개념
비지도 Anormaly Detection 중 하나로 현재 갖고 있는 데이터 중 이상치를 탐지할 때 주로 사용된다. tree 기반으로 구현되고, 랜덤으로 데이터를 split하여 모든 관측치를 고립시키며 구현된다. 변수가 많은 데이터에서도 효율적으로 작동한다는 장점이 있다.
각 관측치를 고립시키는 것은 이상치가 정상 데이터보다 쉽다.
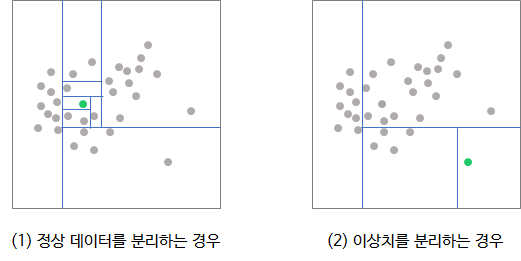
따라서 정상데이터를 분리하는 경우 약 7번의 split이 필요하고 이상치를 분리하는 경우에는 약 3번의 split이 필요하다. 정상 데이터는 tree의 terminal node와 근접하며, 경로길이가 크고, 이상치는 tree의 root node와 근접하며 경로길이가 작다.
itree를 여러번 반복하여 앙상블 한다.
itree
-
비복원 추출로 데이터 중 일부를 샘플링한다.
-
변수 선택: 데이터 X의 변수 중 q를 랜덤 선택
-
split point 설정: 변수 q의 범위 중 uniform하게 split point를 선택
-
1~3번 과정을 모든 관측치가 split되거나, 임의의 split 횟수까지 반복하며, 경로 길이를 모두 저장
-
위의 과정을 반복.
parameter 설명
- n_estimators: 나무의 개수. default = 100
- max_samples: 정수일 경우, 지정한 정수 개수만큼 각 나무 별로 데이터를 샘플링 함.
실수일 경우 전체 데이터 개수에 실수를 곱한 만큼의 데이터를 사용.
따로 지정하지 않았을 경우, 전체 데이터 개수와 256 중 작은 수를 사용 - contamination: 전체 데이터에서 이상치의 비율.
- max_features: 나무를 훈련할 때, 사용할 features 개수. default = 1

끊임없이 뭔가를 남기는 사람