
Object detection
input : 이미지 , 영상, 실시간
DNN : input 을 입력 시킴
output : 정확도, 무엇인지 출력
DNN : 인공신경망
Convolutional neural network (CNN) - 합성공 신경망
시각적 이미지 처리 할 때 쓰임. 입력 이미지로 부터 특징을 추출하여 어떤 이미지인지 클래스 분류
일반 신경망일 때, 입력을 하나의 데이터로 인식하여, 이미지의 특성을 찾지 못하여 올바른 성능 기대할 수 없음.하지만 CNN 은 여러 개로 분할 하여 처리. 왜곡 되더라도 부분적 특성을 추출!
이미지 -필터 - 분류 학습기 -Classification 의 구조로 구성이 됨.
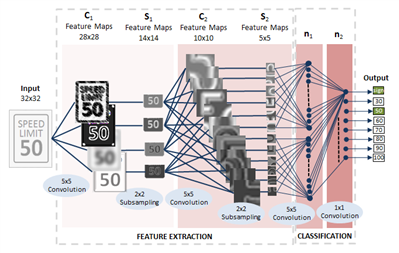
합성공 신경망 구조
: 신경망 구조에서 합성공 계층과 풀링 계층이 추가가 됨.
Pytorch -> ONNX ->TensorRT
-
AI framework (Pytorch ) 를 이용해 딥러닝 네트워크를 구성
-
Pre-trained network model
Image classification, Object detection , Semantic segmentation
나는 여기서 Object detection 의 SSD-Mobilenet 을 사용함
SSD-Mobilenet-v2 (91 종류의 객체를 포함하는 MS COCO dataset을 학습한 모델)
아래를 참고하면 더욱 자세히 ssd 를 알 수 있다.
https://github.com/qfgaohao/pytorch-ssd
https://github.com/dusty-nv/pytorch-ssd/tree/8ed842a408f8c4a8812f430cf8063e0b93a56803
-
ONNX
서로 다른 Framework 사이에서 네트우크 모델 이동할 수 있음
ONNX 를 통해 Pytorch 에서 TensorRT 로 연결하기 위해 사용한다. -
Tensor RT
훈련된 네트워크 모델을 실시간으로 돌릴 수 있는 프로그램
입력 : 이미지 -> 객체 인식
- Docker container 내로 접속한다.
detectnet.py --network=ssd-mobilenet-v2 data/images/peds_2.jpg data/images/test/output.jpg여기서는 peds_2.jpg 이미지를 처리한 결과가 output.jpg 로!


다음과 같이 성공적으로 객체 인식이 잘 된 것을 확인할 수 있다.
입력 : 실시간 -> 객체 인식
- Docker container 내로 접속한다.
그 후 다음과 같은 코드를 입력한다.
detectnet.py --network=ssd-mobilenet-v2 --input-width=400 --input-height=300 csi://0그 결과, 카메라로 실시간으로 데이터 입력이 주어져도 객체를 잘 인식되는 것을 확인할 수 있다.

나를 사람으로 인식한다! 우아아앙 !!!!!!!
근데 얼굴은 가리는게 좋을 거 같아 가려버렸다.
사실 머신러닝을 입문한지 별로 안되어 Object detection 이론을 들을 때 어려움을 겪었다.
Computer vision 과 Deep learning 의 교집합인 Object detection 에 대해서 공부를 더 하여야 겠다.
사실 프로젝트 진행을 위해, 머신 러닝을 자세히 공부하지는 못하였다 ㅠㅠ
프젝이 끝난 후 , 더 구체적으로 혼자 학습하여야 겠다.
cf ) 강사님이 참고하라고 준 자료들!
https://www.youtube.com/watch?v=BfzUCEXmOm0
https://szeliski.org/Book/drafts/SzeliskiBook_20100903_draft.pdf
https://www.youtube.com/playlist?list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN
https://www.youtube.com/watch?v=vT1JzLTH4G4
http://cs231n.stanford.edu/
https://arxiv.org/pdf/1512.02325.pdf
https://arxiv.org/pdf/1704.04861.pdf
https://cocodataset.org/#overview
https://colab.research.google.com/drive/1G9ecWl7AXFsid4LSholy_I_wgrHkoxAm?usp=sharing
https://blog.naver.com/msjh0329/222196011529
