k-평균 알고리즘
k-평균 알고리즘은 비지도 학습의 한 유형으로, 데이터 포인트를 k개의 클러스터로 그룹화하는데 사용된다. 이 알고리즘은 각 클러스터의 중심을 반복적으로 업데이트하여 데이터 포인트를 가장 가까운 클러스터에 할당하는 방식으로 작동한다.
✔️ 작동 방식
- 초기 클러스터 중심 설정
- k개의 클러스터 중심(센트로이드)을 무작위로 선택
- 클러스터 할당
- 각 데이터 포인트를 가장 가까운 클러스터 중심에 할당
- 클러스터 중심 재계산
- 각 클러스터에 속한 데이터 포인트의 평균값을 계산하여 새로운 클러스터 중심 생성
- 반복
- 클러스터 중심이 변경되지 않을 때까지 2~3단계 반복
KMeans 클래스
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42) #3개의 클러스터
km.fit(fruits_2d)
print(km.labels_) # 0 ,1, 2, (n_clusters=3)
# 레이블 별 샘플 개수 확인
print(np.unique(km.labels_, return_counts=True))
#출력 (array([0, 1, 2], dtype=int32), array([111, 98, 91]))sklearn.cluster.KMeans는 K-평균 알고리즘을 구현한 클래스이다.
✔️ 주요 매개변수
n_clusters: 클러스터의 수를 지정random_state: 반복 결과의 재현성을 위해 설정n_init: 클러스터 중심의 초기화를 몇 번 수행할지 지정
클러스터 중심
1. 클러스터 중심과 샘플 분석
클러스터 중심을 통해 각 클러스터의 특성을 파악할 수 있다. 이미지 데이터를 사용한다면 클러스터 중심을 이미지로 시각화하여 각 클러스터의 평균적인 특성을 확인할 수 있다.
# 각 클러스터 이미지 출력
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr)
rows = int(np.ceil(n/10)) # 행의 개수
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n:
axs[i, j].imshow(arr[i*10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
#draw_fruits(fruits[km.labels_==0]) #0레이블의 샘플만 이미지 출력
#draw_fruits(fruits[km.labels_==1])
#draw_fruits(fruits[km.labels_==2])
#draw_fruits(fruits[km.labels_==0]) #0레이블의 샘플만 이미지 출력
#draw_fruits(fruits[km.labels_==1])
#draw_fruits(fruits[km.labels_==2])
# 각 중심의 이미지 출력
draw_fruits(km.cluster_centers_.reshape(-1, 100, 100), ratio=3)
# 각 클러스터 중심까지 거리
print(km.transform(fruits_2d[100:101])) #100번째 샘플
#출력 [[3393.8136117 8837.37750892 5267.70439881]]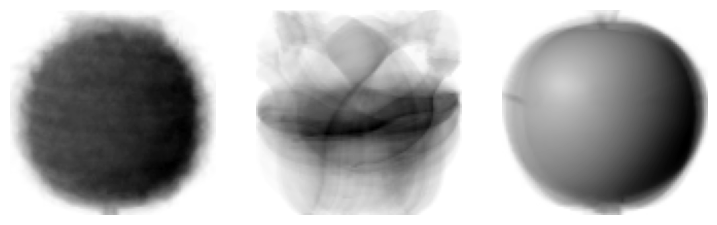
km.labels_를 통해 각 데이터 포인트가 어느 클러스터에 속하는지 알 수 있다. 이를 통해 각 클러스터의 데이터 분포를 파악할 수 있다.
2. 클러스터 중심과 데이터 포인트 간 거리
# 각 클러스터 중심까지 거리
print(km.transform(fruits_2d[100:101])) #100번째 샘플
#출력 [[3393.8136117 8837.37750892 5267.70439881]]
# 클러스터 예측
print(km.predict(fruits_2d[100:101]))
#출력 [0]km.transform(data)를 사용하면 데이터 포인트와 각 클러스터 중심 사이의 거리를 계산할 수 있다. 이를 통해 특정 데이터 포인트가 어느 클러스터에 가장 가까운지 알 수 있다.
km.predict(data)는 주어진 데이터 포인트가 어느 클러스터에 속할지 예측한다.
최적의 클러스터 수 찾기
실전에서는 몇 개의 클러스터가 최적인지 알기 어렵다. 최적의 클러스터 수를 찾기 위해 *이너셔(inertia)를 사용한다.
💡 이너셔
각 데이터 포인트와 그 클러스터 중심 사이의 제곱 거리의 합이다.
클러스터 수가 증가하면 이너셔는 감소하지만, 클러스터 수가 너무 많으면 클러스터링 효과가 줄어든다.
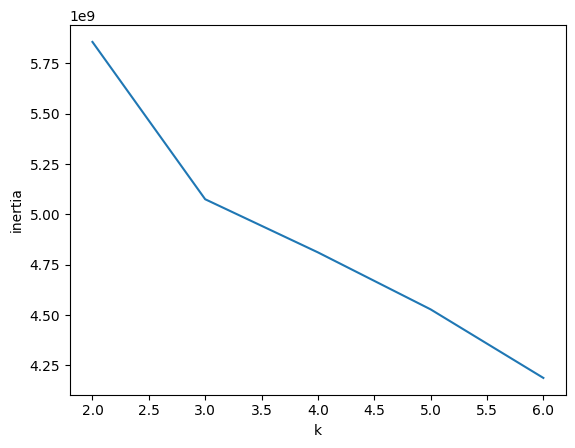
1. 엘보우
엘보우 방법은 이너셔의 변화를 시각화하여 최적의 클러스터 수를 결정하는데 사용된다. 이너셔의 감소가 완만해지는 지점이 최적의 클러스터 수이다.
# 2~6개 클러스터로 설정하여 KMeans 훈련
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_) #이너셔 값
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()