Pandas (Python Data Analysis Library)
- pandas dataframe의 3요소: row(행), column(열), index
- pandas dataframe은 다양한 data type(list, dictionary, array 등)을 이용해 생성할 수 있음.
- pandas dataframe은 데이터를 table 형태(가로/세로축이 있는 2차원 데이터)로 처리할 수 있게 하여 데이터 전처리와 같은 핸들링을 할 수 있음.
- pandas에서 row는 axis=0이며, column은 axis=1
- dataframe은 n개의 series가 합쳐진 형태(즉, dataframe 안에서 1개의 column이 series)
import pandas as pd
pd.DataFrame(data = None, index = None, columns = None, dtype = None, copy = False) # DataFrame의 parameter
1) data: list/dictionary/array 등 data type을 인자로 넣음. # parameter명 생략 가능
2) index: 사용자가 원하는 index를 부여할 수 있음(default: range(0, len(data))에 해당하는 index).
3) columns: 컬럼명(즉, 변수명).
4) dtype: DataFrame안에 들어갈 데이터의 type(하나의 데이터는 하나의 dtype만 허용).
5) copy: * 잘 사용하지 않음.참고) https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
1. Dataframe 생성.
1.1. list
import pandas as pd
data_list = [['A', 11],['B',22],['C',33]]
df = pd.DataFrame(data_list, columns = ['Name','Num'])
print(df)
Name Num
0 A 11
1 B 22
2 C 33import pandas as pd
data_list = [['A',11],
['B',22],
['C',33]]
df2 = pd.DataFrame(data_list, index = ['group1', 'group2', 'group3'], columns = ['Name','Num'])
print(df2)
Name Num
group1 A 11
group2 B 22
group3 C 331.2. dictionary
data_dic = {'Name' : ['A','B','C'],'Num':[11,22,33]}
df = pd.DataFrame(data_dic, index = ['group1', 'group2', 'group3'])
print(df)
Name Num
0 A 11
1 B 22
2 C 331.3. array
import numpy as np
1.3.1.
data_numpy = np.array([['A',11],
['B',22],
['C',33]])
df = pd.DataFrame(data_numpy, columns = ['Name','Num'])
print(df)
Name Num
0 A 11
1 B 22
2 C 331.3.2.
data_numpy_1 = np.arange(0, 5)
data_numpy_2 = data_numpy_1 * 3
data_numpy_3 = ['A','B','C','D','E']
df = pd.DataFrame({'column_1' : data_numpy_1,
'column_2' : data_numpy_2,
'column_3' : data_numpy_3})
print(df)
column_1 column_2 column_3
0 0 0 A
1 1 3 B
2 2 6 C
3 3 9 D
4 4 12 E2. excel -> dataframe, dataframe -> excel
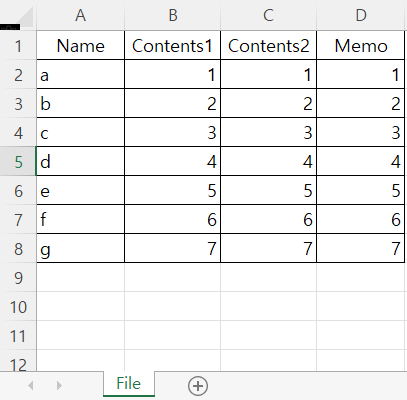
- 파일명: df_excel_test.xlsx
2.1. excel -> dataframe
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)[source]
import pandas as pd; import openpyxl
df = pd.read_excel('df_excel_test.xlsx', engine = 'openpyxl')
df
Name Contents1 Contents2 Memo
0 a 1 1 1
1 b 2 2 2
2 c 3 3 3
3 d 4 4 4
4 e 5 5 5
5 f 6 6 6
6 g 7 7 7engine = 'openpyxl'없이, read_excel 사용시(.xlsx 파일 호출) 에러 발생.
- XLRDError: Excel xlsx file; not support
2.1.1. sheet_name
- excel 파일에 여러 sheet가 있는 경우, 원하는 sheet를 불러올 때 사용하는 parameter
- 위의 그림에서는 sheet_name = 'File'
2.1.2. header
- row의 title이 실행되는 위치 지정.
- title이 excel 파일 2번째 행에 있는 경우, header = 1
2.1.3. index_col
- 특정 column을 index로 설정.
- 방법1 index 번호 활용: index_col = 0
- 방법2 column명 활용: index_col = 'a'
2.1.4. usecols
- excel내 특정 column들만 dataframe으로 변환.
- A와 D column만 불러올 경우, usecols = 'A, D'
2.1.5. names
- column명 변경.
- dataframe의 column 수와 동일한 수가 names의 변수로 들어가야 함(names는 list 형태).
- excel -> dataframe 과정에 column명을 변경해주는 것으로, dataframe 생성을 한 후에도 변경 가능.
2.2. dataframe -> excel
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_excel.html
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=_NoDefault.no_default, inf_rep='inf', verbose=_NoDefault.no_default, freeze_panes=None, storage_options=None)
df.to_excel('df_excel_test_output.xlsx')
2.2.1. sheet_name
- sheet_name = '적용할 sheet명' 옵션 적용시 해당 sheet명으로 저장(기본 값은 Sheet1).
2.2.2. index
- index = False 옵션 적용시 index 없이 저장.
2.2.3. header
- header = False 옵션 적용시 colunm명 없이 저장.
참고) 2개 이상의 sheet로 excel에 저장(pd.ExcelWriter())
#dataframe을 2개 만들고 각각의 dataframe을 각각의 sheet에 저장
with pd.ExcelWriter('df_excel_test_output1.xlsx') as writer:
df1.to_excel(writer, sheet_name='sheet1')
df2.to_excel(writer, sheet_name='sheet2')#특정 조건에 따라 저장될 sheet 구분.
aa = (df['변경할 column명_1'] == 'a') | (df['변경할 column명_1'] == 'b') | (df['변경할 column명_1'] == 'c') | (df['변경할 column명_1'] == 'd')
bb = (df['변경할 column명_1'] == 'e') | (df['변경할 column명_1'] == 'f') | (df['변경할 column명_1'] == 'g')
with pd.ExcelWriter('df_excel_test_output2.xlsx') as writer:
df[aa].to_excel(writer, sheet_name='a부터 d까지')
df[bb].to_excel(writer, sheet_name='e부터 g까지')
#참고) 여러 조건을 함께 사용할 때에는 괄호( )안에 각각의 조건을 넣어주어야 함.
2.3. txt 불러와서 excel로.
input_name = input('파일명 입력: ')
df2 = pd.read_csv(input_name+'.txt',sep="\t",encoding='ANSI'); print(df2)
df2.to_excel(input_name+'.xlsx',index=False)3. Dataframe 수정
3.1. Dataframe column명 변경
df.columns #column명 전체 조회방법1) 기존 column명 순서에 맞춰 변경할 column명을 list 타입으로 넣어줌.
df.columns = ['change_1', 'change_2', 'change_3']방법2) rename() 함수 활용.
df.rename(columns = {'기존 column명' : '변경할 column명'}) # 1:1
df.rename(columns = {'기존 column명_1' : '변경할 column명_1', # 3:3
'기존 column명_2' : '변경할 column명_2',
'기존 column명_3' : '변경할 column명_3'}, inplace=True)
3.2. Dataframe column 순서 변경
1) 변경할 순서에 맞춰 column명 배치.
df = df[['Type', 'Rank', 'ID']]2) reindex()함수 활용.
df = df.reindex(columns=['변경할 column명_2', '변경할 column명_3', '변경할 column명_1'])- inplace=True 옵션을 적용해야 df의 수정 사항이 적용 저장됨.
3.3. Dataframe 병합
pd.concat()
- pd.concat()의 인자는 list type.
- 중복된 row가 있더라도 그대로 합쳐줌.
pd.concat([df1, df2]) #세로로 병합(axis = 0; default)
pd.concat([df1, df2], axis=1) #가로로 병합- 이외에 pd.merge(), df.append(), df.join()가 있음.
3.4. Dataframe 인덱스 초기화
https://seong6496.tistory.com/73
3.5. 값이 0으로만 구성된 column 추가
np.zeros([7, 1]) # 7x1으로 구성된 값 생성
df['칼럼명'] = np.zeros([7, 1]) #생성되어 있는 데이터프레임에 '칼럼명'이란 column 생성하고, 7x1 만큼 0으로 구성된 값 추가
4. Dataframe 조회
https://rfriend.tistory.com/460
https://computer-science-student.tistory.com/375
https://kimdingko-world.tistory.com/206
4.1. Dataframe 특정값 가져오기(loc, lioc)
loc (location)
- Access a group of rows and columns by label(s) or a boolean array.
- dataframe의 row나 column을 label(또는 boolean array)로 접근.
- row는 index로 접근 가능, column은 label(변수명)로 접근.
.loc(row index, 'column label')- 칼럼명 생략시, loc(row index) 조건에 맞춰 접근.
lioc (integer location)
- Purely integer-location based indexing for selection by position.
- dataframe의 row나 column을 index로 접근.
- row와 column 모두 index로 접근.
.iloc(row index, column index)- column index 생략시, iloc(row index) 조건에 맞춰 접근.
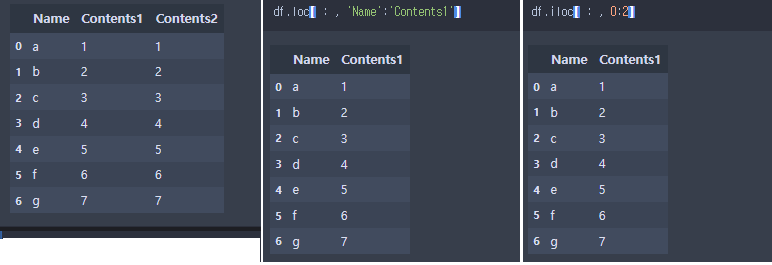
column label(loc) 또는 column index(iloc)는 생략되어도 되는데 row index(loc/lioc)는 생략되면 안됨(' : '로 공란이라도 넣어주어야 함).
.loc가 boolen array값을 통해 데이터에 접근한다는 점을 활용하여, 특정 조건에 맞는 cell에 접근.
경우1) 대/소 관계 활용.
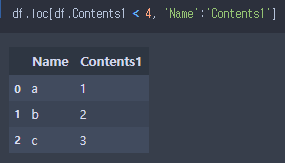
경우2) isin() 활용.
- isin() 사용시, 조건을 만족하는 boolean값을 return.
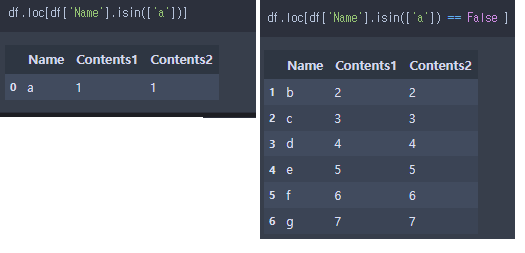
iloc로 특정행에 접근 + 해당 행/열에 특정 값 넣어주기
# # iloc을 사용하여 값에 접근할 때는 값을 변경할 수 없음. 대신 iloc을 사용하여 위치를 선택한 후, .at이나 .iat을 사용하여 해당 위치의 값을 변경
if df_work.iloc[nn]['ATTRIBUTE'] == '내용':
df_work.at[nn, 'ID'] = df_domain.iloc[n]['ID']
df_work.at[nn, 'A_Key'] = e
df_work.at[nn, 'Q_format'] = M_MP_T_1_14.2. Dataframe data 개수 counting
Length of values does not match length of index 오류
http://net-informations.com/ds/err/length.htm
4.3. 특정 조건 만족하는 data frame 조회
4.4. 특정 행/열 min/max 구하기
df.max(axis = 1, numeric_only = True) #axis = 1은 행 기준, default: axis = 0 (열기준)https://jimmy-ai.tistory.com/254
5. Data type 변경
5.1. Data 삭제
5.1.1. 중복값 삭제
중복 데이터가 있는지 탐색(중복되는 row를 탐색).
- .duplicated(): 중복값(row 기준) 여부를 bool 형태로 return(중복값 o = True, 중복값 x = False).
df.duplicated()중복 데이터 삭제(중족되는 row를 기준으로).
- drop_duplicates()
df.drop_duplicates().duplicated()와 drop_duplicates()는 row를 기준으로 한다. column을 기준으로 중복값을 찾고 삭제하려면 dataframe의 형태를 바꿔주어야 한다.
- .T: dataframe의 index와 column 을 바꿔줌(Transpose index and columns).
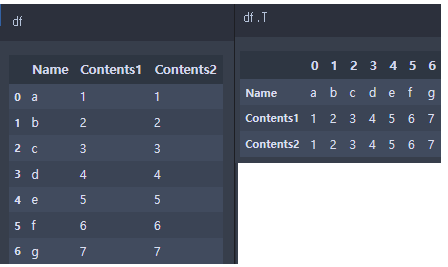
중복 데이터가 있는지 탐색(중복되는 column을 탐색).
df.T.duplicated()중복 데이터 삭제(중복되는 column을 기준으로).
df.T.drop_duplicates()중복되는 column 삭제 후, 원래 형태로 변형.
df.T.drop_duplicates().Thttps://www.statology.org/pandas-drop-duplicate-columns/
5.1.2. 결측치 삭제
결측값이 있는지 탐색.
- .isnull(): 결측값 여부를 bool 형태로 return(결측치o = True, 결측x = False).
결측치 삭제 방법.
1) 결측값이 있는 row(또는 column) 삭제.
- dropna()
df.dropna(axis = 0) # row 기준, 결측치가 있는 cell의 row 전체를 삭제.
df.dropna(axis = 1) # column 기준, 결측치가 있는 cell의 column 전체를 삭제.
df.dropna(how = 'all') # row 기준, row에 포함된 cell이 전부 결측값일 경우 해당 행을 삭제.
df.dropna(thresh = n) # row 기준, row에 포함된 n개 이상의 cell이 결측값일 경우 해당 행을 삭제.https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html
2) 결측값 위치에 새로운 값을 넣어줌.
- fillna()
df.fillna(n) # 결측치(NaN)를 특정 값(n)으로 채워줌.https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html
3) index를 활용한 삭제
- .drop()
Remove rows or columns by specifying label names and corresponding axis, or by specifying directly index or column names. When using a multi-index, labels on different levels can be removed by specifying the level.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop.html
** 특정 값이 결측값(nan)인지 확인하는 방법,
import pandas as pd
# 변수 a가 NaN인지 확인
if pd.isna(a):
print('결측값')6. 특정 값에 해당하는 데이터만 필터링
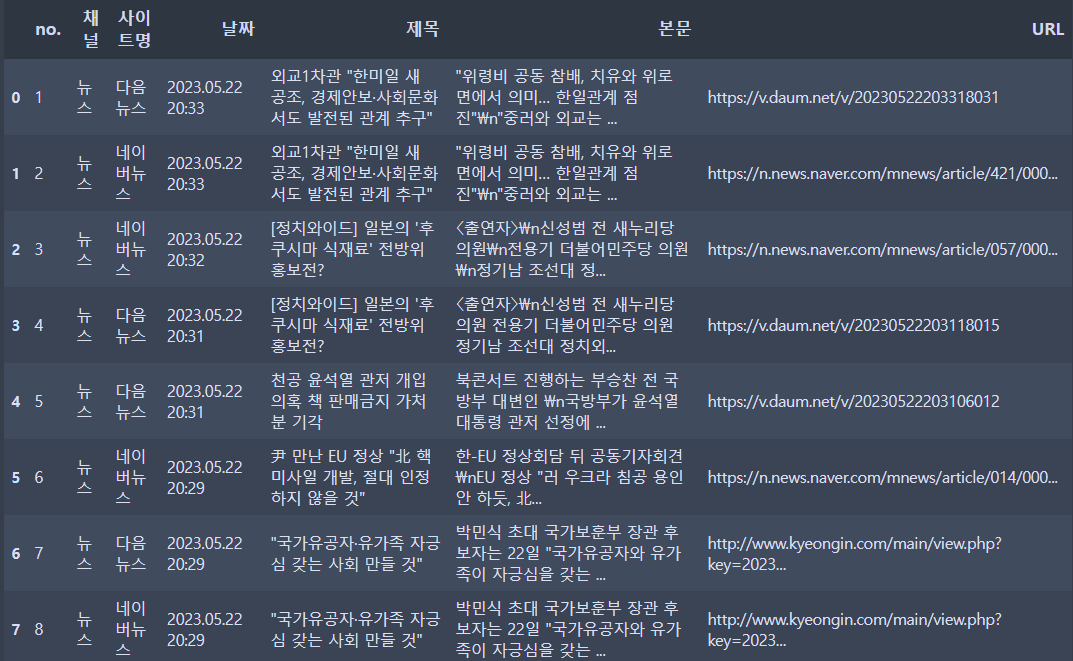
예) df['사이트명']에는 '네이버뉴스', '다음뉴스', '네이트뉴스'가 있음.
- 이 때 '네이버뉴스'만 보고 싶을 땐,
only_naver = df['사이트명'] == '네이버뉴스'
df_naver = df[only_naver]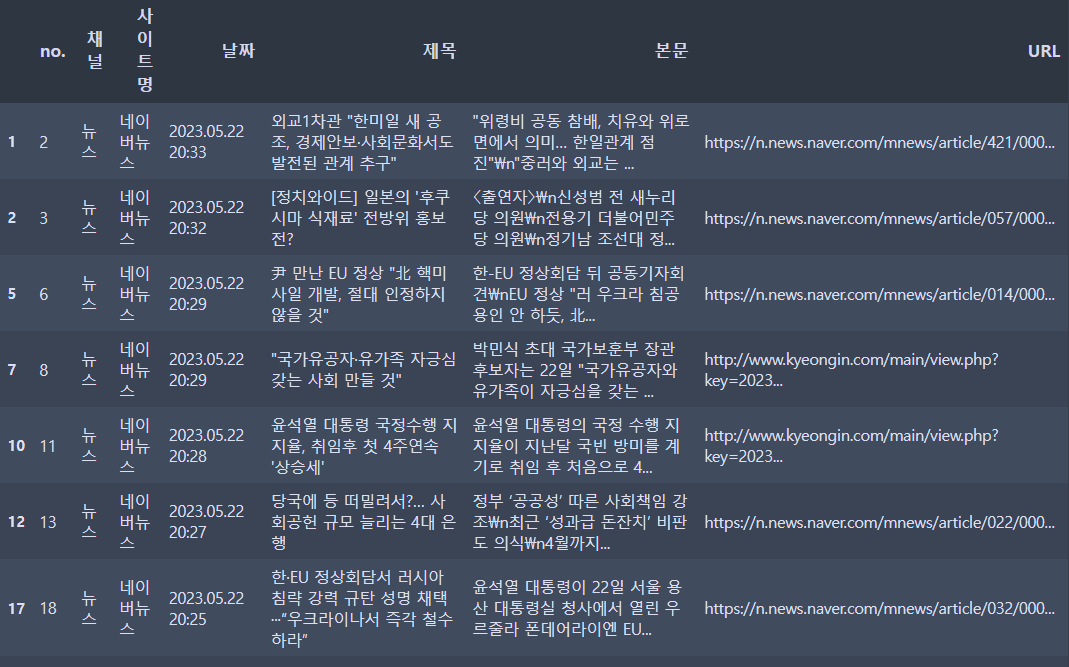
dataframe Index 조작
10. 에러 관련
DataFrame에 수정 명령줄 시, pandas가 warning 메시지 보냄
- SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame
import pandas as pd
pd.set_option('mode.chained_assignment', None) # 경고 off