : AD102-300-A1)
1. On-Chip 메모리 계층
1.1 레지스터 (Registers)
- 위치: SM(Streaming Multiprocessor) 내부의 레지스터 파일
- 특징
- 4090기준 64K 32bit 레지스터가 개별 SM에 할당됨
- 쓰레드 전용, 컨텍스트 스위칭 오버헤드 제로
- “SM에 배치된 블록 수 × 블록당 쓰레드 수”로 계산되는 총 쓰레드 수에 따라 “SM 전체 레지스터 수”를 균등 분배가 되는 구조.
- 블록당 쓰레드 수 및 블록수가 많을 수록 개별 쓰레드에 할당되는 Resister 크기가 작아진다.
- 가장 낮은 레이턴시 (~1 사이클)
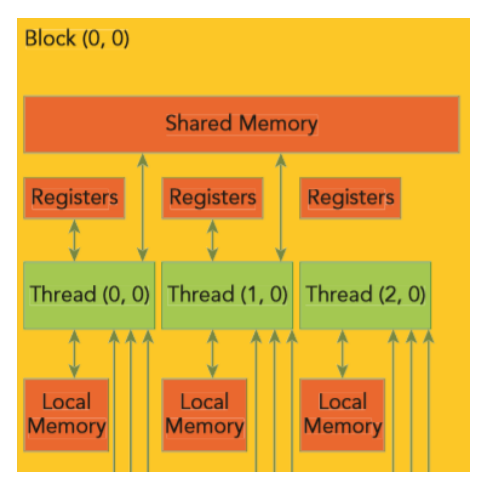
1.2 Shared 메모리 & L1 캐시
- 위치: SM당 온칩 SRAM 풀
- 특징
__shared__키워드로 소프트웨어 제어 가능- Shread memory는 블록단위로 미리 할당된 메모리 공간으로 미리 크기를 지정해줘야 함
- 뱅크(bank) 구조 → 뱅크 충돌 주의
- 글로벌 메모리 대비 10×~100× 빠른 접근
- L1 캐시와 물리 풀을 공유하는 경우가 많음
- 4090 기준 SM당 Shared Memory 크기는 100kB로 할당 되지만, 런타임 오버헤드용으로 예약된 1kb를 제외하고 실제로는 99kb 만 사용가능
2. Off-Chip 메모리 계층

RTX 칩 주변에 있는 GDDR을 의미하는 경우가 많고, 고급모델에서는 인터포저 위에 있는 HBM인 경우가 많음

2.1 L2 캐시
- 위치: SM 간 공유되는 온칩 SRAM (4090 기준 72MB)
- 역할: L1 miss 시 글로벌 DRAM 접근 전 중간 캐싱
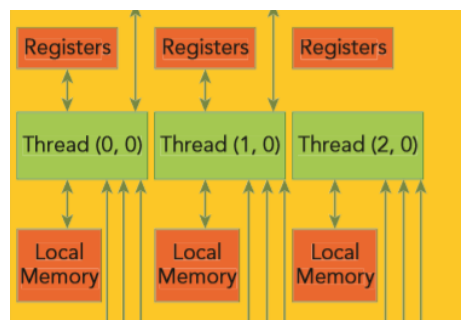
2.2 로컬 메모리 (Local Memory)
- 위치: RTX 4090 die 주변에 배치된 (GDDR) DRAM
- 특징
- 레지스터 부족할 때, 쓰레드 별로 DRAM(global memory)영역에 할당 되는 부분
- 기본적으로 사용하지 않는 쪽이 성능상으로 유리함
2.3 글로벌 메모리 (Global Memory)
- 위치: RTX 4090 die 주변에 배치된 (GDDR) DRAM
- 특징
- 대용량(RTX 기준 24GB), 높은 대역폭(RTX 기준 1.01 TB/s)
- 높은 레이턴시(수백 사이클) → Coalesced access 필수
- 호스트(PC) 메모리와
cudaMemcpy로 직접 데이터 교환
2.3 읽기 전용 캐시
- 상수 메모리(Constant Memory)
- GPU 내부 소규모 캐시
- 모든 쓰레드가 동일 주소 읽을 때 브로드캐스트
- 텍스처 메모리(Texture Memory)
- 2D/3D 공간적 지역성 최적화
- 하드웨어 필터링·래핑 기능 제공
3. 메모리 물리 배치 & 패키징
| 메모리 종류 | 물리적 위치 | 연결 방식 |
|---|---|---|
| GDDR5/6/7 | PCB 위 DRAM 칩 | 외부 비트 버스 (e.g. 256-bit) |
| HBM1/2/3 | 인터포저 위 다이 스택 | TSV + 인터포저 (e.g. 1024-bit) |
- 컨슈머 GPU: 대부분 GDDR 계열 사용
- 데이터센터 GPU: HBM + CoWoS/EMIB 패키징
4. 성능 최적화 포인트
- 레지스터 활용
- 변수 수 최소화 → 스필(spill) 방지
- Shared 메모리 타일링
- Global → Shared 로 묶어 읽은 뒤 재사용
- Coalesced Access
- 연속 쓰레드가 연속 주소 읽기 → 대역폭 최대화
- Occupancy vs. Register Trade-off
- 블록 크기 조절 → 레지스터 할당량 vs. 워프 점유율 균형

imageprocessing and Data science