
Transformer
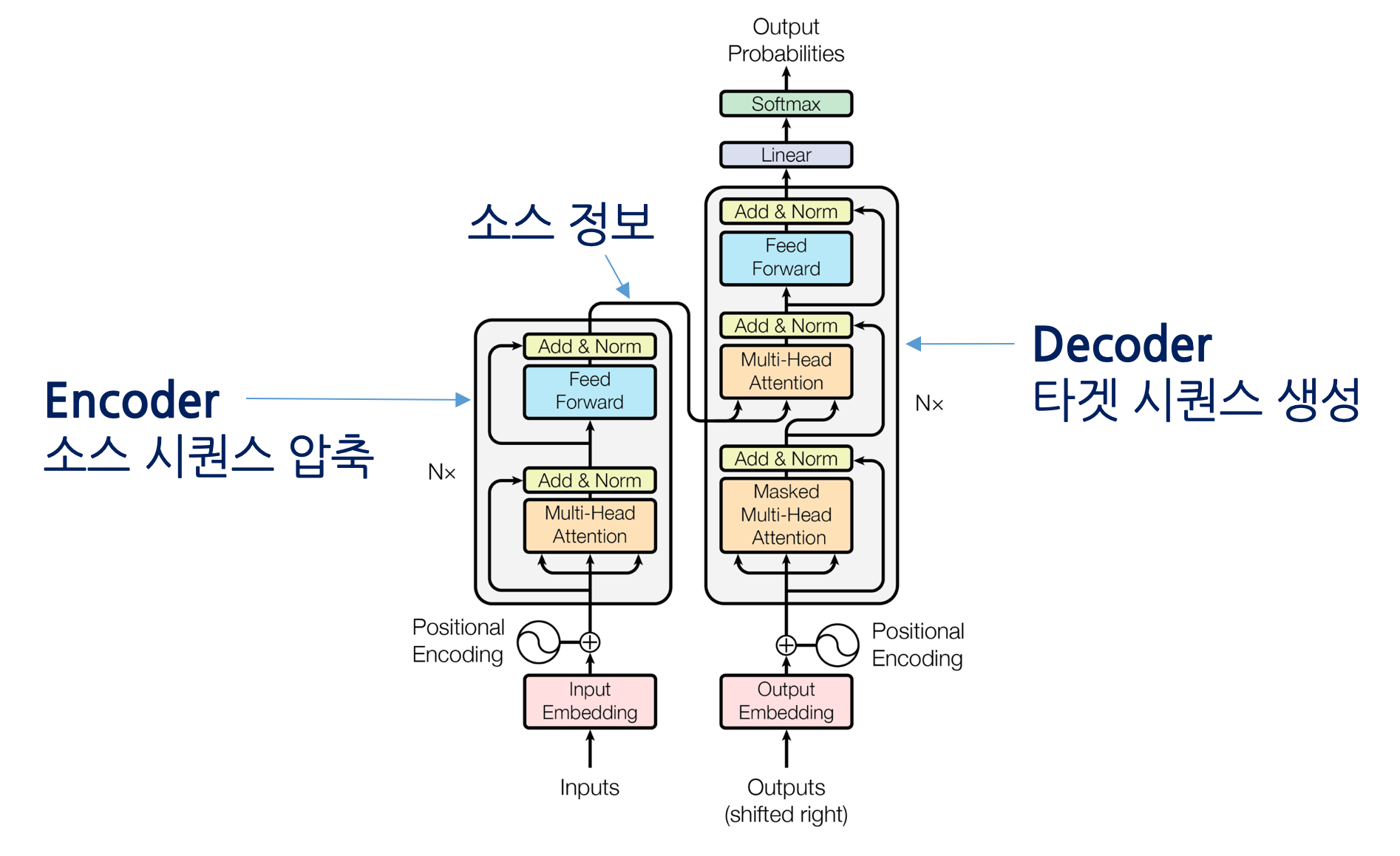
Transformer는 큰 범주에서 인코더 디코더로 나누어져있다. 두 불록은 디테일에서 차이가 있을 뿐, 본질적으로 크게 다르지 않다.
Encoder
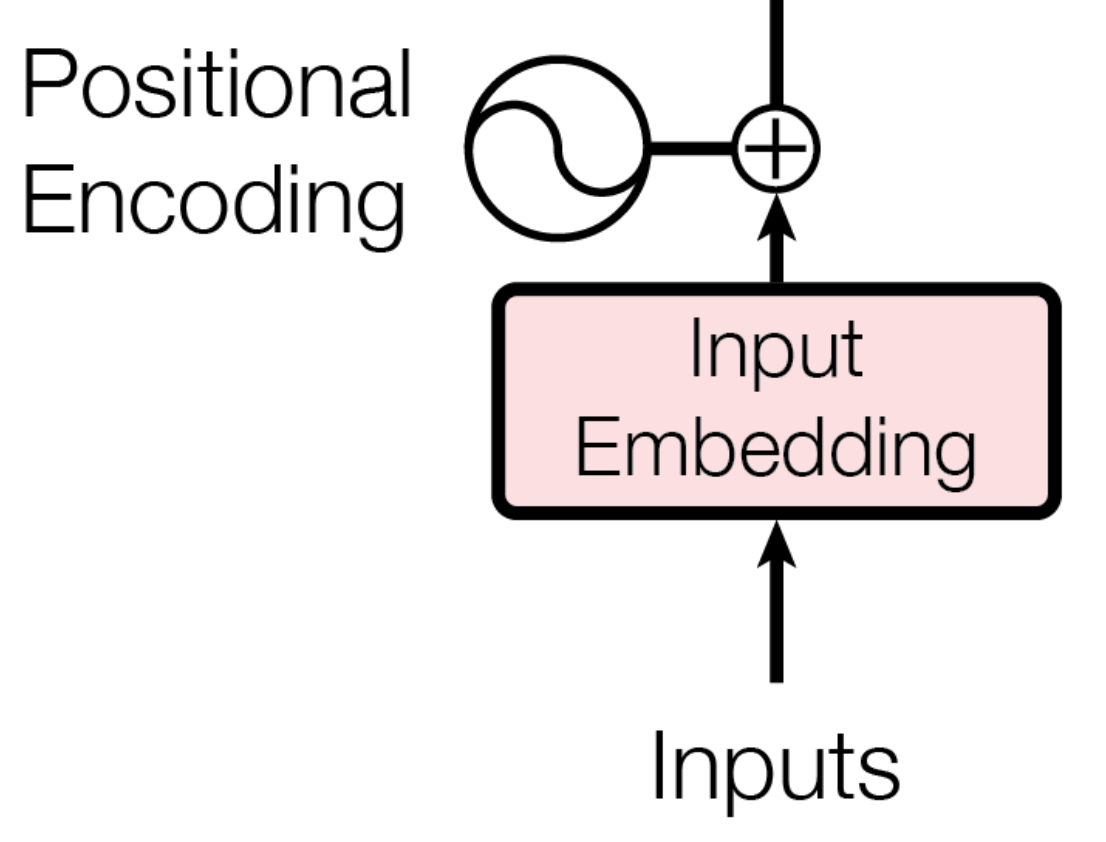
인코더의 입력은 Input Embedding과 Positional Encoding을 더해서 만들어진다.Input Embedding은 BPE (Byte Pair Encodding)을 사용한다. Positional Encoding은 문장 내에서의 단어 위치를 나타낸다. 이렇게 만들어진 입력은 Encoder의 첫번째 입력이 되며, 해당 Encoder의 출력은 두번째 Encoder의 입력이 된다. 이를 N번 반복한다.
Output Layer
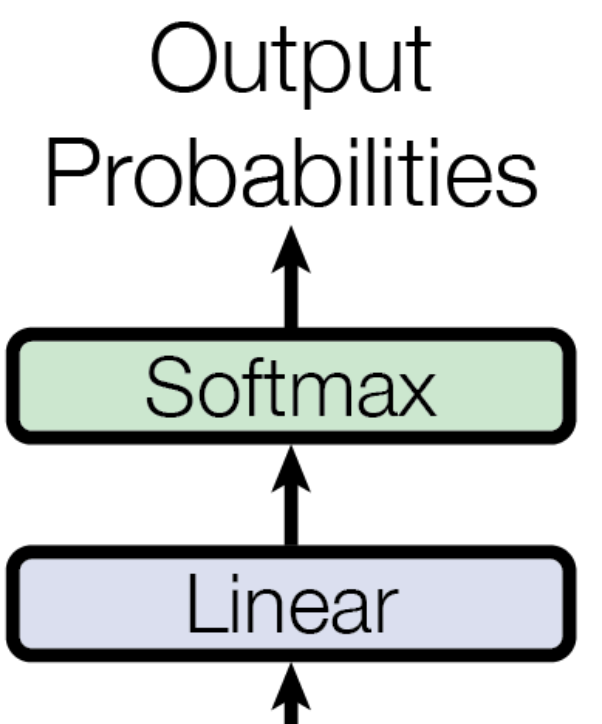
출력층의 출력은 타깃 언어의 어휘 만큼의 차원을 갖는 확률 벡터가 된다 (Softmax의 결과). 트랜스포머의 학습은 인코더와 디코더의 입력이 주어졌을 때, 모델의 최종 출력에서 정답에 해당하는 단어의 확률값을 높이는 방식으로 수행된다.
Self Attention - Encoder
(1) Query, Key, Value 만들기
셀프어텐션은 Query(쿼리), Key(키), Value(벨류) 요소 사이의 문맥적 관계성을 추출하는 과정이다. X라는 시퀀스가 있을 때, 행렬 곱을 이용해서 아래와 같이 Q, K, V를 만든다. (이떄 시퀀스가 n개 이면 $ n * 3$ 개의 벡터가 생성된다.
(2) 셀프 어텐션 출력값 계산하기
Query와 Key를 행렬곱한 뒤, 해당 행렬의 모든 요소 값을 Key 차원수의 제곱근 값으로 나누워주고, 이 행렬을 Row 단위로 Softmax를 취해 스코어 행렬을 만들어 준다. 이 스코어 행렬에 Value를 행렬곱해줘서 셀프어텐션 계산을 마친다.
(3) Multi-Head Attention
Multi-Head Attention은 Self Atention을 여러번 수행한 것을 일컫는다. 여러 헤드가 독자적으로 Self Attention을 계산합니다.

입력 단어 수는 2개, Value의 차원수는 3, Head는 8개인 멀티-헤드 어텐션을 나타낸 그림입니다. 개별 헤드의 셀프 어텐션 수행 결과는 ‘입력 단어 수 × Value 차원수’, 즉 2×3 크기를 갖는 행렬입니다. 8개 헤드의 셀프 어텐션 수행 결과를 다음 그림의 ①처럼 이어 붙이면 2×24 의 행렬이 됩니다.
Multi-Head Attention은 개별 헤드의 셀프 어텐션 수행 결과를 이어붙인 행렬(①)에 를 행렬곱해서 마무리됩니다. 의 크기는 ‘셀프 어텐션 수행 결과 행렬의 열(column)의 수 × 목표 차원수’가 됩니다. 만일 Multi-Head Attention 수행 결과를 그림9와 같이 3차원으로 설정해 두고 싶다면 는 24×3 크기의 행렬이 되어야 합니다.
Encoder 에서의 Self Attention
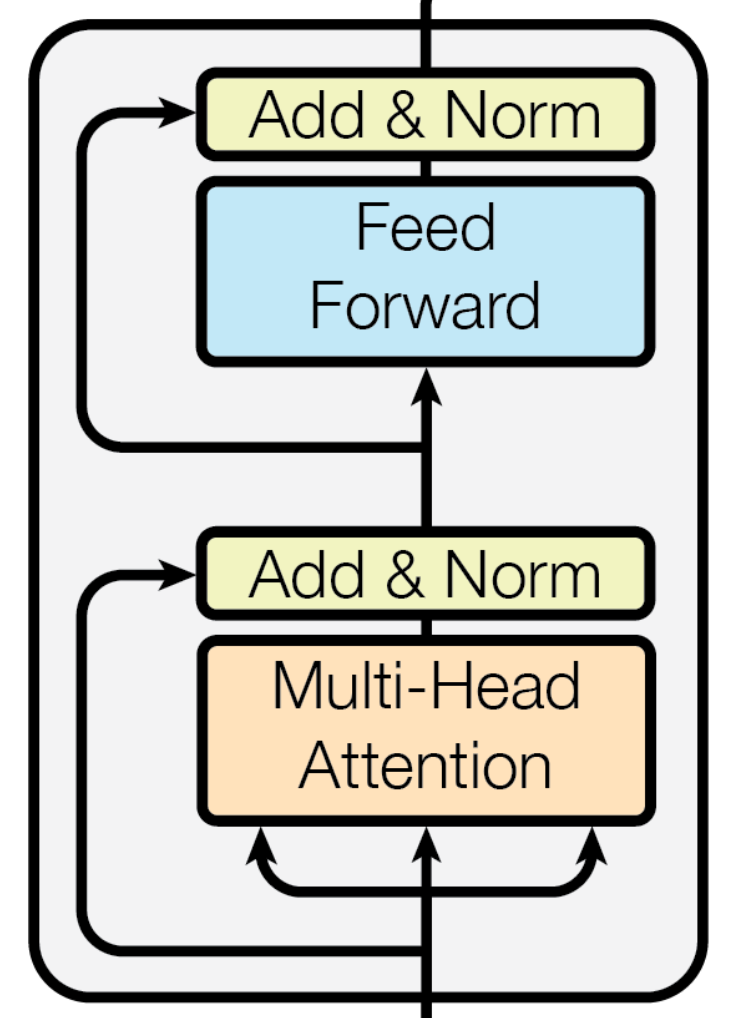
인코더의 셀프어텐션은 Query, Key, Value가 모두 소스 시퀀스와 관련되어 있다. 즉 번역 Task라면 Q,K,V가 모두 한국어라는 것이다. 따라서 한 시퀀스에서 A라는 단어가 B라는 단어와 관계가 높다면, Softmax값이 가장 높을 것이고, 이것이 Value 벡터와 가중합 되서 셀프 어텐션 계산을 마친다.
결론적으로 인코더에서의 Self Attention은 소스 시퀀스 내의 모든 단어 Pair와의 관계를 고려하게 된다. 참고로 Attention Score 행렬의 (i, j) 요소는 i번째 입력값 (Query)와 j번쨰 입력값 (Key, Value) 사이의 유사도를 의미한다.
Self Attention - Decoder
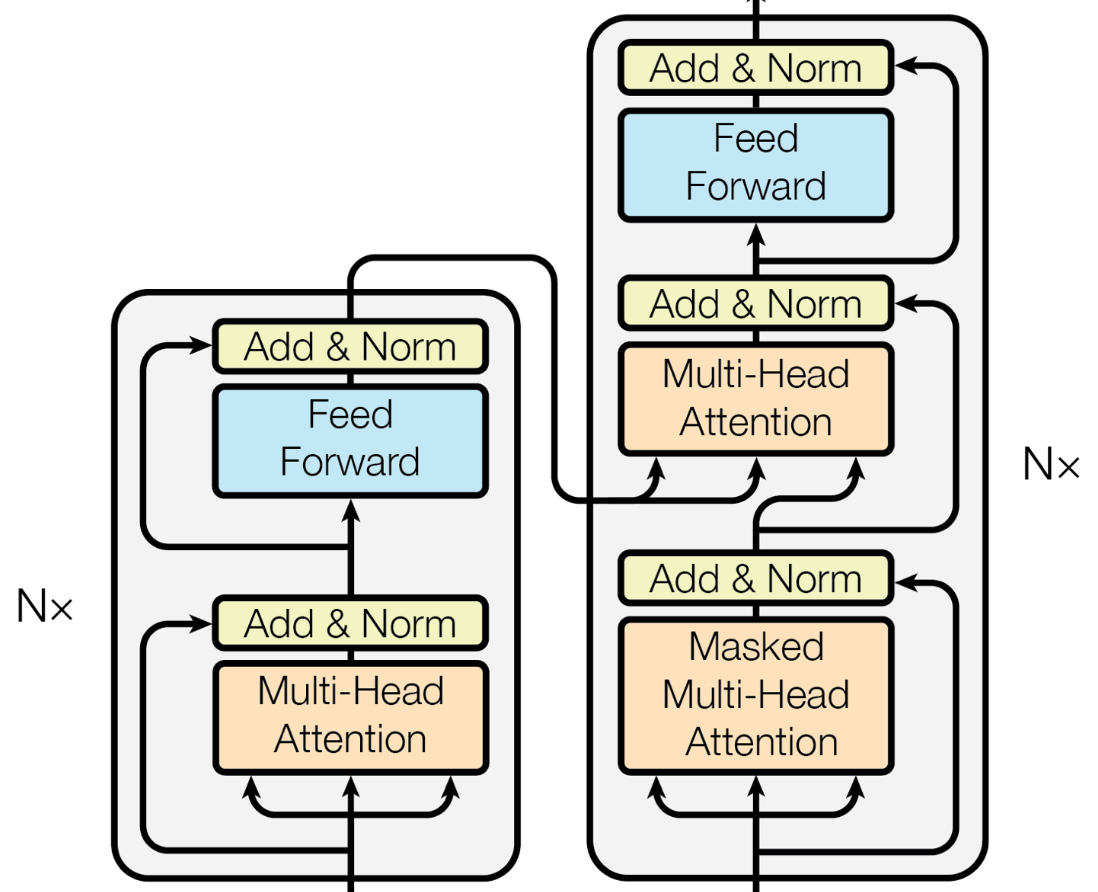
Decoder에는 Encoder의 마지막 블록에서 나온 소스 단어 벡터 시퀀스와 이전 디코더 블록의 수행 결과로 도출된 타깃 단어 벡터 시퀀스이다.
Masked Self Attention
기존의 Encoder-Decoder 구조의 모델들은 순차적으로 입력값을 전달받아 t+1 시점 예측을 위해 사용할 수 있는 데이터가 t 시점까지로 한정된다. 하지만 Transformer에서는 전체 입력값을 전달 받기 때문에 입력값을 예측할 때 미래의 시점의 입력값까지 참고하는 문제가 발생한다. 이러한 문제를 방지하기 위한 기법을 Look-ahead Mask 라고한다.
Look Ahead Mask
Attention Score의 (i, j)는 i번째 Query와 j번쨰 Key,Value 사이의 유사도다. 따라서 가 되면 i가 미래의 Attention 값을 보게 된다. 이를 막기 위해 의 계산을 강제할 수 있지만 이것보다 인 요소 (즉 Attention Score 행렬의 대각선 윗부분) 를 로 변경하고 Softmax로 취해서 Attention Weight을 0으로 만든다.
해당 매커니즘에서는 타깃 언어의 벡터 시퀀스를 계산 대상으로 한다.
Encoder의 Self Attention과 크게 다르지 않다.
Multi-Head Attention
Encoder의 단어 시퀀스와, Decoder의 단어 벡터 시퀀스를 각각 KEY, Query로 삼아 계산을 수행한다.
FFN, ADD, Norm
(1) Feed Forward Network
Multi-Head Attention의 출력은 입력 단어들에 대응하는 벡터 시퀀스이다. 벡터 각각을 FFN에 입력합니다. Activation은 ReLU를 이용합니다.
(2) Add : 잔차
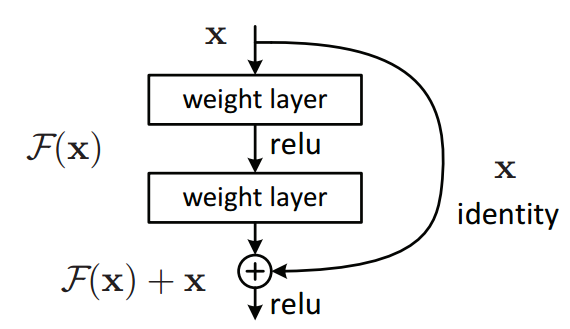
트랜스포머 블록의 Add잔차 Residual Connection을 가리킨다. 이를 통해서 블록 계산을 다양한 관점에서 수행할 수 있다.
(3) Norm : 레이어 정규화
Layer Normalization 는 미니 배치의 인스턴스()별로 평균을 빼주고 표준편차로 나누어 정규화를 수행하는 기법입니다.
이를 통해 학습이 안정되고 그 속도가 빨라지는 등의 효과가 있습니다.
HOW TO TRAIN
(1) Dropout
과적합을 방지하는 방법으로, 뉴런의 일부를 학률적으로 0으로 대치하여 계산에서 제외하는 방법이다.
(2) Adam Optimizer
Adam은 경사하강을 할떄 방향과 보폭을 적절하게 정해준다. 현재 위치에서 가장 경사가 급한 쪽으로 내려가되, 하강하던 관성을 일부 유지하도록한다. 보폭의 경우 안가본 곳은 큰 걸음으로 걸어 훑고, 많이 가본 곳은 갈수록 보폭을 줄여 세밀하게 탐색하는 방식으로 학습된다.
